Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ

- Название:Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
- Автор:
- Жанр:
- Издательство:ДМК Пресс
- Год:2012
- Город:Москва
- ISBN:978-5-94074-448-1
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ краткое содержание
Книга «Параллельное программирование на С++ в действии» не предполагает предварительных знаний в этой области. Вдумчиво читая ее, вы научитесь писать надежные и элегантные многопоточные программы на С++11. Вы узнаете о том, что такое потоковая модель памяти, и о том, какие средства поддержки многопоточности, в том числе запуска и синхронизации потоков, имеются в стандартной библиотеке. Попутно вы познакомитесь с различными нетривиальными проблемами программирования в условиях параллелизма.
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
В следующем листинге показана простая реализация такой очереди с урезанным по сравнению с листингом 6.2 интерфейсом; мы оставили только функцию try_pop()и убрали функцию wait_and_pop(), потому что эта очередь поддерживает только однопоточную работу.
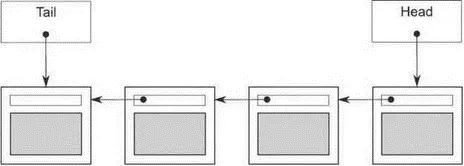
Рис. 6.1.Очередь, представленная в виде односвязного списка
Листинг 6.4.Простая реализация однопоточной очереди
template
class queue {
private:
struct node {
T data;
std::unique_ptr next;
node(T data_):
data(std::move(data_)) {}
};
std::unique_ptr head;← (1)
node* tail; ← (2)
public:
queue() {}
queue(const queue& other) = delete;
queue& operator=(const queue& other) = delete;
std::shared_ptr try_pop() {
if (!head) {
return std::shared_ptr();
}
std::shared_ptr const res(
std::make_shared(std::move(head->data)));
std::unique_ptr const old_head = std::move(head);
head = std::move(old_head->next);← (3)
return res;
}
void push(T new_value) {
std::unique_ptr p(new node(std::move(new_value)));
node* const new_tail = p.get();
if (tail) {
tail->next = std::move(p);← (4)
} else {
head = std::move(p); ← (5)
}
tail = new_tail; ← (6)
}
};
Прежде всего отметим, что в листинге 6.4 для управления узлами используется класс std::unique_ptr, потому что он гарантирует удаление потерявших актуальность узлов (и содержащихся в них данных) без явного использования delete. За передачу владения отвечает head, тогда как tailявляется простым указателем на последний узел.
В однопоточном контексте эта реализация прекрасно работает, но при попытке ввести мелкогранулярные блокировки в многопоточном контексте возникают две проблемы. Учитывая наличие двух элементов данных ( head (1)и tail (2)), мы в принципе могли бы использовать два мьютекса — для защиты headи tailсоответственно. Но не всё так просто.
Самая очевидная проблема заключается в том, что push()может изменять как head (5), так и tail (6), поэтому придётся захватывать оба мьютекса. Это не очень хорошо, но не трагедия, потому что захватить два мьютекса, конечно, можно. Настоящая проблема возникает из-за того, что и push(), и pop()обращаются к указателю nextв узле: push()обновляет tail->next (4), a try_pop()читает head->next (3). Если в очереди всего один элемент, то head==tail, и, значит, head->nextи tail->next— один и тот же объект, который, следовательно, нуждается в защите. Поскольку нельзя сказать, один это объект или нет, не прочитав и head, и tail, нам приходится захватывать один и тот же мьютекс в push()и в try_pop(), и получается, что мы ничего не выиграли по сравнению с предыдущей реализацией. Есть ли выход из этого тупика?
Решить проблему можно, заранее выделив фиктивный узел, не содержащий данных, и тем самым гарантировать, что в очереди всегда есть хотя бы один узел, отделяющий голову от хвоста. В случае пустой очереди headи tailтеперь указывают на фиктивный узел, а не равны NULL. Это хорошо, потому что try_pop()не обращается к head->next, если очередь пуста. После добавления в очередь узла (в результате чего в ней находится один реальный узел) headи tailуказывают на разные узлы, так что гонки за head->nextи tail->nextне возникает. Недостаток этого решения в том, что нам пришлось добавить лишний уровень косвенности для хранения указателя на данные, чтобы поддержать фиктивный узел. В следующем листинге показано, как теперь выглядит реализация.
Листинг 6.5.Простая очередь с фиктивным узлом
template
class queue {
private:
struct node {
std::shared_ptr data;← (1)
std::unique_ptr next;
};
std::unique_ptr head;
node* tail;
public:
queue():
head(new node), tail(head.get())← (2)
{}
queue(const queue& other) = delete;
queue& operator=(const queue& other) = delete;
std::shared_ptr try_pop() {
if (head.get() ==tail)← (3)
{
return std::shared_ptr();
}
std::shared_ptr const res(head->data);← (4)
std::unique_ptr old_head = std::move(head);
head = std::move(old_head->next); ← (5)
return res; ← (6)
}
void push(T new_value) {
std::shared_ptr new_data(
std::make_shared(std::move(new_value)));← (7)
std::unique_ptr p(new node);← (8)
tail->data = new_data;← (9)
node* const new_tail = p.get();
tail->next = std::move(p);
tail = new_tail;
}
};
Изменения в try_pop()минимальны. Во-первых, мы сравниваем headс tail (3), а не с NULL, потому что благодаря наличию фиктивного узла headникогда не может обратиться в NULL. Поскольку headимеет тип std::unique_ptr, для сравнения необходимо вызывать head.get(). Во-вторых, так как в nodeтеперь хранится указатель на данные (1), то можно извлекать указатель непосредственно (4)без конструирования нового экземпляра T. Наиболее серьезные изменения претерпела функция push(): мы должны сначала создать новый экземпляр Tв куче и передать владение им std::shared_ptr<> (7)(обратите внимание на использование функции std::make_shared, чтобы избежать накладных расходов на второе выделение памяти под счетчик ссылок). Вновь созданный узел станет новым фиктивным узлом, поэтому передавать конструктору значение new_valueнеобязательно (8). Вместо этого мы записываем в старый фиктивный узел значение только что созданной копии — new_value (9). Наконец, первоначальный фиктивный узел следует создать в конструкторе (2).
Уверен, теперь вы задаетесь вопросом, что мы выиграли от всех этих изменений и как они помогут сделать код потокобезопасным. Разберемся. Функция push()теперь обращается только к tail, но не к head, и это, безусловно, улучшение. try_pop()обращается и к head, и к tail, но tailнужен только для начального сравнения, так что блокировка удерживается очень недолго. Основной выигрыш мы получили за счет того, что из-за наличия фиктивного узла try_pop()и push()никогда не оперируют одним и тем же узлом, так что нам больше не нужен всеохватывающий мьютекс. Стало быть, мы можем завести по одному мьютексу для headи tail. Но где расставить блокировки?
Интервал:
Закладка:








