Андрей Робачевский - Операционная система UNIX

- Название:Операционная система UNIX
- Автор:
- Жанр:
- Издательство:BHV - Санкт-Петербург
- Год:1997
- Город:Санкт-Петербург
- ISBN:5-7791-0057-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Андрей Робачевский - Операционная система UNIX краткое содержание
Книга посвящена семейству операционных систем UNIX и содержит информацию о принципах организации, идеологии и архитектуре, объединяющих различные версии этой операционной системы.
В книге рассматриваются: архитектура ядра UNIX (подсистемы ввода/вывода, управления памятью и процессами, а также файловая подсистема), программный интерфейс UNIX (системные вызовы и основные библиотечные функции), пользовательская среда (командный интерпретатор shell, основные команды и утилиты) и сетевая поддержка в UNIX (протоколов семейства TCP/IP, архитектура сетевой подсистемы, программные интерфейсы сокетов и TLI).
Для широкого круга пользователей
Операционная система UNIX - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Вы уже знаете, что каждый процесс характеризуется набором атрибутов и идентификаторов, позволяющих системе управлять его работой. Важнейшими из них являются идентификатор процесса PID и идентификатор родительского процесса PPID. PID является именем процесса в операционной системе, по которому мы можем адресовать его, например, при отправлении сигнала. PPID указывает на родственные отношения между процессами, которые (как и в жизни) в значительной степени определяют его свойства и возможности.
Однако нельзя не отметить еще четыре идентификатора, играющие решающую роль при доступе к системным ресурсам: идентификатор пользователя UID, эффективный идентификатор пользователя EUID, идентификатор группы GID и эффективный идентификатор группы EGID. Эти идентификаторы определяют права процесса в файловой системе, и как следствие, в операционной системе в целом. Запуская различные команды и утилиты, можно заметить, что порожденные этими командами процессы полностью отражают права пользователя UNIX. Причина проста — все процессы, которые запускаются, имеют идентификатор пользователя и идентификатор группы. Исключение составляют процессы с установленными флагами SUID и SGID.
При регистрации пользователя в системе утилита login(1) запускает командный интерпретатор, — login shell, имя которого является одним из атрибутов пользователя. При этом идентификаторам UID (EUID) и GID (EGID) процесса shell присваиваются значения, полученные из записи пользователя в файле паролей /etc/passwd. Таким образом, командный интерпретатор обладает правами, определенными для данного пользователя.
При запуске программы командный интерпретатор порождает процесс, который наследует все четыре идентификатора и, следовательно, имеет те же права, что и shell. Поскольку в конкретном сеансе работы пользователя в системе прародителем всех процессов является login shell, то и их пользовательские идентификаторы будут идентичны.
Казалось бы, эту стройную систему могут "испортить" утилиты с установленными флагами SUID и SGID. Но не стоит волноваться — как правило, такие программы не позволяют порождать другие процессы, в противном случае, эти утилиты необходимо немедленно уничтожить!
На рис. 2.10. показан процесс наследования пользовательских идентификаторов в рамках одного сеанса работы.
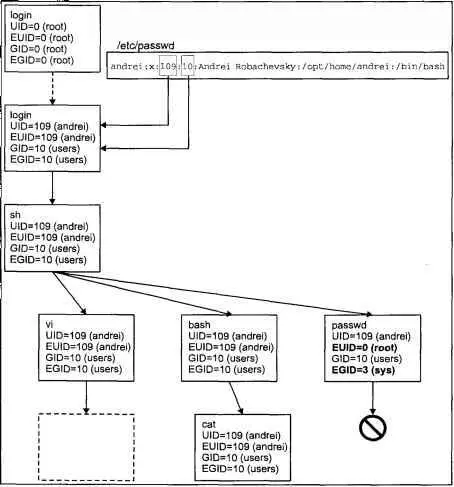
Рис. 2.10. Наследование пользовательских идентификаторов
Для получения значений идентификаторов процесса используются следующие системные вызовы:
#include
#include
uid_t getuid(void);
uid_t geteuid(void);
gid_t getgid(void);
gid_t getegid(void);
Эти функции возвращают для сделавшего вызов процесса соответственно реальный и эффективный идентификаторы пользователя и реальный и эффективный идентификаторы группы.
Процесс также может изменить значения этих идентификаторов с помощью системных вызовов:
#include
#include
int setuid(uid_t uid);
int setegid(gid_t egid);
int seteuid(uid_t euid);
int setgid(gid_t gid);
Системные вызовы setuid(2) и setgid(2) устанавливают сразу реальный и эффективный идентификаторы, а системные вызовы seteuid(2) и setegid(2) — только эффективные.
Ниже приведен фрагмент программы login(1) , изменяющей идентификаторы процесса на значения, полученные из записи файла паролей. В стандартной библиотеке имеется ряд функций работы с записями файла паролей, каждая из которых описывается структурой passwd, определенной в файле . Поля этой структуры приведены в табл. 2.17.
Таблица 2.17. Поля структуры passwd
| Поле | Значение |
|---|---|
char *pw_name |
Имя пользователя |
char *pw_passwd |
Строка, содержащая пароль в зашифрованном виде; из соображения безопасности в большинстве систем пароль хранится в файле /etc/shadow, а это поле не используется |
uid_t pw_uid |
Идентификатор пользователя |
gid_t pw_gid |
Идентификатор группы |
char *pw_gecos |
Комментарий (поле GECOS), обычно реальное имя пользователя и дополнительная информация |
char *pw_dir |
Домашний каталог пользователя |
char *pw_shell |
Командный интерпретатор |
Функция, которая потребуется для нашего примера, позволяет получить запись файла паролей по имени пользователя. Она имеет следующий вид:
#include
struct passwd *getpwnam(const char *name);
Итак, перейдем к фрагменту программы:
...
struct passwd *pw;
char logname[MAXNAME];
/* Массив аргументов при запуске
командного интерпретатора */
char *arg[MAXARG];
/* Окружение командного интерпретатора */
char *envir[MAXENV];
...
/* Проведем поиск записи пользователя с именем logname,
которое было введено на приглашение "login:" */
pw = getpwnam(logname);
/* Если пользователь с таким именем не найден, повторить
приглашение */
if (pw == 0)
retry();
/* В противном случае установим идентификаторы процесса
равными значениям, полученным из файла паролей и запустим
командный интерпретатор */
else {
setuid(pw->pw_uid);
setgid(pw->pw_gid);
execve(pw->pw_shell, arg, envir);
}
...
Вызов execve(2) запускает на выполнение программу, указанную в первом аргументе. Мы рассмотрим эту функцию в разделе "Создание и управление процессами" далее в этой главе.
Выделение памяти
При обсуждении формата исполняемых файлов и образа программы в памяти мы отметили, что сегменты данных и стека могут изменять свои размеры. Если для стека операцию выделения памяти операционная система производит автоматически, то приложение имеет возможность управлять ростом сегмента данных, выделяя дополнительную память из хипа (heap — куча). Рассмотрим этот программный интерфейс.
Память, которая используется сегментами данных и стека, может быть выделена несколькими различными способами как во время создания процесса, так и динамически во время его выполнения. Существует четыре способа выделения памяти:
1. Переменная объявлена как глобальная, и ей присвоено начальное значение в исходном тексте программы, например:
char ptype = "Unknown file type";
Строка ptypeразмещается в сегменте инициализированных данных исполняемого файла, и для нее выделяется соответствующая память при создании процесса.
2. Значение глобальной переменной неизвестно на этапе компиляции, например:
char ptype[32];
В этом случае место в исполняемом файле для ptypeне резервируется, но при создании процесса для данной переменной выделяется необходимое количество памяти, заполненной нулями, в сегменте BSS.
Интервал:
Закладка:







