Евгений Ющук - Интернет-разведка. Руководство к действию

- Название:Интернет-разведка. Руководство к действию
- Автор:
- Жанр:
- Издательство:Вершина
- Год:2007
- Город:М.:
- ISBN:5-9626-0290-0
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Евгений Ющук - Интернет-разведка. Руководство к действию краткое содержание
Согласно расхожему мнению, человек, владеющий информацией, владеет миром. Интернет – гигантская информационная база современности, и необходимость освоения тонкостей работы в сети скоро станет насущной для всех – от специалистов по конкурентной разведке, маркетингу и PR, в жизни которых Интернет уже играет не последнюю роль, до рядовых служащих.
Как найти в Интернете информацию о конкретных людях, компаниях и товарах? Как организовать продвижение собственного предприятия в Сети? Как уберечься от хакеров и спрятать информацию на своем компьютере от посторонних? Как бороться с вирусами и вредоносными программами? Ответы на эти и многие другие вопросы вы найдете в нашей книге – подробном путеводителе по миру Интернета. Представленные здесь практические советы помогут вам не просто выстоять в конкурентной или информационной борьбе, но и победить в ней, изучив неизвестные рядовому пользователю возможности Всемирной паутины.
Издание представляет практический интерес для специалистов по бизнес-разведке, маркетингу, рекламе и PR, а также для директоров и менеджеров, желающих эффективно продвигать свое предприятие на современном рынке.
Интернет-разведка. Руководство к действию - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Затем Бернерс-Ли придумал Universal Resource Identifier – метод стандартизации адресов, при котором компьютерам в Интернете присваиваются уникальные адреса (сегодня мы их называем URL, это то, что в привычном для пользователя виде обычно начинается с «www»). Наконец, изобретатель собрал вместе все эти элементы, создав систему в форме Web-серверов, которые хранят HTML-документы и предоставляют их другим компьютерам, создавая HTML-запросы о документах по определенным URL.
Но Бернерс-Ли хотел видеть Интернет как информационное пространство, в котором можно получить свободный доступ к данным любых типов. На ранних этапах развития глобальной Сети преобладали простые текстовые документы HTML. К тому времени существовали системы поиска информации на локальных машинах, поэтому появилось несколько серверов, которые пытались проиндексировать какую-то часть страниц Web и прежде, чем отправляться за чем-то в Интернет, предлагали поискать необходимые сведения на этих серверах.
При этом основная проблема заключалась в том, чтобы отыскать страницы, которые в принципе можно бы было индексировать. Поскольку Интернет лишен централизованной структуры и общего оглавления, единственный способ, позволявший добиться этого, состоял в поиске ссылки на страницу и переходе по этой ссылке, с последующим добавлением найденного ресурса к индексу.
Однако вскоре возникла еще одна проблема. Наиболее популярные страницы посещались пауками чаще остальных, так как на них указывало максимальное количество ссылок. Пауки, количество и возможности которых были ограничены, «зависали» на таких страницах и впустую расходовали ресурсы, оставляя непосещенным множество других адресов, пока еще менее популярных. Для решения этой проблемы требовалось создать программу, которая позволила бы игнорировать уже проиндексированные страницы и сосредоточиться на поиске новых. Иначе это грозило проблемой с ресурсами.
В 1993 г. студент-физик Массачусетского технологического института Мэтью Грей (Mathew Gray) создал первый широко известный Web-робот, названный «World Wide Web Wanderer» или просто «Вандерер», что в переводе с английского означает «скиталец» или «странник». Дело в том, что Грей заинтересовался статистикой. Результатом такого увлечения стало появление «странника»: изобретение было призвано помочь студенту проанализировать размеры Интернета и скорость его роста. «Вандерер» просто приходил на страницу и определял сам факт ее существования, не занося в базу содержимого найденного адреса. Несмотря на то, что создатель робота не преследовал никаких других целей, его детище, фактически дебютировавшее в «забеге» прогрессивных интернет-находок, легло в основу более сложных программ, которые к умению «скитальца» перемещаться по Сети добавили способность сохранять содержимое страниц в базе данных после их посещения.
Случилось так, что 1994 г. стал переломным в истории создания поисковых машин. Студент выпускного курса Вашингтонского университета Брайан Пинкертон (Brian Pinkerton) устал от бесконечной череды электронных писем, которые посылали ему друзья, с информацией о хороших сайтах, найденных ими в Интернете. Безусловно, сайты ему были нужны, однако шквал посланий с их адресами раздражал, а посещение всех страниц отнимало уйму времени. Однако Пинкертон нашел решение проблемы – он создал робота, которого назвал WebCrawler (что-то вроде «вездеход для Интернета»). «ВебКраулер», как и «Вандерер», ползал со страницы на страницу, запоминая при этом весь текст Web-документа и сохраняя его в базе данных, которая была доступна поисковым словам. Изобретатель представил свое детище публике в апреле 1994 г., причем сделал это виртуально – через Web-интерфейс. База данных в тот момент содержала информацию с 6000 самых разных серверов. Уже через неделю она начала расширяться, причем ежедневный прирост составлял более 100 новых серверов. Так родилась первая поисковая машина.
Тогда же был введен в обиход интернетчиков термин «краулер» или «паук», который применяется, как мы уже говорили, и по сей день.
Ну а далее ситуация развивалась еще более стремительно. Крис Шерман и Гари Прайс приводят такую хронологию возникновения и развития современных поисковых машин.
1994 г. – WebCrawler, Lycos, Yahoo!
1995 г. – Infoseek, SavvySearch, AltaVista, MetCrawler, Excite. Появление метапоисковых машин.
1996 г. – HotBot, LookSmart.
1997 г. – NorthernLight.
1998 г. – Google, InvisibleWeb.com.
1999 г. – FAST.
2000 г. и далее – Сотни новых поисковых машин.
Русскоязычные поисковые машины появлялись в такой последовательности:
1996 г. – Rambler ( www.rambler.ru);
1997 г. – Yandex ( www.yandex.ru);
2004 г. – русскоязычная версия Google ( www.google.ru) и русскоязычная версия Yahoo! ( http://ru.yahoo.com).
Из чего состоит сайт
Прежде, чем перейти к описанию языка запросов поисковых машин, рассмотрим, из каких элементов, с которыми предстоит работать пауку, состоит обычно сайт.
Надо сказать, что язык HTML достаточно прост и логичен. Он представляет собой способ разбивки текста с помощью специальных элементов – тегов, которые определяют структуру и внешний вид текста при просмотре его в браузере. О тегах следует знать, что они всегда парные и что они бывают открывающими (обозначают начало определенного форматирования) и закрывающими (обозначают его окончание). Закрывающий тег – такой же по написанию, как открывающий, но перед ним стоит косая черта.
Приведем пример очень простого сайта (рис. 1).
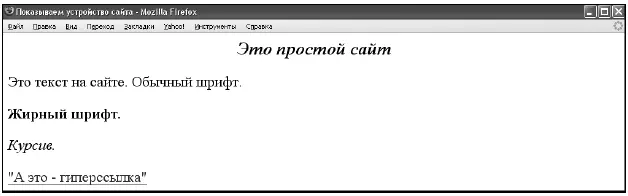
Рис. 1. Пример сайта, как его видно в браузере Мозилла Файрфокс.
Наверху страницы, изображенной на рисунке, то есть не в тексте сайта, а на верхнем поле рамки страницы, рядом с круглым значком браузера, расположена надпись: «Показываем устройство сайта». Она находится в так называемом заголовке страницы (который заключен между открывающим тегом ). Обращаем ваше внимание на то, что это заголовок именно всей страницы, а не текста.
Посередине представленного рисунка жирным курсивом выведено: «Это простой сайт». Данная надпись – и есть заголовок текста. Шрифт фразы «Это простой сайт» по размеру превосходит шрифт текста на сайте, он специально выделен как заголовок текста. При разметке с помощью HTML этот текст расположен ниже тега находится внутри тега
. То есть содержимое, заключенное в , – это часть того, что находится в . Такое расположение дает дополнительную возможность пауку лучше определять ключевые слова на сайте. Ведь если слова вынесены в заголовок текста или, тем более, всей страницы, вероятность того, что страница и текст посвящены теме, формулируемой этими словами, повышается.Ниже фразы «Это простой сайт» приведены четыре варианта написания основного текста сайта:
Читать дальшеИнтервал:
Закладка:









