Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
![Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]](/books/1060455/vladston-ferrejra-filo-teoreticheskij-minimum-po-co.webp "Обложка книги")
- Название:Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
- Автор:
- Жанр:
- Издательство:Питер
- Год:2018
- Город:СПб.
- ISBN:978-5-4461-0587-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] краткое содержание
Владстон Феррейра Фило знакомит нас с вычислительным мышлением, позволяющим решать любые сложные задачи. Научиться писать код просто — пара недель на курсах, и вы «программист», но чтобы стать профи, который будет востребован всегда и везде, нужны фундаментальные знания. Здесь вы найдете только самую важную информацию, которая необходима каждому разработчику и программисту каждый день. cite
Владстон Феррейра Фило
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Программное обеспечение с открытым исходным кодом
Как мы уже объясняли, вы можете проанализировать команды дизассемблированной программы, но вам не удастся восстановить исходный код, который использовался для генерирования двоичного кода, так называемого бинарника.
Не имея исходного кода, вы можете лишь слегка изменить двоичный код, но у вас не выйдет внести в программу какое-либо существенное изменение, например добавить новый функционал. Некоторые люди считают, что намного лучше разрабатывать программы сообща. Они оставляют свой код открытым для других людей, чтобы те могли вносить свои изменения. Главная идея здесь — создавать программное обеспечение, которое всякий может свободно использовать и модифицировать. Основанные на Linux операционные системы (такие как Ubuntu, Fedora и Debian) являются открытыми, тогда как Windows и Mac OS — закрытыми.
Интересное преимущество операционных систем с открытым исходным кодом состоит в том, что любой может проинспектировать исходный код в поисках уязвимостей. Уже не раз было подтверждено, что государственные учреждения шпионят за миллионами граждан, используя неисправленные уязвимости защиты в повседневном потребительском программном обеспечении.
Надзор за ПО с открытым исходным кодом осуществляет куда больше глаз, поэтому лицам с дурными намерениями и правительственным учреждениям становится все труднее находить лазейки для слежки. Когда вы используете Mac OS или Windows, вам приходится доверять Microsoft или Apple, что они не поставят под угрозу вашу безопасность и приложат все усилия для предотвращения любого серьезного дефекта. А вот системы с открытым исходным кодом открыты для общественного контроля, потому в случае с ними меньше вероятность, что брешь в системе безопасности останется незамеченной.
7.3. Иерархия памяти
Мы знаем, что компьютер работает за счет ЦП, который исполняет простые команды. Мы знаем также, что эти команды могут оперировать только данными, хранящимися в регистрах ЦП. Однако их емкость обычно намного меньше тысячи байтов. Это означает, что регистрам ЦП постоянно приходится перемещать данные в ОЗУ и обратно.
Если доступ к памяти медленный, то ЦП приходится простаивать, ожидая, пока ОЗУ выполнит свою работу. Время, которое требуется, чтобы прочитать и записать данные в память, непосредственно отражается на производительности компьютера. Увеличение скорости памяти может разогнать ваш компьютер так же, как увеличение скорости ЦП. Данные в регистрах ЦП выбираются почти моментально самим процессором всего в одном цикле [80] В ЦП с таковой частотой 1 ГГц один цикл длится порядка одной миллиардной секунды — время, которое необходимо, чтобы свет прошел расстояние от страницы этой книги до ваших глаз.
. А вот ОЗУ гораздо медленнее.
Разрыв между памятью и процессором
Недавние технические разработки позволили экспоненциально увеличивать скорость ЦП. Быстродействие памяти тоже растет, но гораздо медленнее. Эта разница в производительности между ЦП и ОЗУ называется разрывом между памятью и процессором : команды ЦП «дешевы» — мы можем выполнять их в огромном количестве, тогда как получение данных из ОЗУ занимает намного больше времени и потому обходится «дорого». По мере увеличения этого разрыва возрастала важность эффективного доступа к памяти (рис. 7.10).
В современных компьютерах требуется приблизительно тысяча циклов ЦП, чтобы получить данные из ОЗУ, — около 1 микросекунды [81] Нужно где-то 10 микросекунд, чтобы звуковые волны вашего голоса достигли человека, который стоит перед вами.
. Это невероятно быстро, но составляет целую вечность по сравнению со временем доступа к регистрам ЦП. Программистам приходится искать способы сократить количество операций с ОЗУ.
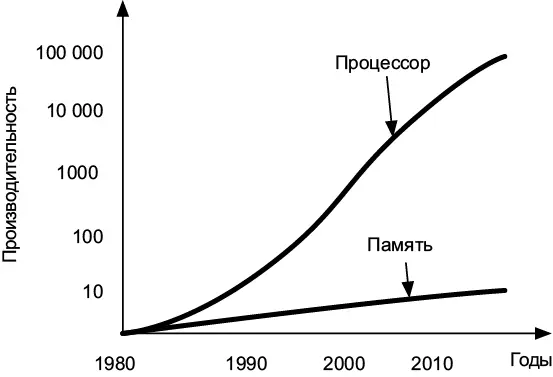
Рис. 7.10.Разрыв в быстродействии между памятью и процессором в последние десятилетия
Временная и пространственная локальность
Пытаясь свести к минимуму количество обращений к ОЗУ, специалисты в области computer science стали замечать две закономерности, получившие следующие названия:
• временна́я локальность— если выполняется доступ к некоему адресу памяти, то вполне вероятно, что к нему вскоре обратятся снова;
• пространственная локальность— если выполняется доступ к адресу памяти, то вполне вероятно, что к смежным с ним адресам вскоре обратятся тоже.
Если исходить из вышеприведенных наблюдений, можно подумать, что хранить такие адреса памяти в регистрах ЦП — отличная идея. Это позволило бы избежать большинства дорогостоящих операций с ОЗУ. Однако отраслевые инженеры не нашли надежного способа разработать микросхемы ЦП с достаточным количеством внутренних регистров. И тем не менее они обнаружили отличный способ опереться на временную и пространственную локальность. Давайте посмотрим, как он работает.
Кэш L1
Есть возможность сформировать чрезвычайно быструю вспомогательную память, интегрированную в ЦП. Мы называем ее кэшем первого уровня, или кэшем L1 . Получение данных из этой памяти в регистры осуществляется чуть-чуть медленнее, чем получение данных из самих регистров.
При помощи кэша L1 мы можем копировать содержимое адресов памяти, причем скорость доступа с высокой вероятностью будет близка к скорости регистров ЦП. Данные очень быстро загружаются в регистры ЦП. Требуется где-то 10 циклов ЦП, чтобы переместить данные из кэша L1 в регистры. Это в сто раз быстрее ситуации, когда их приходится брать из ОЗУ.
Более половины обращений к ОЗУ можно выполнить за счет кэша L1 объемом 10 Кб и умного использования временной и пространственной локальности. Это новаторское решение привело к коренному изменению вычислительных технологий. Оборудование ЦП кэшем L1 позволило кардинально сократить время, которое процессору прежде приходилось тратить на ожидание данных. Вместо простоев он теперь занят выполнением фактических вычислений.
Кэш L2
Можно было бы дальше увеличивать размер кэша L1 — выборка данных из ОЗУ тогда стала бы еще более редкой операцией, а время ожидания ЦП еще больше сократилось бы. Однако такое усовершенствование сопряжено с трудностями. Когда кэш L1 достигает размера около 50 Кб, его дальнейшее увеличение становится очень дорогостоящим. Куда лучшее решение состоит в том, чтобы сформировать дополнительный кэш памяти — кэш второго уровня, или кэш L2 . Он будет медленнее, зато намного больше кэша L1 по объему. Современный ЦП имеет кэш L2 объемом около 200 Кб. Чтобы переместить данные из кэша L2 в регистры, требуется примерно 100 циклов процессора.
Читать дальшеИнтервал:
Закладка:









