Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ

- Название:Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
- Автор:
- Жанр:
- Издательство:ДМК Пресс
- Год:2012
- Город:Москва
- ISBN:978-5-94074-448-1
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ краткое содержание
Книга «Параллельное программирование на С++ в действии» не предполагает предварительных знаний в этой области. Вдумчиво читая ее, вы научитесь писать надежные и элегантные многопоточные программы на С++11. Вы узнаете о том, что такое потоковая модель памяти, и о том, какие средства поддержки многопоточности, в том числе запуска и синхронизации потоков, имеются в стандартной библиотеке. Попутно вы познакомитесь с различными нетривиальными проблемами программирования в условиях параллелизма.
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
В разделе 5.3.1 я упоминал, что можно получить отношение синхронизируется-с между операцией сохранения атомарной переменной и операцией загрузки той же атомарной переменной в другом потоке, даже если между ними выполняется последовательность операций чтения-модификации-записи, — при условии, что все операции помечены надлежащим признаками. Теперь, когда мы знаем обо всех возможных «признаках» упорядочения, я могу подробнее осветить этот вопрос. Если операция сохранения помечена одним из признаков memory_order_release, memory_order_acq_relили memory_order_seq_cst, а операция загрузки — одним из признаков memory_order_consume, memory_order_acquireили memory_order_seq_cst, и каждая операция в цепочке загружает значение, записанное предыдущей операцией, то такая цепочка операций составляет последовательность освобождений , и первая в ней операция сохранения синхронизируется-с (в случае memory_order_acquireили memory_order_seq_cst) или предшествует-по-зависимости (в случае memory_order_consume) последней операции загрузки. Любая атомарная операция чтения-модификации-записи в цепочке может быть помечена произвольным признаком упорядочения (даже memory_order_relaxed).
Чтобы попять, что это означает и почему так важно, рассмотрим значение типа atomic, которое используется как счетчик countэлементов в разделяемой очереди (см. листинг ниже).
Листинг 5.11.Чтение из очереди с применением атомарных операций
#include
#include
std::vector queue_data; std::atomic count;
void populate_queue() {
unsigned const number_of_items = 20;
queue_data.clear();
for (unsigned i = 0; i < number_of_items; ++i) {
queue_data.push_back(i);
} ← (1) Начальное сохранение
count.store(number_of_items, std::memory_order_release);
}
void consume_queue_items() {
while (true) { ← (2) Операция ЧМЗ
int item_index;
if (
(item_index =
count.fetch_sub(1, std::memory_order_acquire)) <= 0) {
wait_for_more_items();←┐ Ждем дополнительных
continue; (3) элементов
}
process(queue_data[item_index-1]);←┐ Чтение из queue_data
} (4) безопасно
int main() {
std::thread a(populate_queue);
std::thread b(consume_queue_items);
std::thread с(consume_queue_items);
a.join();
b.join();
c.join();
}
Можно, например, написать программу так, что поток, производящий данные, сохраняет их в разделяемом буфере, а затем вызывает функцию count.store(numbеr_of_items, memory_order_release) (1), чтобы другие потоки узнали о готовности данных. Потоки- потребители, читающие данные из очереди, могли бы затем вызвать count.fetch_sub(1, memory_order_acquire) (2), чтобы проверить, есть ли элементы в очереди перед тем, как фактически читать из разделяемого буфера (4). Если счетчик countстал равен 0, то больше элементов нет, и поток должен ждать (3).
Если поток-потребитель всего один, то всё хорошо; fetch_sub()— это операция чтения с семантикой memory_order_acquire, а операция сохранения была помечена признаком memory_order_release, поэтому сохранение синхронизируется-с загрузкой, и поток может читать данные из буфера. Но если читают два потока, то второй вызов fetch_sub()увидит значение, записанное при первом вызове, а не то, которое было записано операцией store. Без правила о последовательности освобождений между вторым и первым потоком не было бы отношения происходит-раньше, поэтому было бы небезопасно читать из разделяемого буфера, если только и для первого вызова fetch_sub()тоже не задана семантика memory_order_release; однако, задав ее, мы ввели бы излишнюю синхронизацию между двумя потоками-потребителями. Без правила о последовательности освобождений или задания семантики memory_order_releaseдля всех операций fetch_subне было бы никакого механизма, гарантирующего, что операции сохранения в queue_data видны второму потребителю, следовательно, мы имели бы гонку за данными. К счастью, первый вызов fetch_sub() на самом деле участвует в последовательности освобождений, и вызов store()синхронизируется-с вторым вызовом fetch_sub(). Однако отношения синхронизируется-с между двумя потоками-потребителями все еще не существует. Это изображено на рис. 5.7, где пунктирные линии показывают последовательность освобождений, а сплошные — отношения происходит-раньше.
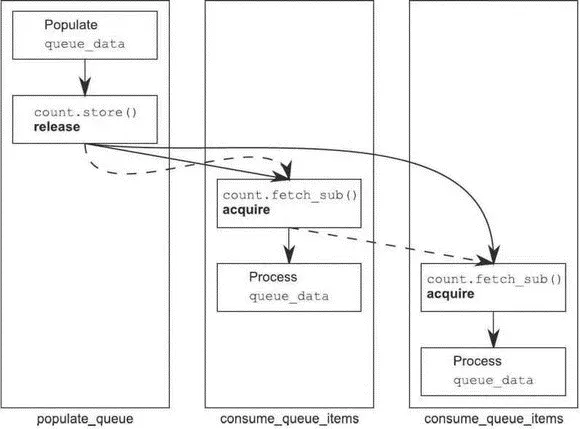
Рис. 5.7.Последовательность освобождений для операций с очередью из листинга 5.11
В цепочке может быть сколько угодно звеньев, но при условии, что все они являются операциями чтения-модификации-записи, как fetch_sub(), операция store()синхронизируется-с каждым звеном, помеченным признаком memory_order_acquire. В данном примере все звенья одинаковы и являются операциями захвата, но это вполне могли бы быть разные операции с разной семантикой упорядочения доступа к памяти.
Хотя большая часть отношений синхронизации проистекает из семантики упорядочения доступа к памяти, применённой к операциям над атомарными переменными, существует возможность задать дополнительные ограничения на упорядочение с помощью барьеров (fence).
5.3.5. Барьеры
Библиотека атомарных операций была бы неполна без набора барьеров. Это операции, которые налагают ограничения на порядок доступа к памяти без модификации данных. Обычно они используются в сочетании с атомарными операциями, помеченными признаком memory_order_relaxed. Барьеры — это глобальные операции, они влияют на упорядочение других атомарных операций в том потоке, где устанавливается барьер. Своим названием барьеры обязаны тому, что устанавливают в коде границу, которую некоторые операции не могут пересечь. В разделе 5.3.3 мы говорили, что компилятор или сам процессор вправе изменять порядок ослабленных операций над различными переменными. Барьеры ограничивают эту свободу и вводят отношения происходит-раньше и синхронизируется-с, которых до этого не было.
В следующем листинге демонстрируется добавление барьера между двумя атомарными операциями в каждом потоке из листинга 5.5.
Листинг 5.12.Ослабленные операции можно упорядочить с помощью барьеров
#include
#include
#include
std::atomic x, y;
std::atomic z;
void write_x_then_y() {
x.store(true, std::memory_order_relaxed); ← (1)
std::atomic_thread_fence(std::memory_order_release);← (2)
y.store(true, std::memory_order_relaxed); ← (3)
}
void read_y_then_x() {
while (!y.load(std::memory_order_relaxed)); ← (4)
std::atomic_thread_fence(std::memory_order_acquire);← (5)
if (x.load(std::memory_order_relaxed)) ← (6)
Интервал:
Закладка:








