Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум

- Название:Системное программное обеспечение. Лабораторный практикум
- Автор:
- Жанр:
- Издательство:Array Издательство «Питер»
- Год:2005
- Город:Санкт-Петербург
- ISBN:978-5-469-00391-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум краткое содержание
Книга ориентирована на студентов, обучающихся в технических вузах по специальностям, связанным с вычислительной техникой. Но она будет также полезна всем, чья деятельность так или иначе касается разработки программного обеспечения.
Системное программное обеспечение. Лабораторный практикум - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Время, требуемое на добавление нового элемента в таблицу (T д), не зависит от числа элементов в таблице (N). Но если N велико, то поиск потребует значительных затрат времени. Время поиска (T п) в такой таблице можно оценить как T п= O(N). Поскольку именно поиск в таблице идентификаторов является наиболее часто выполняемой компилятором операцией, такой способ организации таблиц идентификаторов является неэффективным. Он применим только для самых простых компиляторов, работающих с небольшими программами.
Поиск может быть выполнен более эффективно, если элементы таблицы отсортированы (упорядочены) естественным образом. Поскольку поиск осуществляется по имени, наиболее естественным решением будет расположить элементы таблицы в прямом или обратном алфавитном порядке. Эффективным методом поиска в упорядоченном списке из N элементов является бинарный, или логарифмический, поиск.
Алгоритм логарифмического поиска заключается в следующем: искомый символ сравнивается с элементом (N + 1)/2 в середине таблицы; если этот элемент не является искомым, то мы должны просмотреть только блок элементов, пронумерованных от 1 до (N + 1)/2 – 1, или блок элементов от (N + 1)/2 + 1 до N в зависимости от того, меньше или больше искомый элемент того, с которым его сравнили. Затем процесс повторяется над нужным блоком в два раза меньшего размера. Так продолжается до тех пор, пока либо искомый элемент не будет найден, либо алгоритм не дойдет до очередного блока, содержащего один или два элемента (с которыми можно выполнить прямое сравнение искомого элемента).
Так как на каждом шаге число элементов, которые могут содержать искомый элемент, сокращается в два раза, максимальное число сравнений равно 1 + log 2N. Тогда время поиска элемента в таблице идентификаторов можно оценить как T п= O(log 2N). Для сравнения: при N = 128 бинарный поиск требует самое большее 8 сравнений, а поиск в неупорядоченной таблице – в среднем 64 сравнения. Метод называют «бинарным поиском», поскольку на каждом шаге объем рассматриваемой информации сокращается в два раза, а «логарифмическим» – поскольку время, затрачиваемое на поиск нужного элемента в массиве, имеет логарифмическую зависимость от общего количества элементов в нем.
Недостатком логарифмического поиска является требование упорядочивания таблицы идентификаторов. Так как массив информации, в котором выполняется поиск, должен быть упорядочен, время его заполнения уже будет зависеть от числа элементов в массиве. Таблица идентификаторов зачастую просматривается компилятором еще до того, как она заполнена, поэтому требуется, чтобы условие упорядоченности выполнялось на всех этапах обращения к ней. Следовательно, для построения такой таблицы можно пользоваться только алгоритмом прямого упорядоченного включения элементов.
Если пользоваться стандартными алгоритмами, применяемыми для организации упорядоченных массивов данных, то среднее время, необходимое на помещение всех элементов в таблицу, можно оценить следующим образом:
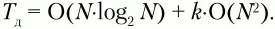
Здесь k – некоторый коэффициент, отражающий соотношение между временами, затрачиваемыми компьютером на выполнение операции сравнения и операции переноса данных.
При организации логарифмического поиска в таблице идентификаторов обеспечивается существенное сокращение времени поиска нужного элемента за счет увеличения времени на помещение нового элемента в таблицу. Поскольку добавление новых элементов в таблицу идентификаторов происходит существенно реже, чем обращение к ним, этот метод следует признать более эффективным, чем метод организации неупорядоченной таблицы. Однако в реальных компиляторах этот метод непосредственно также не используется, поскольку существуют более эффективные методы.
Построение таблиц идентификаторов по методу бинарного дерева
Можно сократить время поиска искомого элемента в таблице идентификаторов, не увеличивая значительно время, необходимое на ее заполнение. Для этого надо отказаться от организации таблицы в виде непрерывного массива данных.
Существует метод построения таблиц, при котором таблица имеет форму бинарного дерева. Каждый узел дерева представляет собой элемент таблицы, причем корневым узлом становится первый элемент, встреченный компилятором при заполнении таблицы. Дерево называется бинарным, так как каждая вершина в нем может иметь не более двух ветвей. Для определенности будем называть две ветви «правая» и «левая».
Рассмотрим алгоритм заполнения бинарного дерева. Будем считать, что алгоритм работает с потоком входных данных, содержащим идентификаторы. Первый идентификатор, как уже было сказано, помещается в вершину дерева. Все дальнейшие идентификаторы попадают в дерево по следующему алгоритму:
1. Выбрать очередной идентификатор из входного потока данных. Если очередного идентификатора нет, то построение дерева закончено.
2. Сделать текущим узлом дерева корневую вершину.
3. Сравнить имя очередного идентификатора с именем идентификатора, содержащегося в текущем узле дерева.
4. Если имя очередного идентификатора меньше, то перейти к шагу 5, если равно – прекратить выполнение алгоритма (двух одинаковых идентификаторов быть не должно!), иначе – перейти к шагу 7.
5. Если у текущего узла существует левая вершина, то сделать ее текущим узлом и вернуться к шагу 3, иначе – перейти к шагу 6.
6. Создать новую вершину, поместить в нее информацию об очередном идентификаторе, сделать эту новую вершину левой вершиной текущего узла и вернуться к шагу 1.
7. Если у текущего узла существует правая вершина, то сделать ее текущим узлом и вернуться к шагу 3, иначе – перейти к шагу 8.
8. Создать новую вершину, поместить в нее информацию об очередном идентификаторе, сделать эту новую вершину правой вершиной текущего узла и вернуться к шагу 1.
Рассмотрим в качестве примера последовательность идентификаторов Ga, D1, М22, Е, А12, ВС, F. На рис. 1.1 проиллюстрирован весь процесс построения бинарного дерева для этой последовательности идентификаторов.
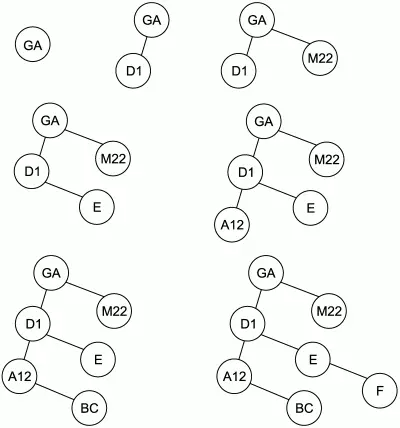
Рис. 1.1. Заполнение бинарного дерева для последовательности идентификаторов.
Поиск элемента в дереве выполняется по алгоритму, схожему с алгоритмом заполнения дерева:
1. Сделать текущим узлом дерева корневую вершину.
2. Сравнить имя искомого идентификатора с именем идентификатора, содержащимся в текущем узле дерева.
3. Если имена совпадают, то искомый идентификатор найден, алгоритм завершается, иначе надо перейти к шагу 4.
Читать дальшеИнтервал:
Закладка: