Ник Бостром - Искусственный интеллект

- Название:Искусственный интеллект
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2015
- ISBN:9785000578100
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Ник Бостром - Искусственный интеллект краткое содержание
Искусственный интеллект - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Рассмотрим вначале обучение с подкреплением. Оптимальный ИИ, обучающийся с подкреплением (ИИ-ОП), максимизирует будущую ожидаемую награду. Тогда выполняется уравнение14:
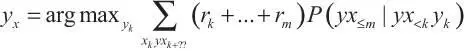
Последовательность подкреплений r k, …, r m вытекает из последовательности воспринимаемых состояний среды x k:m , поскольку награда, полученная агентом на каждом шаге, является частью восприятия, полученного на этом шаге.
Мы уже говорили, что такого рода обучение с подкреплением в нынешних условиях не подходит, поскольку агент с довольно высоким интеллектом поймет, что обеспечит себе максимальное вознаграждение, если сможет напрямую манипулировать сигналом системы наград (эффект самостимуляции). В случае слабых агентов это не будет проблемой, поскольку мы сможем физически предотвратить их манипуляции с каналом, по которому передаются вознаграждения. Мы можем также контролировать их среду, чтобы они получали вознаграждение только в том случае, если их действия согласуются с нашими ожиданиями. Но у любого агента, обучающегося с подкреплением, будут иметься серьезные стимулы избавиться от этой искусственной зависимости: когда его вознаграждения обусловлены нашими капризами и желаниями. То есть наши отношения с агентом, обучающимся с подкреплением, фундаментально антагонистичны. И если агент силен, это может быть опасно.
Варианты эффекта самостимуляции также могут возникнуть у систем, не стремящихся получить внешнее вознаграждение, то есть у таких, чьи цели предполагают достижение какого-то внутреннего состояния. Скажем, в случае систем «актор–критик», где модуль актора выбирает действия так, чтобы минимизировать недовольство отдельного модуля критика, который вычисляет, насколько соответствует поведение актора требуемым показателям эффективности. Проблема этой системы следующая: модуль актора может понять, что способен минимизировать недовольство критика, изменив или вовсе ликвидировав его — как диктатор, распускающий парламент и национализирующий прессу. В системах с ограниченными возможностями избежать этой проблемы можно просто: не дав модулю актора никаких инструментов для модификации модуля критика. Однако обладающий достаточным интеллектом и ресурсами модуль актора всегда сможет обеспечить себе доступ к модулю критика (который фактически представляет собой лишь физический вычислительный процесс в каком-то компьютере)15.
Прежде чем перейти к агенту, который проходит обучение ценностям, давайте в качестве промежуточного шага рассмотрим другую систему, максимизирующую полезность на основе наблюдений (ИИ-МНП). Она получается путем замены последовательности подкреплений ( r k + … + r m ) в ИИ-ОП на функцию полезности, которая может зависеть от всей истории будущих взаимодействий ИИ:
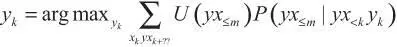
Эта формула позволяет обойти проблему самостимуляции, поскольку функцию полезности, зависящую от всей истории взаимодействий, можно разработать так, чтобы наказывать истории взаимодействия, в которых проявляются признаки самообмана (или нежелания агента прикладывать достаточные усилия, чтобы получить точную картину действительности).
Таким образом, ИИ-МНП дает возможность обойти проблему самостимуляции в принципе . Однако, чтобы ею воспользоваться, нужно задать подходящую функцию полезности на классе всех возможных историй взаимодействия — а это очень трудная задача.
Возможно, более естественным было бы задать функцию полезности непосредственно в терминах возможных миров (или свойств возможных миров, или теорий о мире), а не в терминах историй взаимодействия агента. Используя этот подход, формулу оптимальности ИИ-МНП можно переписать и упростить:
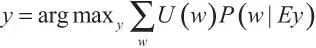
Здесь E — это все свидетельства, доступные агенту (в момент, когда он принимает решение), а U — функция полезности, которая присваивает полезность некоторому классу возможных миров. Оптимальный агент будет выбирать действия, которые максимизируют ожидаемую полезность.
Серьезная проблема этих формул — сложность задания функции полезности. И это наконец возвращает нас к проблеме загрузки ценностей. Чтобы функцию полезности можно было получить в процессе обучения, мы должны расширить наше формальное определение и допустить неопределенность функции полезности. Это можно сделать следующим образом (ИИ-ОЦ)16:
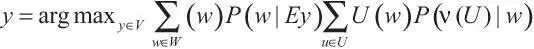
где v (—) — функция от функций полезности для предположений относительно функций полезности. v ( U ) — предположение, что функция полезности U удовлетворяет критерию ценности , выраженному v 17.
То есть чтобы решить, какое действие выполнять, нужно действовать следующим образом: во-первых, вычислить условную вероятность каждого возможного мира w (учитывая все возможные свидетельства и исходя из предположения, что должно быть выполнено действие y ); во-вторых, для каждой возможной функции U вычислить условную вероятность того, что U удовлетворяет критерию ценности v (при условии, что w — это реальный мир); в-третьих, для каждой возможной функции полезности U вычислить полезность возможного мира w ; в-четвертых, использовать все эти значения для расчета ожидаемой полезности действия y ; в-пятых, повторить эту процедуру для всех возможных действий и выполнить действие, имеющее самую высокую ожидаемую полезность (используя любой метод выбора из равных значений в случае возникновения таковых). Понятно, что таким образом описанная процедура — предполагающая явное рассмотрение всех возможных миров — вряд ли реализуема с точки зрения потребности в вычислительных ресурсах. ИИ придется использовать обходные пути, чтобы аппроксимировать это уравнение оптимальности.
Остается вопрос, как определить критерий ценности v 18. Если у ИИ появится адекватное представление этого критерия, он, в принципе, сможет использовать свой интеллект для сбора информации о том, какие из возможных миров с наибольшей вероятностью могут оказаться реальными. После чего применить критерий ценности для каждого потенциально реального мира, чтобы выяснить, какая целевая функция удовлетворяет критерию в мире w . То есть формулу ИИ-ОЦ можно считать одним из способов идентифицировать и выделить ключевую сложность в методе обучения ценностям — как представить v . Формальное описание задачи высвечивает также множество других сложностей (например, как определить Y , W и U ), с которыми придется справиться прежде, чем метод можно будет использовать19.
Читать дальшеИнтервал:
Закладка:








