Скотт Мейерс - Эффективное использование STL

- Название:Эффективное использование STL
- Автор:
- Жанр:
- Издательство:Питер
- Год:2002
- Город:СПб.
- ISBN:ISBN 5-94723-382-7
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Скотт Мейерс - Эффективное использование STL краткое содержание
В этой книге известный автор Скотт Мейерс раскрывает секреты настоящих мастеров, позволяющие добиться максимальной эффективности при работе с библиотекой STL.
Во многих книгах описываются возможности STL, но только в этой рассказано о том, как работать с этой библиотекой. Каждый из 50 советов книги подкреплен анализом и убедительными примерами, поэтому читатель не только узнает, как решать ту или иную задачу, но и когда следует выбирать то или иное решение — и почему именно такое.
Эффективное использование STL - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
В объекте, на который ссылается указатель, хранится размер строки, емкость и счетчик ссылок, а также указатель на динамически выделенный буфер с текущим содержимым строки. Здесь же хранятся дополнительные данные, относящиеся к синхронизации доступа в многопоточных системах. К нашей теме они не относятся, поэтому на рисунке соответствующая часть структуры данных обозначена «Прочее».

Блок «Прочее» оказался больше остальных блоков, поскольку я постарался выдержать масштаб изображения. Если один блок вдвое больше другого, значит, он занимает вдвое больше памяти. В реализации В размер данных синхронизации примерно в шесть раз превышает размер указателя.
В реализации С размер объекта string всегда равен размеру указателя, но этот указатель всегда ссылается на динамически выделенный буфер, содержащий все данные строки: размер, емкость, счетчик ссылок и текущее содержимое. Распределители уровня объекта не поддерживаются. В буфере также хранятся данные, описывающие возможности совместного доступа к содержимому; эта тема здесь не рассматривается, поэтому соответствующий блок на рисунке помечен буквой «X» (если вас интересует, зачем может потребоваться ограничение доступа к данным с подсчетом ссылок, обратитесь к совету 29 «More Effective С++»).

В реализации D объекты string занимают в семь раз больше памяти, чем указатель (при использовании стандартного распределителя памяти). В этой реализации подсчет ссылок не используется, но каждый объект string содержит внутренний буфер, в котором могут храниться до 15 символов. Таким образом, небольшие строки хранятся непосредственно в объекте string — данная возможность иногда называется «оптимизацией малых строк». Если емкость строки превышает 15 символов, в начале буфера хранится указатель на динамически выделенный блок памяти, в котором содержатся символы строки.
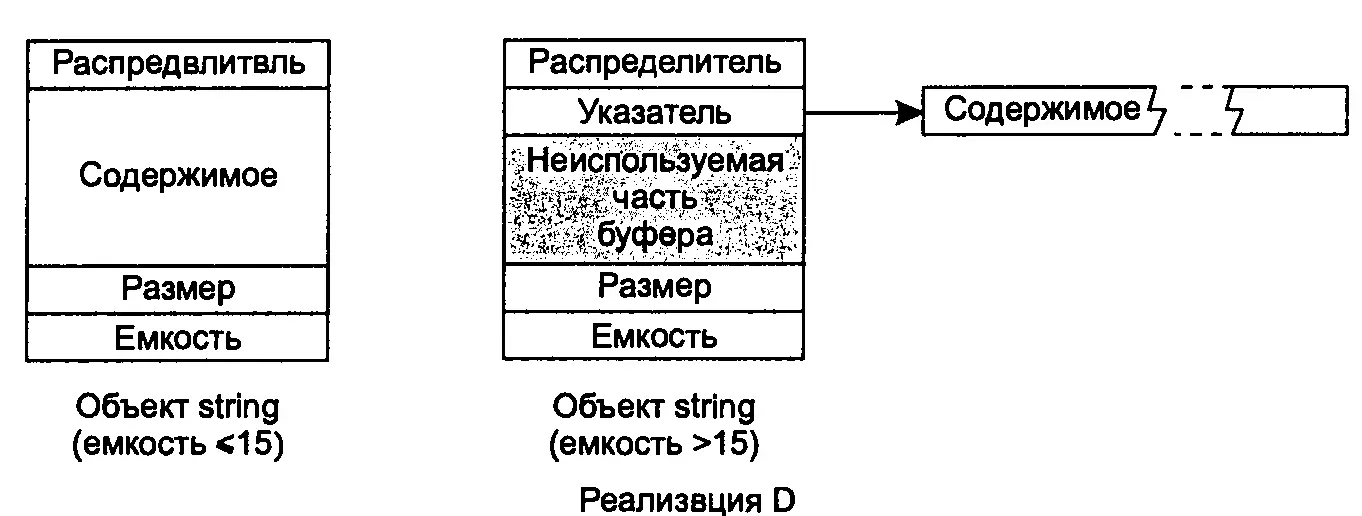
Я поместил здесь эти диаграммы совсем не для того, чтобы убедить читателя в своем умении читать исходные тексты и рисовать красивые картинки. По ним также можно сделать вывод, что создание объекта string командами вида
string s("Perse"); // Имя нашей собаки - Персефона, но мы
// обычно зовем ее просто "Перси"
в реализации D обходится без динамического выделения памяти, обходится одним выделением в реализациях А и С и двумя — в реализации В (для объекта, на который ссылается указатель string, и для символьного буфера, на который ссылается указатель в этом объекте). Если для вас существенно количество операций выделения/освобождения или затраты памяти, часто связанные с этими операциями, от реализации В лучше держаться подальше. С другой стороны, наличие специальной поддержки синхронизации доступа в реализации В может привести к тому, что эта реализация подойдет для ваших целей лучше, чем реализации А и С, а количество динамических выделений памяти уйдет на второй план. Реализация D не требует специальной поддержки многопоточности, поскольку в ней не используется подсчет ссылок. За дополнительной информацией о связи между многопоточностью и строками с подсчетом ссылок обращайтесь к совету 13. Типичная поддержка многопоточности в контейнерах STL описана в совете 12.
В архитектуре, основанной на подсчете ссылок, все данные, находящиеся за пределами объекта string, могут совместно использоваться разными объектами string (имеющими одинаковое содержимое), поэтому из приведенных диаграмм также можно сделать вывод, что реализация А обладает меньшими возможностями для совместного использования данных. В частности, реализации В и С допускают совместное использование данных размера и емкости объекта, что приводит к потенциальному уменьшению затрат на хранение этих данных на уровне объекта. Интересно и другое: отсутствие поддержки распределителей уровня объекта в реализации С означает, что это единственная реализация с возможностью использования общих распределителей: все объекты string должны работать с одним распределителем! (За информацией о принципах работы распределителей обращайтесь к совету 10.) Реализация D не позволяет совместно использовать данные в объектах string.
Один из интересных аспектов поведения string, не следующий непосредственно из этих диаграмм, относится к стратегии выделения памяти для малых строк. В некоторых реализациях устанавливается минимальный размер выделяемого блока памяти; к их числу принадлежат реализации А, С и D. Вернемся к команде
string s ("Perse"); // Строка s состоит из 5 символов
В реализации А минимальный размер выделяемого буфера равен 32 символам. Таким образом, хотя размер s во всех реализациях равен 5 символам, емкость этого контейнера в реализации А равна 31 (видимо, 32-й символ зарезервирован для завершающего нуль-символа, упрощающего реализацию функции c_str). В реализации С также установлен минимальный размер буфера, равный 16, при этом место для завершающего нуль-символа не резервируется, поэтому в реализации С емкость s равна 16. Минимальный размер буфера в реализации D также равен 16, но с резервированием места для завершающего нуль-символа. Принципиальное отличие реализации D заключается в том, что содержимое строк емкостью менее 16 символов хранится в самом объекте string. Реализация В не имеет ограничений на минимальный размер выделяемого блока, и в ней емкость s равна 7. (Почему не 6 или 5? Не знаю. Простите, я не настолько внимательно анализировал исходные тексты.)
Из сказанного очевидно следует, что стратегия выделения памяти для малых строк может сыграть важную роль, если вы собираетесь работать с большим количеством коротких строк и (1) в вашей рабочей среде не хватает памяти или (2) вы стремитесь по возможности локализовать ссылки и пытаетесь сгруппировать строки в минимальном количестве страниц памяти.
Конечно, в выборе реализации string разработчик обладает большей степенью свободы, чем кажется на первый взгляд, причем эта свобода используется разными способами. Ниже перечислены ишь некоторые переменные факторы.
• По отношению к содержимому string может использоваться (или не использоваться) подсчет ссылок. По умолчанию во многих реализациях подсчет ссылок включен, но обычно предоставляется возможность его отключения (как правило, при помощи препроцессорного макроса). В совете 13 приведен пример специфической ситуации, когда может потребоваться отключение подсчета ссылок, но такая необходимость может возникнуть и по другим причинам. Например, подсчет ссылок экономит время лишь при частом копировании строк. Если в приложении строки копируются редко, затраты на подсчет ссылок не оправдываются.
Читать дальшеИнтервал:
Закладка:



