Тимур Казанцев - Искусственный интеллект и Машинное обучение. Основы программирования на Python

- Название:Искусственный интеллект и Машинное обучение. Основы программирования на Python
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:2020
- ISBN:978-5-532-04002-1
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Тимур Казанцев - Искусственный интеллект и Машинное обучение. Основы программирования на Python краткое содержание
Для желающих овладеть языком программирования Python, на котором решается большинство задач по машинному обучению, мы пройдем основы программирования на этом языке и научимся использовать его для построения моделей машинного и глубокого обучения.
Искусственный интеллект и Машинное обучение. Основы программирования на Python - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Основные задачи и методы машинного обучения
Обучение с учителем и обучение без учителя
Если вы интересовались темой искусственного интеллекта и машинного обучения, возможно вы уже встречались с такими понятиями как обучение с учителем (на англ. supervised learning) и обучение без учителя (unsupervised learning). В этой главе мы узнаем, чем отличаются эти два понятия.
Во-первых, они оба являются видами машинного обучения.
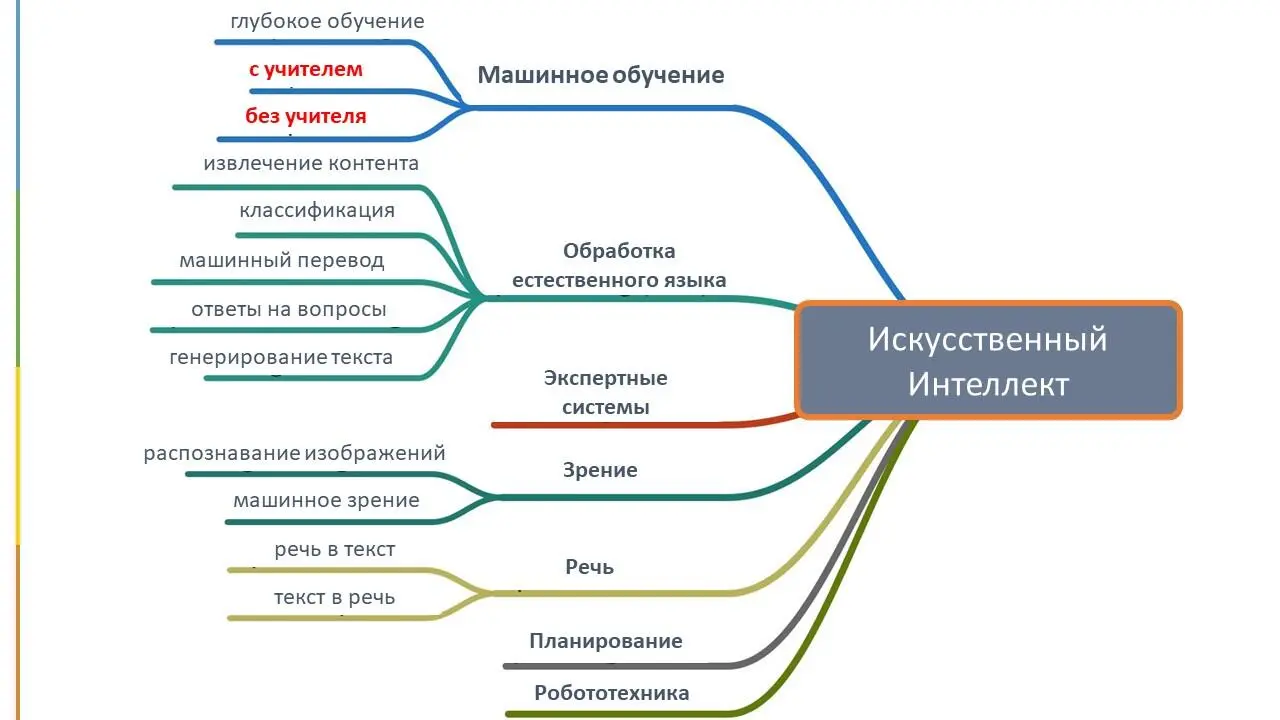
Во-вторых, обучение с учителем не обязательно подразумевает, что кто-то стоит над компьютером и контролирует каждое его действие. В терминах машинного обучения, обучение с «учителем» означает, что человек уже подготовил данные для дальнейшей работы над ними компьютером, то есть у каждого объекта имеется метка (на англ. label) которая выделяет этот объект от остальных объектов или дает ему какое-то именное или числовое наименование. И компьютеру остается только найти закономерности между признаками объектов и их наименованиями, основываясь на этих подготовленных или как их называют помеченных данных. На английском такие данные называются labeled data.
Обучение с учителемвключает два основных типа задач: регрессия и классификация. Давайте посмотрим на типичный пример задачи классификации.
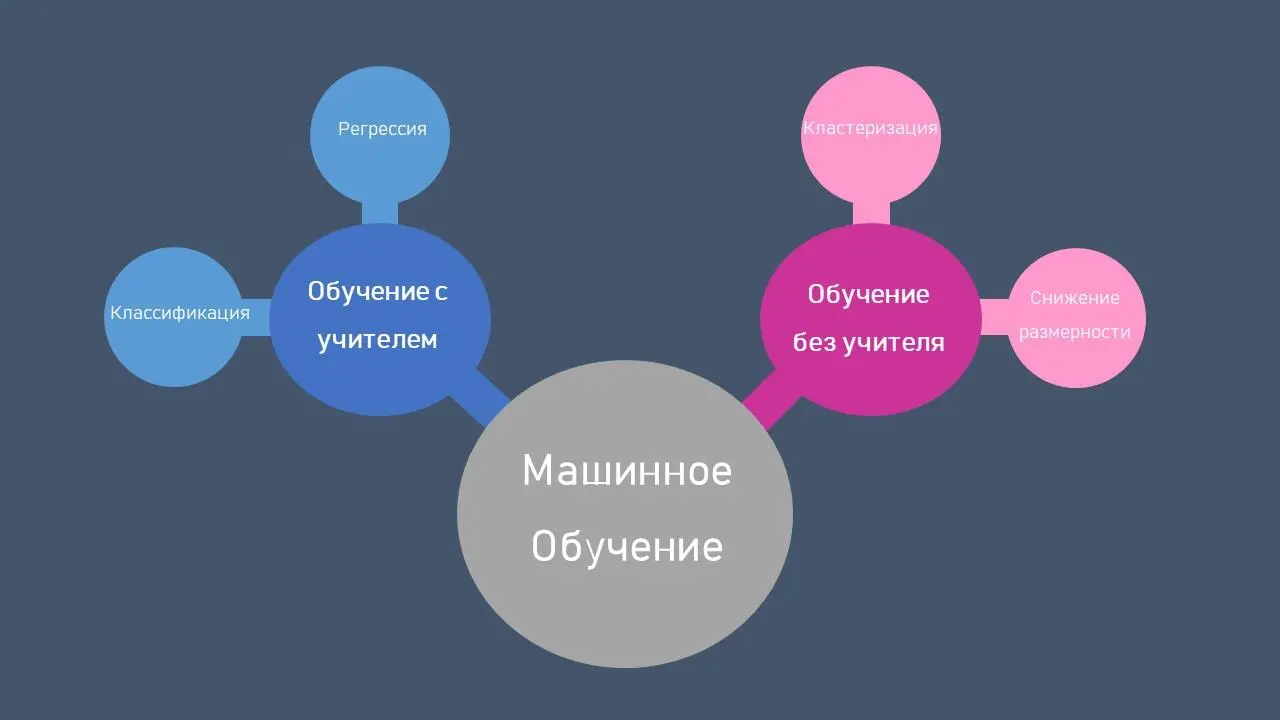
Это будет пример цветков ириса Фишера. Этот набор данных стал уже классическим, и часто используется для иллюстрации работы различных статистических алгоритмов. Вы можете найти его по следующей ссылке (https://gist.github.com/curran/a08a1080b88344b0c8a7) либо просто вбив в интернете.
В природе существует три вида цветков ириса. Они отличаются друг от друга размерами лепестка и чашелистника. Все данные по цветкам занесены в таблицу, в столбиках указаны длина и ширина лепестка, а также длина и ширина чашелистника. В последнем столбце указан вид ириса – Ирис щетинистый ( Iris setosa ), Ирис виргинский ( Iris virginica ) и Ирис разноцветный ( Iris versicolor ). Тот или иной вид ириса и является в нашем случае меткой.
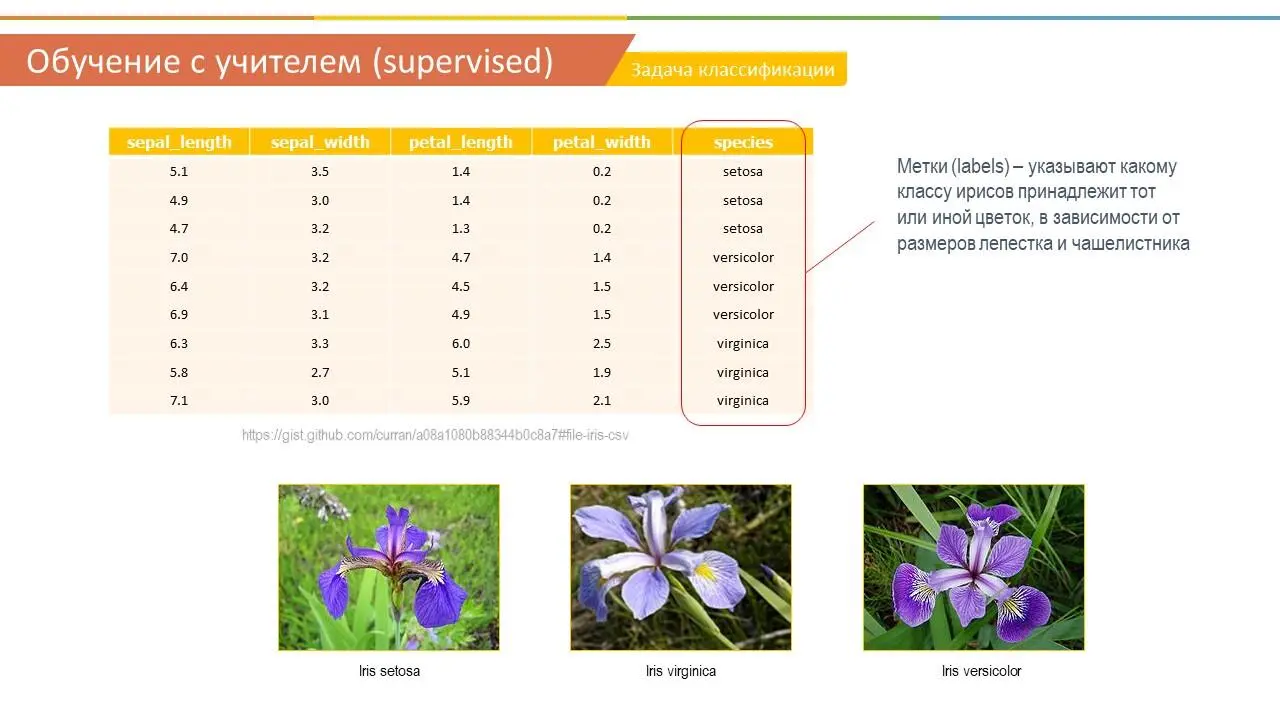
На основании этого набора данных требуется построить правило классификации, определяющее вид растения в зависимости от размеров. Это задача многоклассовой классификации, так как имеется три класса – три вида ириса.
В данном случае с помощью алгоритма классификации, мы разделяем наши ирисы на три вида в зависимости от длины и ширины лепестка и чашелистника. В следующий раз, если нам попадется новый представитель ирисов, с помощью нашей модели мы сможем сразу же его поместить в тот или иной из трех классов.
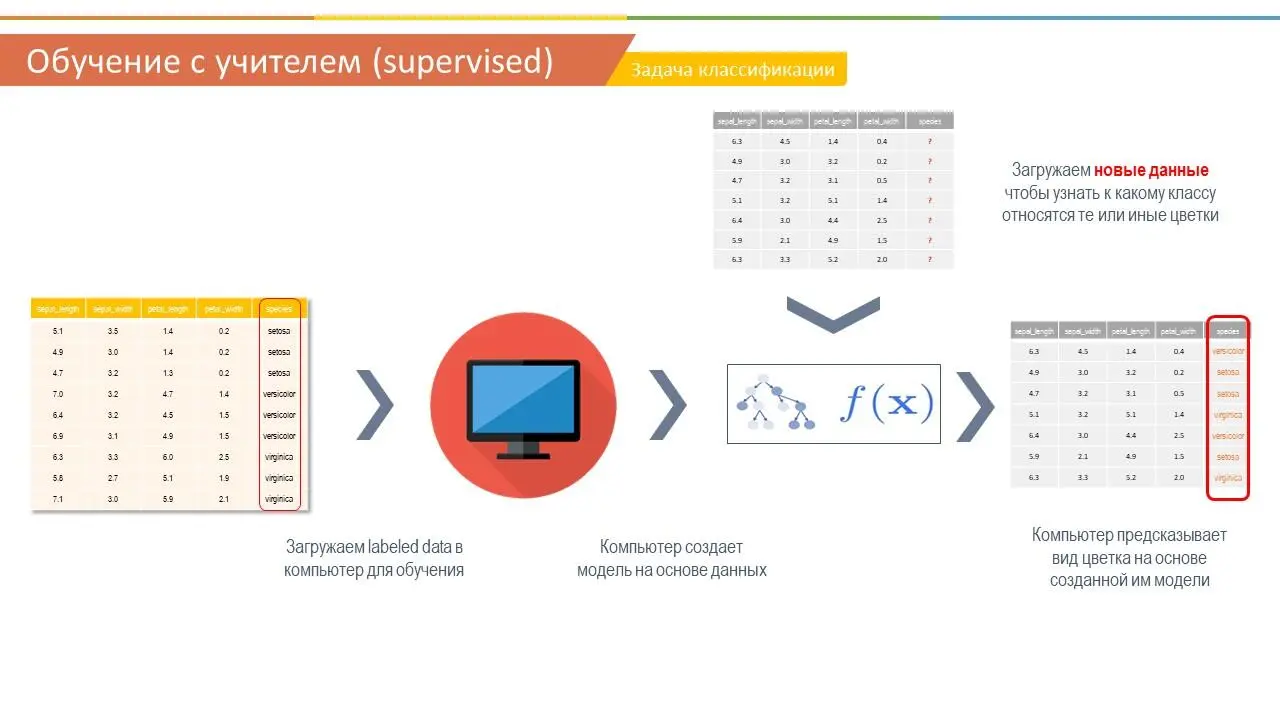
Почему этот пример можно считать обучение с учителем? Потому что наши данные распределены по признакам, у каждого признака есть показатель для конкретного цветка, то есть размеры длины и ширины. И имеются ответы или метки, какой вид ириса бывает при тех или иных размерах лепестка и чашелистника. То есть мы как учитель обучаем нашу модель и говорим ей, что вот окей, если ты видишь, что размер лепестка такой-то, а чашелистника – такой, то этой ирис виргинский, а если размеры такие-то и такие-то, то это ирис разноцветный. Это и называется обучение с учителем, когда мы показываем нашей модели все ответы в зависимости от признаков. Модель учится на этих данных, и создает формулу или алгоритм, который поможет нам в будущем предсказывать вид цветка в зависимости от размеров, когда нам будут поступать новые образцы цветов.
Кроме задач классификации, о которой мы только что говорили в примере с ирисами, есть еще один вид машинного обучения с учителем. Это регрессия.
Если в задачах классификации мы имеем несколько классов объектов, то в задачах регрессии, у нас один класс, но каждый объект отличается от другого и нам надо предсказать какой будет числовой показатель того или иного признака каждого объекта в зависимости от других его признаков и опять же на основании набора данных, которые мы предоставим нашему компьютеру.

Классический пример регрессии – это когда мы предсказываем цену квартиры в зависимости от ее площади.
Опять же мы имеем какую-то таблицу с данными разных квартир. В одном столбце площадь, а в другом – цены на эти квартиры. Это очень упрощенный пример регрессии, естественно, что цена квартиры будет зависеть от множества других факторов, но все же он наглядно демонстрирует, что такое регрессия. Так вот, в последнем столбце мы расположили фактические или реальные цены на квартиры с таким метражом. То есть, мы как учитель, показываем нашей модели, что вот, если видишь, что метраж такой-то, то цена будет такая-то и т.д. На основе этих данных модель учится, и потом выдает алгоритм, на основе которого мы можем предсказывать, какая будет цена квартиры, если условная площадь будет такая-то.
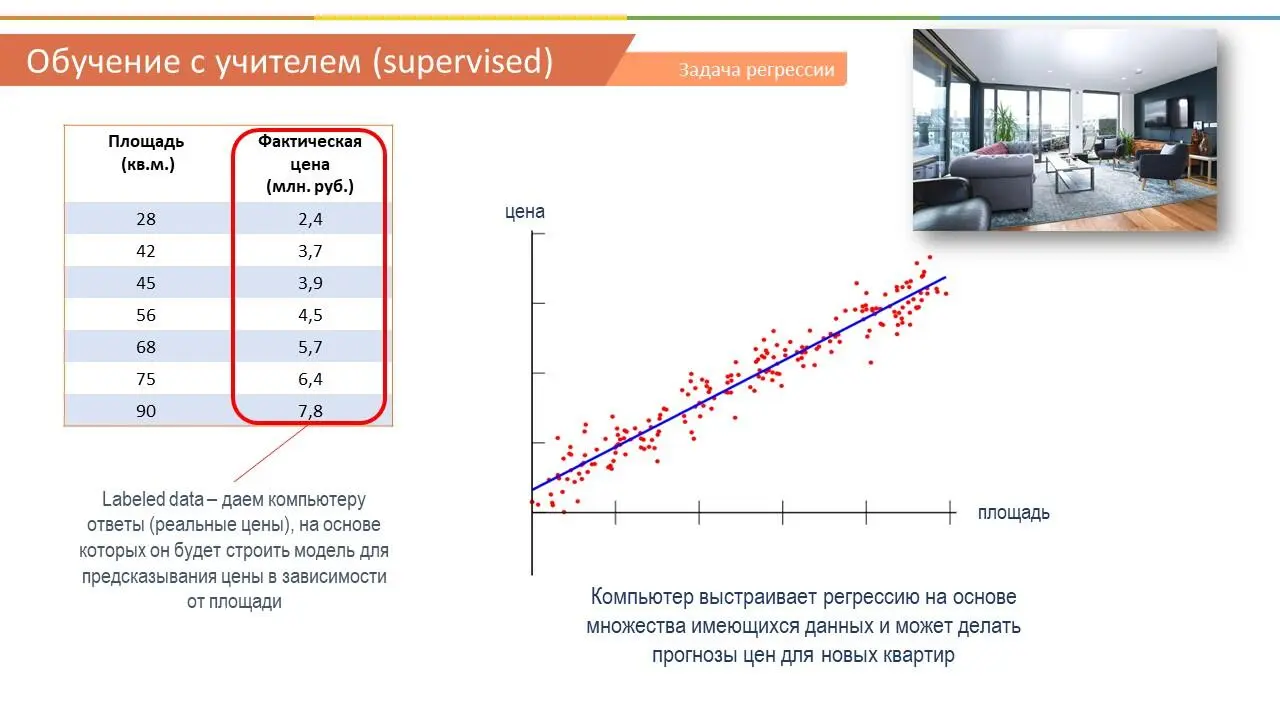
Таким образом, если суммировать, то в обучении с учителем – ключевая фраза – это labeled data или помеченные данные. То есть мы загружаем в нашу модель данные с ответами, будь то класс, к которому принадлежит тот или иной объект или реальная цена квартиры в зависимости от площади. На основе этой информации модель учится и создает алгоритм, который может делать прогнозы.
Идем дальше. Второй вид машинного обучения – это обучение без учителя. Это когда мы позволяем нашей модели обучаться самостоятельно и находить информацию, которая может быть не видна очевидно для человека.
В отличие от обучения с учителем, модели, которые используются в обучении без учителя, выводят закономерности и выводы на основе немаркированных данных (или unlabeled data). Помните, у нас был пример с цветками ириса. Так вот в данных, которые мы давали компьютеру, присутствовали ответы какой вид ириса мы имеем в зависимости от тех или иных размеров лепестка и чашелистника. А в немаркированных данных, у нас имеются данные и признаки, но мы не имеем ответа к какому виду или классу они относятся. Поэтому такие данные называются немаркированные.
В обучении без учителя основными типами задач являются Кластеризация и снижение размерности. Если в двух словах, то снижение размерности означает, что мы удаляем ненужные или излишние признаки из наших данных, чтобы облегчить классификацию наших данных и сделать ее более понятной для интерпретации.
Читать дальшеИнтервал:
Закладка: