Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум

- Название:Системное программное обеспечение. Лабораторный практикум
- Автор:
- Жанр:
- Издательство:Array Издательство «Питер»
- Год:2005
- Город:Санкт-Петербург
- ISBN:978-5-469-00391-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум краткое содержание
Книга ориентирована на студентов, обучающихся в технических вузах по специальностям, связанным с вычислительной техникой. Но она будет также полезна всем, чья деятельность так или иначе касается разработки программного обеспечения.
Системное программное обеспечение. Лабораторный практикум - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Кроме того, информация о некоторых типах лексем, найденных в исходной программе, должна помещаться в таблицу идентификаторов (или в одну из таблиц идентификаторов, если компилятор предусматривает различные таблицы идентификаторов для различных типов лексем).
Внимание!
Не следует путать таблицу лексем и таблицу идентификаторов – это две принципиально разные таблицы, обрабатываемые лексическим анализатором.
Таблица лексем фактически содержит весь текст исходной программы, обработанный лексическим анализатором. В нее входят все возможные типы лексем, кроме того, любая лексема может встречаться в ней любое количество раз. Таблица идентификаторов содержит только определенные типы лексем – идентификаторы и константы. В нее не попадают такие лексемы, как ключевые (служебные) слова входного языка, знаки операций и разделители. Кроме того, каждая лексема (идентификатор или константа) может встречаться в таблице идентификаторов только один раз. Также можно отметить, что лексемы в таблице лексем обязательно располагаются в том же порядке, что и в исходной программе (порядок лексем в ней не меняется), а в таблице идентификаторов лексемы располагаются в любом порядке так, чтобы обеспечить удобство поиска.
В качестве примера можно рассмотреть некоторый фрагмент исходного кода на языке Object Pascal и соответствующую ему таблицу лексем, представленную в табл. 2.1:
…
begin
for i:=1 to N do
fg:= fg * 0.5
…

Поле «значение» в табл. 2.1 подразумевает некое кодовое значение, которое будет помещено в итоговую таблицу лексем в результате работы лексического анализатора. Конечно, значения, которые записаны в примере, являются условными. Конкретные коды выбираются разработчиками при реализации компилятора. Важно отметить также, что устанавливается связь таблицы лексем с таблицей идентификаторов (в примере это отражено некоторым индексом, следующим после идентификатора за знаком «:», а в реальном компиляторе определяется его реализацией).
Построение лексических анализаторов (сканеров)
Лексический анализатор имеет дело с такими объектами, как различного рода константы и идентификаторы (к последним относятся и ключевые слова). Язык описания констант и идентификаторов в большинстве случаев является регулярным, то есть может быть описан с помощью регулярных грамматик [1–4, 7]. Распознавателями для регулярных языков являются конечные автоматы (КА). Существуют правила, с помощью которых для любой регулярной грамматики может быть построен КА, распознающий цепочки языка, заданного этой грамматикой.
Более подробно о построении КА на основе грамматик для регулярных языков можно узнать в [3, 7, 26].
Любой КА может быть задан с помощью пяти параметров: M(Q,Σ,δ,q 0,F),
где:
Q – конечное множество состояний автомата;
Σ – конечное множество допустимых входных символов (входной алфавит КА);
δ – заданное отображение множества Q·Σ во множество подмножеств P(Q)δ: Q·Σ → P(Q) (иногда δ называют функцией переходов автомата);
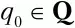
– начальное состояние автомата;
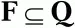
– множество заключительных состояний автомата.
Другим способом описания КА является граф переходов – графическое представление множества состояний и функции переходов КА. Граф переходов КА – это нагруженный однонаправленный граф, в котором вершины представляют состояния КА, дуги отображают переходы из одного состояния в другое, а символы нагрузки (пометки) дуг соответствуют функции перехода КА. Если функция перехода КА предусматривает переход из состояния q в q' по нескольким символам, то между ними строится одна дуга, которая помечается всеми символами, по которым происходит переход из q в q'.
Недетерминированный КА неудобен для анализа цепочек, так как в нем могут встречаться состояния, допускающие неоднозначность, то есть такие, из которых выходит две или более дуги, помеченные одним и тем же символом. Очевидно, что программирование работы такого КА – нетривиальная задача. Для простого программирования функционирования КА M(Q,Σ,δ,q 0,F) он должен быть детерминированным – в каждом из возможных состояний этого КА для любого входного символа функция перехода должна содержать не более одного состояния:
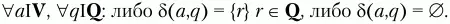
Доказано, что любой недетерминированный КА может быть преобразован в детерминированный КА так, чтобы их языки совпадали [3, 7, 26] (говорят, что эти КА эквивалентны).
Кроме преобразования в детерминированный КА любой КА может быть минимизирован – для него может быть построен эквивалентный ему детерминированный КА с минимально возможным количеством состояний. Алгоритмы преобразования КА в детерминированный КА и минимизации КА подробно описаны в [3, 7, 26].
Можно написать функцию, отражающую функционирование любого детерминированного КА. Чтобы запрограммировать такую функцию, достаточно иметь переменную, которая бы отображала текущее состояние КА, а переходы из одного состояния в другое на основе символов входной цепочки могут быть построены с помощью операторов выбора. Работа функции должна продолжаться до тех пор, пока не будет достигнут конец входной цепочки. Для вычисления результата функции необходимо по ее завершении проанализировать состояние КА. Если это одно из конечных состояний, то функция выполнена успешно и входная цепочка принимается, если нет, то входная цепочка не принадлежит заданному языку.
Однако в общем случае задача лексического анализатора шире, чем просто проверка цепочки символов лексемы на соответствие ее входному языку. Он должен правильно определить конец лексемы (об этом было сказано выше) и выполнить те или иные действия по запоминанию распознанной лексемы (занесение ее в таблицу лексем). Набор выполняемых действий определяется реализацией компилятора. Обычно эти действия выполняются сразу же при обнаружении конца распознаваемой лексемы.
Во входном тексте лексемы не ограничены специальными символами. Определение границ лексем – это выделение тех строк в общем потоке входных символов, для которых надо выполнять распознавание. Если границы лексем всегда определяются (а выше было принято именно такое соглашение), то их можно определить по заданным терминальным символам и по символам начала следующей лексемы. Терминальные символы – это пробелы, знаки операций, символы комментариев, а также разделители (запятые, точки с запятой и др.). Набор таких терминальных символов может варьироваться в зависимости от входного языка. Важно отметить, что знаки операций сами также являются лексемами и необходимо не пропустить их при распознавании текста.
Читать дальшеИнтервал:
Закладка: