Журнал Компьютерра - Журнал «Компьютерра» №37

- Название:Журнал «Компьютерра» №37
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Журнал Компьютерра - Журнал «Компьютерра» №37 краткое содержание
Журнал «Компьютерра» №37 - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Устройство процессоров AMD архитектуры K8
Архитектура K8 используется во всех современных серверных, десктопных и мобильных процессорах AMD (Opteron, Sempron, Athlon 64 и Athlon 64 X2). Эффективная длина конвейера[Время в тактах от начала исполнения инструкции до момента, когда результаты выполнения будут записаны в оперативную память] варьируется от 10-12 стадий (для целочисленных, логических вычислений и обращений к оперативной памяти) до 17 стадий (вычисления с плавающей точкой). Количество одновременно исполняемых инструкций за такт в устоявшемся режиме - до трех; тактовые частоты серийно выпускаемых процессоров - от 1,6 до 2,8 ГГц.
Об особенностях организации архитектуры K8, связанных с интегрированным контроллером памяти, линками HyperTransport и неоднородной моделью памяти SUMa мы подробно писали в статье про двухъядерные процессоры; в остальном же - перед нами вполне классический процессор Гарвардской архитектуры. Объем кэшей L1 D-cache (для данных) и L1 I-cache (для кода) - фиксирован и составляет по 64 Кбайт; имеется общий эксклюзивный[Эксклюзивным называется кэш, в котором данные, хранящиеся в кэш-памяти первого уровня, не обязательно должны быть продублированы в кэшах нижележащих уровней. Инклюзивный кэш - когда любая информация, хранящаяся в кэшах высших уровней, дублируется в кэш-памяти нижележащих] кэш второго уровня объемом от 128 до 1024 Кбайт; кэш третьего и более низких уровней не предусмотрен, но в рамках протокола MOESI процессоры в многопроцессорных системах могут обращаться к кэш-памяти других процессоров.
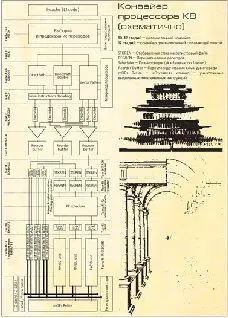
Исполнение инструкций на конвейере K8, как и положено, начинается с блока выборки инструкций. За один такт блок выбирает из кэша 16 байт данных и выделяет из них от одной до трех инструкций x86 - сколько в выбранных данных поместилось[Поскольку средняя длина инструкции x86 составляет 5-6 байт, то, как правило, блоку удается выбрать три инструкции за такт]. Чтобы облегчить процесс декодирования, инструкции, хранящиеся в кэшах L1, тегированы - в линейках кэша сохраняется информация о том, как внутри этой линейки распределены инструкции x86. Попутно с помощью блока предсказания переходов в этом же такте определяется адрес блока, с которого начнется выборка в следующем такте. Тегирование производится при выборке данных из кэша L2 в кэш L1 I-cache; при вытеснении данных из L1 в L2 теги сохраняются.
На втором такте работы конвейера свежевыбранные одна-три инструкции x86 распределяются по трем блокам декодирования инструкций. Самые сложные инструкции, требующие декодирования с использованием микрокода процессора, отправляются в декодер VectorPath. Более простые - в декодеры DirectPath: те, что попроще, - в обычный, те, что посложнее, - в сдвоенный DirectPath Double. Начиная с этого момента процессор «забывает» о существовании x86 и переключается на работу с внутренними микроинструкциями (mOP).
Весь дальнейший конвейер строится на том, что работа с mOP’ами происходит тройками инструкций (AMD называет их линиями, line). С логической точки зрения конвейер K8 строится таким образом, что обрабатывает именно линии, а не x86-инструкции или отдельные микрооперации. При этом в одной линии может быть меньше трех микроопераций - тогда «недосдачу» в тройке заполняют специальные пустые операции (null-mOP). При этом со «сложными» vector-инструкциями все элементарно - VectorPath-декодер подставляет на их место прошитые в микрокоде процессора линии; а вот декодирование «простых» инструкций выливается в сложный процесс превращения x86-инструкции в один (DirectPath) или два (DirectPath Double) mOP’а, которые потом перетасовываются и упаковываются в одну линию специальным упаковщиком[В этом упаковщике, который, в частности, научился эффективно управляться с разбивающимися на два mOP’а инструкциями SSE, и скрыто важнейшее усовершенствование конвейера K8 по сравнению с конвейером K7 (процессоры Athlon/Athlon XP). Изменение декодера (и значительное увеличение времени на декодирование), усовершенствование планировщика инструкций - казалось бы, мелочи, но эффект огромный. Кстати, отсюда следует, что конвейер K8 практически не оптимизировался для достижения высоких тактовых частот - неудивительно, что на старом 130-нм технологическом процессе он и не показал существенно более высоких тактовых частот, нежели старичок K7]. На весь процесс в нормальных условиях уходит пять тактов конвейера.
Сгенерированные линии от VectorPath- и DirectPath-декодеров по одной за такт поступают в специальное устройство - Instructions Control Unit (ICU), где подготовленные к исполнению линии накапливаются в специальной очереди (24 линии). О том, что происходит дальше, поясним с помощью аналогии.
Предположим, что наша программа - это книжка, в которой записано, как процессору нужно обрабатывать данные. Что делает процессор? Упоминавшийся блок выборки вырывает из книжки страничку с текстом (будем считать, что странички достаточно маленькие) и выбирает из нее от одной до трех содержательных частей, которые передает декодеру. Декодер читает выделенные фрагменты текста и конвертирует их в четкие инструкции, указывающие, что и в какой последовательности нужно сделать. Инструкции (по одной) он записывает на бумажках (mOP’ах) и упаковывает в конверты - до трех бумажек в один конверт (линию). Конверты поступают в специальную картотеку - ICU, где их вскрывает и прочитывает специальный человек.
Что дальше? Претендентов на декодированные инструкции два - блок целочисленных вычислений (ALU) и блок вычислений с плавающей точкой (FPU). Когда блоки готовы принять очередную инструкцию, они сообщают об этом человеку в картотеке; человек копается в своих конвертах и выбирает из них в произвольном порядке, как ему удобнее, до трех бумажек-инструкций, которые и раздает ALU и FPU. Единственное ограничение, которое при этом накладывается, - человек никогда не передает ALU и FPU те инструкции, выполнение которых зависит от еще не переданных. Блоки ALU/FPU каким-то хитрым образом выполняют полученные инструкции, но результаты отсылают не во «внешний мир», а в нашу картотеку-ICU, где их кладут в тот же самый конверт, в котором лежали инструкции. Даже если происходит ошибка выполнения, процессор не сообщает о ней сразу, а сперва записывает информацию об ошибке на конверте; когда настанет пора вскрыть конверт - вот тогда он про нее и сообщит. Чтобы потом эти данные использовать - применяется довольно хитрая техника (та самая, из сноски 4), позволяющая вновь выполняемым инструкциям обращаться к еще «официально несуществующим» данным. Когда для конверта все инструкции оказываются выполненными, а конверт стоит первым в очереди и больше не содержит инструкций, но лишь результаты их исполнения - то полученные результаты «объявляются официальными», а конверт выбрасывается (отставка линий). Иногда, если при вскрытии очередного конверта выясняется, что ранее была допущена ошибка при предсказании условного перехода или при выполнении содержащейся в конверте инструкции, дело до этого и не доходит - конвейер приходится «сбрасывать», то есть смотреть на последнем конверте адрес того самого неудачного перехода, выкидывать всю накопленную к текущему моменту картотеку со всеми ее результатами и начинать выполнение с того самого места, где произошло неверное предсказание перехода. Благодаря тому, что результаты выброшенных конвертов еще не были «объявлены официальными», а «рвем» мы конверты строго в той же очередности, в которой они к нам в очередь поступали - допущенная ошибка «никому не станет известна» - результаты выполнившихся «вперед батьки» инструкций автоматически будут аннулированы.
Читать дальшеИнтервал:
Закладка:









