Нейл Мэтью - Основы программирования в Linux

- Название:Основы программирования в Linux
- Автор:
- Жанр:
- Издательство:«БХВ-Петербург»
- Год:2009
- Город:Санкт-Петербург
- ISBN:978-5-9775-0289-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нейл Мэтью - Основы программирования в Linux краткое содержание
В четвертом издании популярного руководства даны основы программирования в операционной системе Linux. Рассмотрены: использование библиотек C/C++ и стандартных средств разработки, организация системных вызовов, файловый ввод/вывод, взаимодействие процессов, программирование средствами командной оболочки, создание графических пользовательских интерфейсов с помощью инструментальных средств GTK+ или Qt, применение сокетов и др. Описана компиляция программ, их компоновка c библиотеками и работа с терминальным вводом/выводом. Даны приемы написания приложений в средах GNOME® и KDE®, хранения данных с использованием СУБД MySQL® и отладки программ. Книга хорошо структурирована, что делает обучение легким и быстрым.
Для начинающих Linux-программистов
Основы программирования в Linux - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
}
exit(EXIT_SUCCESS);
}
После выполнения этой программы вы получите вывод, аналогичный предыдущему:
$ ./pipe2
Wrote 3 bytes
Read 3 bytes: 123
Вы можете столкнуться с повторным выводом строки приглашения для ввода команды перед завершающим фрагментом вывода, поскольку родительский процесс завершится раньше дочернего, поэтому мы подчистили вывод, чтобы его легче было читать.
Как это работает
Сначала программа создает канал с помощью вызова pipe. Далее она применяет вызов forkдля создания нового процесса. Если forkзавершился успешно, родительский процесс пишет данные в канал, в то время как дочерний считывает данные из канала. Оба процесса, и родительский, и дочерний, завершаются после одного вызова writeи read. Если родительский процесс завершается раньше дочернего, вы можете увидеть между двумя выводами строку приглашения командной оболочки.
Несмотря на то, что программа внешне похожа на первый пример pipe, мы сделали большой шаг вперед, получив возможность использовать разные процессы для чтения и записи (рис. 13.2).
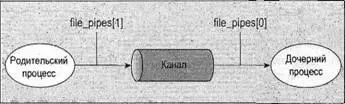
Рис. 13.2
Родительский и дочерний процессы
Следующий логический шаг в нашем изучении вызова pipe— разрешить дочернему процессу быть другой программой, отличной от своего родителя, а не просто другим процессом, выполняющим ту же самую программу. Сделать это можно с помощью вызова exec. Единственная сложность заключается в том, что новому процессу, созданному exec, нужно знать, какой файловый дескриптор применять для доступа. В предыдущем примере этой проблемы не возникло, потому что дочерний процесс обращался к своей копии данных file_pipes. После вызова execвозникает другая ситуация, поскольку старый процесс заменен новым дочерним процессом. Эту проблему можно обойти, если передать файловый дескриптор (который, в конце концов, просто число) как параметр программе, вновь созданной с помощью вызова exec.
Для того чтобы посмотреть, как это работает, вам понадобятся две программы (упражнение 13.7). Первая — поставщик данных. Она создает канал и затем вызывает дочерний процесс, потребитель данных.
exec1. Для получения первой программы исправьте pipe2.c, превратив ее в pipe3.c. Измененные строки затенены.
#include
#include
#include
#include
int main() {
int data_processed;
int file_pipes[2];
const char somedata[] = "123";
char buffer[BUFSIZ + 1];
pid_t fork_result;
memset(buffer, '\0', sizeof(buffer));
if (pipe(file_pipes) == 0) {
fork_result = fork();
if (fork_result == (pid_t)-1) {
fprintf(stderr, "Fork failure");
exit(EXIT_FAILURE);
}
if (fork_result == 0) {
sprintf(buffer, "%d", file_pipes[0]);
(void)execl("pipe4", "pipe4", buffer, (char*)0);
exit(EXIT_FAILURE);
} else {
data_processed = write(file_pipes[1], some_data, strlen(some_data));
printf ("%d - wrote %d bytes\n", getpid(), data_processed);
}
}
exit(EXIT_SUCCESS);
}
2. Программа-потребитель pipe4.c, читающая данные, гораздо проще:
#include
#include
#include
#include
int main(int argc, char *argv[]) {
int data_processed;
char buffer[BUFSIZ + 1];
int file_descriptor;
memset(buffer, '\0', sizeof(buffer));
sscanf(argv[1], "%d", &file_descriptor);
data_processed = read(file_descriptor, buffer, BUFSIZ);
printf("%d — read %d bytes: %s\n", getpid(), data_processed,
buffer);
exit(EXIT_SUCCESS);
}
Выполнив pipe3 и помня о том, что она вызывает программу pipe4, вы получите вывод, аналогичный приведенному далее:
$ ./pipe3
22460 - wrote 3 bytes
22461 - read 3 bytes: 123
Как это работает
Программа pipe3 начинается как предыдущий пример, используя вызов pipeдля создания канала и затем вызов forkдля создания нового процесса. Далее она применяет функцию sprintfдля сохранения в буфере номера файлового дескриптора чтения из канала, который формирует аргумент программы pipe4.
Вызов execlприменен для вызова программы pipe4. В нем использованы следующие аргументы:
□ вызванная программа;
□ argv[0], принимающий имя программы;
□ argv[1], содержащий номер файлового дескриптора, из которого программа должна читать;
□ (char *)0, завершающий список параметров.
Программа pipe4 извлекает номер файлового дескриптора из строки аргументов и затем читает из него данные.
Чтение закрытых каналов
Прежде чем двигаться дальше, необходимо более внимательно рассмотреть файловые дескрипторы, которые открыты. До этого момента вы разрешали читающему процессу просто читать какие-то данные и завершаться, полагая, что ОС Linux уберет файлы в ходе завершения процесса.
В большинстве программ, читающих данные из стандартного ввода, это делается несколько иначе, чем в виденных вами до сих пор примерах. Обычно программы не знают, сколько данных они должны считать, поэтому они, как правило, выполняют цикл — чтение данных, их обработка и затем снова чтение данных и так до тех пор, пока не останется данных для чтения.
Вызов readобычно будет задерживать выполнение процесса, т.е. он заставит процесс ждать до тех пор, пока не появятся данные. Если другой конец канала был закрыт, следовательно, нет ни одного процесса, имеющего канал для записи, и вызов readблокируется. Поскольку это не очень полезно, вызов read, пытающийся читать из канала, не открытого для записи, возвращает 0 вместо блокирования. Это позволит читающему процессу обнаружить канальный эквивалент метки "конец файла" и действовать соответствующим образом. Учтите, что это не то же самое, что чтение некорректного дескриптора файла, которое вызов read считает ошибкой и обозначает возвратом -1.
Если вы применяете канал с вызовом fork, есть два файловых дескриптора, которые можно использовать для записи в канал: один в родительском, а другой в дочернем процессах. Вы должны закрыть файловые дескрипторы записи в канал в обоих этих процессах, прежде чем канал будет считаться закрытым и вызов readдля чтения из канала завершится аварийно. Мы рассмотрим пример этого позже, когда вернемся к данной теме, для того чтобы подробно обсудить флаг O_NONBLOCKи каналы FIFO.
Интервал:
Закладка:

