Тимур Машнин - Введение в технологию Блокчейн

- Название:Введение в технологию Блокчейн
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:2021
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Тимур Машнин - Введение в технологию Блокчейн краткое содержание
Введение в технологию Блокчейн - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Тимур Машнин
Введение в технологию Блокчейн
Введение в криптографию и криптовалюты
Начнем мы свое обсуждение с криптографических хеш-функций. Мы поговорим о том, что они собой представляют, и каковы их свойства. А потом мы обсудим их приложения.
Итак, криптографическая хэш-функция является математической функцией. И она обладает рядом свойств.

Прежде всего, хеш-функция может принимать любую строку любого размера как входной параметр. И хеш-функция производит вывод строки фиксированного размера, мы будем использовать 256 бит, потому что это делает биткойн.
И хеш-функция должна быть эффективно вычисляемой, обрабатывая заданную строку за разумный промежуток времени.
Также хэш-функция должна быть криптографически безопасна.
В частности, функция не должна иметь коллизий или конфликтов, она должна иметь свойство скрытия, и она должна быть головоломкой.
Первое свойство, которое нам нужно иметь для криптографической хеш-функции это то, что она не содержит конфликтов.
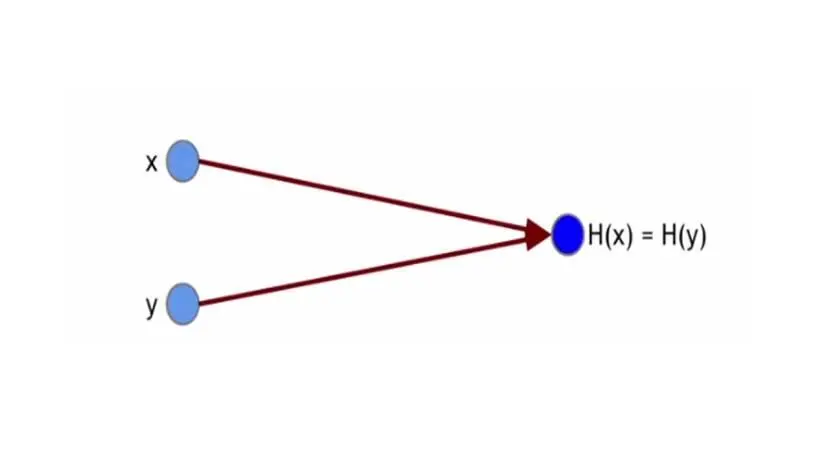
И это означает, что нельзя найти две разные строки с одинаковой хэш-функцией.
Теоретически коллизии существуют, так как на вход вы берете строку любой длины, а на выходе получаете строку 256 бит.
Вопрос в том, могут ли эти коллизии быть найденными обычными людьми, использующими обычные компьютеры?
С точки зрения вероятности, если взять 2 в 130 степени случайно выбранных входных строк, то с вероятностью 99.8 %, по крайней мере, две из них будут конфликтовать, независимо от используемой хэш функции.
Но, конечно, проблема в том, что вы должны вычислить хэш функцию 2 в 130 степени раз.
И это, конечно, астрономическое число.
Не существует хеш функции, для которой было бы доказано, что она свободна от конфликтов.
Просто эти конфликты трудно найти, и мы принимаем то, что мы используем хэш функцию, свободную от конфликтов.
Если мы можем предположить, что у нас есть хеш-функция, свободная от коллизий, тогда мы можем использовать результаты этой хэш-функции как дайджест сообщений.
И я имею в виду следующее.
Если мы знаем, что x и y имеют одинаковый хеш, тогда можно с уверенностью предположить, что x и y одинаковы. И это позволяет нам использовать хэши как своего рода дайджест сообщений.
Предположим, например, что у нас есть большой файл.
И мы хотели бы уметь распознавать, будет ли другой файл таким же, как этот файл.
Один из способов сделать это, это сохранить весь большой файл. И затем, когда мы получим другой файл, просто сравнить их.
Но поскольку у нас есть хэш функция и хэши файлов, которые, как мы считаем, свободны от конфликтов, более эффективно просто запомнить хэш исходного файла.
Затем, если кто-то показывает нам новый файл и утверждает, что это то же самое, мы можем вычислить хэш этого нового файла и сравнить хеши.
Если хеши одинаковы, мы делаем вывод, что файлы одинаковые.
И это дает нам очень эффективный способ запомнить то, что мы видели раньше, так как хэш невелик, это всего лишь 256 бит, в то время как исходный файл может быть очень большим.
Второе свойство, которое мы хотим от хэш-функции, состоит в том, что она является скрывающей.
Если у нас есть результат хэш-функции, тогда нет никакого способа определить, что из себя представляет вход хэш функции.
Это работает, когда вход хэш функции представляет собой огромный набор различных вариантов, так что нельзя простым перебором, вычисляя хэши, найти соответствие хэша и определенного входа.
Если же у нас набор входных значений небольшой, мы можем решить эту проблему с помощью соединения нашего входного значения со значением, которое было выбрано из очень большого набора значений.
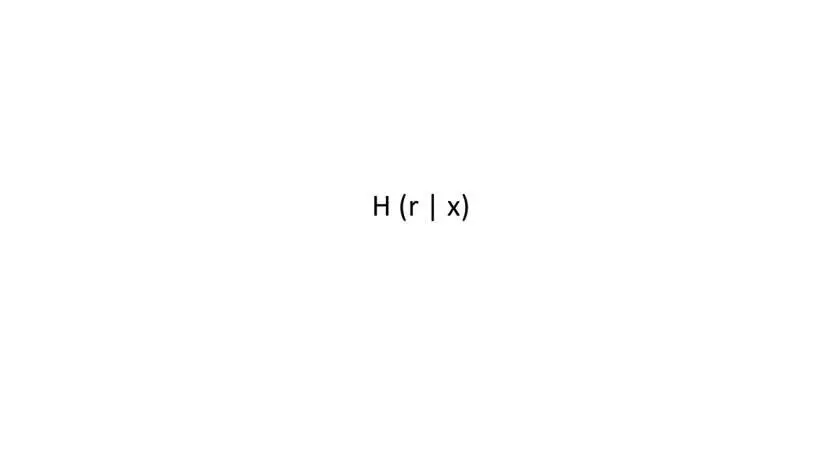
Таким образом, хэш функция H (r | x) означает взять все биты r и поместить после них все биты x.
Если r – случайное значение, выбранное из широкого распределения, то, учитывая H (r | x), невозможно найти x.
Таким образом хэш r соединенного с x, будет скрывать x.
Теперь давайте посмотрим на применение этого скрывающего свойства.
Предположим, что мы берем число, заворачиваем его в конверт, и помещаем его на стол, где каждый может увидеть конверт. Но пока вы не открыли конверт, это число является секретом.
Позже вы можете открыть конверт и выдать значение.
Мы хотим сделать это в цифровом смысле. Например, вы можете передать сообщение.
И эта передача выдаст два значения, com и key.
Подумайте о com как о конверте, который вы собираетесь положить на стол, и ключе как о секретном ключе для разблокировки конверта.
Затем вы позволяете кому-то проверять, учитывая com, key и сообщение, что этот конверт, ключ и сообщение действительно идут вместе.
И эта проверка вернет истину или ложь.
Мы помещаем сообщение в конверт и передаем сообщение.
И эта передача возвращает конверт и ключ, а затем мы публикуем конверт.
Позже, чтобы открыть конверт, мы должны опубликовать ключ.
И тогда кто-то может использовать этот конверт, ключ и сообщение, чтобы проверить валидность открытия конверта.
Таким образом невозможно будет подменить сообщение в конверте.

Чтобы реализовать эту схему, мы генерируем случайное значение 256 бит и назовем его ключом.
И тогда мы вернем хэш ключа, соединенного с сообщением.
Затем, кто-то может проверить целостность сообщения, вычислив хэш ключа и сообщения и сравнив это значение с переданным значением com.
сom – это хэш ключа, соединенного с msg.
И если есть этот хэш, по нему невозможно узнать само сообщение.
Это то самое свойство скрытия, о котором мы говорили раньше.
Ключ был выбран случайным 256-битным значением.

И поэтому свойство сокрытия означает, что, если мы возьмем сообщение, и поставим перед ним что-то, что было выбрано из очень большого распределения, как в данном случае случайное 256-битное значение, тогда невозможно найти сообщение, как исходя из самого хэша, так и простым перебором возможных сообщений.
Одновременно мы получаем и отсутствие конфликтов, используя такую схему.
Невозможно будет найти два разных сообщения с одинаковым таким хэшем.
Читать дальшеИнтервал:
Закладка: