Нейл Мэтью - Основы программирования в Linux

- Название:Основы программирования в Linux
- Автор:
- Жанр:
- Издательство:«БХВ-Петербург»
- Год:2009
- Город:Санкт-Петербург
- ISBN:978-5-9775-0289-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нейл Мэтью - Основы программирования в Linux краткое содержание
В четвертом издании популярного руководства даны основы программирования в операционной системе Linux. Рассмотрены: использование библиотек C/C++ и стандартных средств разработки, организация системных вызовов, файловый ввод/вывод, взаимодействие процессов, программирование средствами командной оболочки, создание графических пользовательских интерфейсов с помощью инструментальных средств GTK+ или Qt, применение сокетов и др. Описана компиляция программ, их компоновка c библиотеками и работа с терминальным вводом/выводом. Даны приемы написания приложений в средах GNOME® и KDE®, хранения данных с использованием СУБД MySQL® и отладки программ. Книга хорошо структурирована, что делает обучение легким и быстрым.
Для начинающих Linux-программистов
Основы программирования в Linux - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Утилиты, обсуждавшиеся в этой главе, в основном хранятся на FTP-серверах в Интернете. Авторы, имеющие к ним отношение, могут порой сохранять авторские права на них. Информацию о многих утилитах можно найти в архиве Linux, по адресу http://www.ibiblio.org/pub/Linux.Мы надеемся, что новые версии будут появляться на этом Web-сайте по мере их выхода в свет.
Глава 11
Процессы и сигналы
Процессы и сигналы формируют главную часть операционной среды Linux. Они управляют почти всеми видами деятельности ОС Linux и UNIX-подобных компьютерных систем. Понимание того, как Linux и UNIX управляют процессами, сослужит добрую службу системным и прикладным программистам или системным администраторам.
В этой главе вы узнаете, как обрабатываются процессы в рабочей среде Linux и как точно установить, что делает компьютер в любой заданный момент времени. Вы также увидите, как запускать и останавливать другие процессы в ваших собственных программах, как заставить процессы отправлять и получать сообщения и как избежать процессов-зомби. В частности, вы узнаете о:
□ структуре процесса, его типе и планировании;
□ разных способах запуска новых процессов;
□ порождающих (родительских), порожденных (дочерних) процессах и процессах-зомби;
□ сигналах и их применении.
Что такое процесс?
Стандарты UNIX, а именно IEEE Std 1003.1, 2004 Edition, определяют процесс как "адресное пространство с одним или несколькими потоками, выполняющимися в нем, и системные ресурсы, необходимые этим потокам. Мы будем рассматривать потоки в главе 12, а пока будем считать процессом просто любую выполняющуюся программу.
Многозадачные системы, такие как Linux, позволяют многим программам выполняться одновременно. Каждый экземпляр выполняющейся программы создает процесс. Это особенно заметно в оконной системе, например Window System (часто называемой просто X). Как и ОС Windows, X предоставляет графический пользовательский интерфейс, позволяющий многим приложениям выполняться одновременно. Каждое приложение может отображаться в одном или нескольких окнах.
Будучи многопользовательской системой, Linux разрешает многим пользователям одновременно обращаться к системе. Каждый пользователь в одно и то же время может запускать много программ или даже несколько экземпляров одной и той же программы. Сама система выполняет в это время другие программы, управляющие системными ресурсами и контролирующие доступ пользователей.
Как вы видели в главе 4 , выполняющаяся программа или процесс состоит из программного кода, данных, переменных (занимающих системную память), открытых файлов (файловых дескрипторов) и окружения. Обычно в системе Linux процессы совместно используют код и системные библиотеки, так что в любой момент времени в памяти находится только одна копия программного кода.
Структура процесса
Давайте посмотрим, как организовано сосуществование двух процессов в операционной системе. Если два пользователя neil и rick запускают в одно и то же время программу grep для поиска разных строк в различных файлах, применяемые для этого процессы могут выглядеть так, как показано на рис. 11.1.
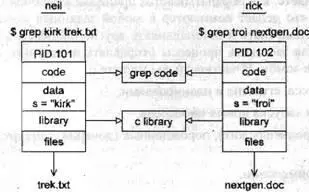
Рис. 11.1
Если вы сможете выполнить команду ps, как в приведенном далее коде, достаточно быстро и до того, как завершатся поиски строк, вывод будет выглядеть подобно следующим строкам:
$ ps -ef
UID PID PPID С STIME TTY TIME CMD
rick 101 96 0 18:24 tty2 00:00:00 grep troi nextgen.doc
neil 102 92 0 18:24 tty4 00:00:00 grep kirk trek.txt
Каждому процессу выделяется уникальный номер, именуемый идентификатором процесса или PID. Обычно это положительное целое в диапазоне от 2 до 32 768. Когда процесс стартует, в последовательности выбирается следующее неиспользованное число. Когда все номера будут исчерпаны, выбор опять начнется с 2. Номер 1 обычно зарезервирован для специального процесса init, который управляет другими процессами. Мы скоро вернемся к процессу init. А пока вы видите, что двум процессам, запущенным пользователями neil и rick, выделены идентификаторы 101 и 102.
Код программы, которая будет выполняться командой grep, хранится в файле на диске. Обычно процесс Linux не может писать в область памяти, применяемую для хранения кода программы, поэтому программный код загружается в память как доступный только для чтения. На рис. 11.1 видно, что несмотря на то, что в данную область нельзя писать, она может безопасно использоваться совместно.
Системные библиотеки также можно совместно использовать. Следовательно, в памяти нужна, например, только одна копия функции printf, даже если многие выполняющиеся программы вызывают ее. Эта схема более сложная, но аналогичная той, которую используют для работы динамически подключаемые библиотеки в ОС Windows.
Как видно из приведенной схемы, дополнительное преимущество заключается в том, что дисковый файл, содержащий исполняемую программу grep, меньше, т.к. не включает программный код совместно используемой библиотеки. Возможно, для одной программы это не слишком ощутимый выигрыш, но извлечение часто используемых подпрограмм, к примеру, из стандартной библиотеки С экономит значительный объем для операционной системы в целом.
Конечно не все, что нужно программе, может быть совместно использовано. Например, переменные отдельно используются каждым процессом. В данном примере искомая строка, передаваемая команде grep, — это переменная s, принадлежащая пространству данных каждого процесса. Эти пространства разделены и, как правило, не могут читаться другим процессом. Файлы, которые применяются в двух командах grep, тоже разные; у каждого процесса есть свой набор файловых дескрипторов, используемых для доступа к файлам.
Кроме того, у каждого процесса есть собственный стек, применяемый для локальных переменных в функциях и для управления вызовами функций и возвратом из них. У процесса также собственное окружение, содержащее переменные окружения, которые могут задаваться только для применения в данном процессе, например, с помощью функций putenvи getenv, как было показано в главе 4. Процесс должен поддерживать собственный счетчик программы, запись того места, до которого он добрался за время выполнения, или поток исполнения. В следующей главе вы увидите, что процессы могут иметь несколько потоков исполнения.
Во многих системах Linux и некоторых системах UNIX существует специальный набор "файлов" в каталоге /proc. Это скорее специальные, чем истинные файлы, т.к. позволяют "заглянуть внутрь" процессов во время их выполнения, как если бы они были файлами в каталогах, В главе 3 мы приводили краткий обзор файловой системы /proc.
Читать дальшеИнтервал:
Закладка:

