Д. Стефенс - C++. Сборник рецептов

- Название:C++. Сборник рецептов
- Автор:
- Жанр:
- Издательство:КУДИЦ-ПРЕСС
- Год:2007
- Город:Москва
- ISBN:5-91136-030-6
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Д. Стефенс - C++. Сборник рецептов краткое содержание
Данная книга написана экспертами по C++ и содержит готовые рецепты решения каждодневных задач для программистов на С++. Один из авторов является создателем библиотеки Boost Iostreams и нескольких других библиотек C++ с открытым исходным кодом. В книге затрагивается множество тем, вот лишь некоторые из них: работа с датой и временем; потоковый ввод/вывод; обработка исключений; работа с классами и объектами; сборка приложений; синтаксический анализ XML-документов; программирование математических задач. Читатель сможет использовать готовые решения, а сэкономленное время и усилия направить на решение конкретных задач.
C++. Сборник рецептов - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
EqualKey = equal_to, // Функция, используемая для
// проверки равенства ключей
Alloc = alloc>; // Используемый распределитель памяти
hash_map— это хеш-таблица, которая хранит значения как объекты pair. Это означает, что когда я буду далее описывать хеш-таблицы, «элементы» в таблице будут означать пары ключ/значение. hash_mapне хранит ключи значение по отдельности (как и map). hash_setпросто хранит ключ как значение.
Параметр шаблона HashFun— это функция, которая превращает объекты типа Keyв значения, которые могут быть сохранены как size_t. Более подробно это описывается ниже. Параметр шаблона EqualKey— это функция, которая принимает два аргумента и, если они эквивалентны, возвращает true. В контейнерах hash_mapи hash_setдва ключа не могут быть равны, hash_multimapи hash_multisetмогут содержать по нескольку одинаковых ключей. Как и в случае с другими контейнерами, Alloc— это используемый распределитель памяти.
Хеш-таблица содержит две части. В ней есть относительно большой вектор, где каждый индекс это «участок». Каждый из участков является на самом деле указателем на первый узел в относительно коротком одно- или двухсвязном списке (в STLPort — односвязном). Именно в этих списках и хранятся данные. Чтобы получить число участков в хеш-контейнере, используйте метод bucket_count. Рисунок 6.3 дает представление о том, как выглядит в памяти хеш-отображение.
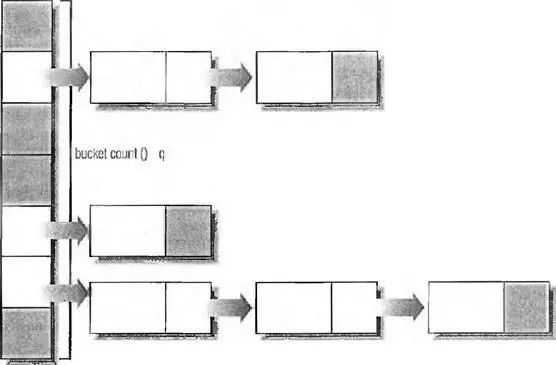
Рис. 6.3. Хеш-таблица
Рассмотрим использование hash_setиз примера 6.8. При вставке элемента контейнер вначале должен определить, к какому участку он относится. Это делается с помощью вызова хеш-функции контейнера, передачи в нее ключа (хеш-функция обсуждается немного позже) и вычисления остатка от деления значения на число участков. В результате получается индекс в векторе участков.
Если вы незнакомы с тем, что такое «хеширование», то это очень простая концепция. Если есть какое-то значение (скажем, массив типа char), то хеш-функция для него — это функция, которая принимает один аргумент и возвращает значение хеша типа size_t(т.е. число). В идеале требуется хеш-функция, которая генерирует уникальные значения хешей, но она не обязана это делать. Эта функция в математическом смысле неоднозначна: несколько строк типа string могут иметь одно и то же значение хеша. Далее я скажу, почему это не страшно.
STLPort включает в и такую хеш-функцию как шаблон функции. Однако эта функция не работает для любого объекта, так как невозможно создать общей хеш-функции, которая бы работала с любым вводом. Вместо этого имеется несколько специализированных встроенных типов, наиболее часто используемых для ключей в хеш-таблицах. Например, если требуется посмотреть, как выглядит значение хеша, хешируйте строку символов.
std::hash hashFun;
std::cout << "\"Hashomatic\" хешируется как "
<< hashFun("Hashomatic") << '\n';
Вы увидите что-то похожее на следующее.
"Hashomatic" хешируется как 189555649
STLPort предоставляет специализации для следующих типов: char*, const char*, char, unsigned char, signed char, short, unsigned short, int, unsigned int, longи unsigned long. Кажется, что их очень много, но в целом это означает, что библиотека содержит встроенные хеш-функции, которые поддерживают символьные строки и числа. Если требуется хешировать что-то другое, то просто укажите собственную хеш-функцию.
При помещении элемента в хеш-таблицу она определяет, какому участку принадлежит элемент, используя оператор взятия остатка от деления и число участков, т.е. hashFun(key) % bucket_count(). Это быстрый оператор, который указывает непосредственно на индекс в главном векторе, по которому начинается участок.
Хеш-контейнер можно использовать как обычный ассоциативный контейнер, используя для добавления элементов в, скажем, hash_mapоператор operator[]. Разница заключается в том, что вы знаете, что вставка и поиск займут постоянное время, а не логарифмическое. Рассмотрим пример 6.9, который содержит простой класс, отображающий имена логинов на объекты Session. Он использует некоторые из возможностей хеш-контейнеров, описываемых в этом рецепте.
Пример 6.9. Простой менеджер сессий
#include
#include
#include
using namespace std;
class Session { /* ... */ };
// Облегчение читаемости с помощью typedef
typedef hash_map SessionHashMap;
class SessionManager {
public:
SessionManager() : sessionMap_(500) {} // Инициализация хеш-таблицы
// 500-ми участками
~SessionManager() {
for (SessionHashMap::iterator p = sessionMap_.begin();
p != sessionMap_.end(); ++p)
delete (*p).second; // Удаление объекта Session
}
Session* addSession(const string& login) {
Session* p = NULL;
if (!(p = getSession(login))) {
p = new Session();
sessionMap_[login] = d; // Присвоение новой сессии с помощью
} // operator[]
return(p);
}
Session* getSession(const string& login) {
return(sessionMap_[login]);
}
// ...
private:
SessionHashMap sessionMap_;
};
Каждый ключ отображается на единственный участок, а в участке может храниться несколько ключей. Участок это обычно одно- или двухсвязный список.
По хеш-функциям и таблицам написано огромное количество книг. Если вы заинтересовались этим вопросом, поищите в Google «C++ hash function».
Рецепт 6.6.
6.8. Хранение объектов в упорядоченном виде
Требуется сохранить набор объектов в заданном порядке, например с целью доступа к упорядоченным диапазонам этих объектов без их пересортировки при каждом таком обращении.
Используйте ассоциативный контейнер set, объявленный в , который хранит элементы в упорядоченном виде. По умолчанию он использует стандартный шаблон класса less(который для своих аргументов вызывает operator<), а можно передать в него собственный предикат сортировки. Пример 6.10 показывает, как сохранить строки в set.
Пример 6.10. Хранение строк в set
#include
#include
#include
using namespace std;
int main() {
set setStr;
string s = "Bill";
setStr.insert(s);
s = "Steve";
setStr.insert(s);
s = "Randy";
setStr.insert(s);
s = "Howard";
setStr.insert(s);
for (set::const_iterator p = setStr.begin();
p != setStr.end(); ++p)
cout << *p << endl;
}
Так как значения хранятся в упорядоченном виде, вывод будет выглядеть так.
Bill
Howard
Randy
Steve
set(набор) — это ассоциативный контейнер, который предоставляет логарифмическую сложность вставки и поиска и постоянную сложность удаления элементов (если требуется удалить найденный элемент), set— это уникальный ассоциативный контейнер, что означает, что никакие два элемента не могут быть равны, однако если требуется хранить несколько экземпляров одинаковых элементов, используйте multiset, setможно представить как набор в математическом смысле, т.е. коллекцию элементов, в дополнение обеспечивающую поддержание определенного порядка элементов.
Интервал:
Закладка:








