Д. Стефенс - C++. Сборник рецептов

- Название:C++. Сборник рецептов
- Автор:
- Жанр:
- Издательство:КУДИЦ-ПРЕСС
- Год:2007
- Город:Москва
- ISBN:5-91136-030-6
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Д. Стефенс - C++. Сборник рецептов краткое содержание
Данная книга написана экспертами по C++ и содержит готовые рецепты решения каждодневных задач для программистов на С++. Один из авторов является создателем библиотеки Boost Iostreams и нескольких других библиотек C++ с открытым исходным кодом. В книге затрагивается множество тем, вот лишь некоторые из них: работа с датой и временем; потоковый ввод/вывод; обработка исключений; работа с классами и объектами; сборка приложений; синтаксический анализ XML-документов; программирование математических задач. Читатель сможет использовать готовые решения, а сэкономленное время и усилия направить на решение конкретных задач.
C++. Сборник рецептов - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
for (list::reverse_iterator p = lstStr.rbegin();
p != lstStr.rend(); ++p) {
cout << *p << endl;
}
Но может возникнуть ситуация, когда использовать reverse_iteratorневозможно. В этом случае используйте обычный iterator, как здесь.
for (list::iterator p = --lstStr.end();
p != --lstStr.begin(); --p) {
cout << *p << endl;
}
Наконец, если вы знаете, на сколько элементов вперед или назад следует выполнить перебор, используйте вычисление значения, на которое следует перевести итератор. Например, чтобы перейти в середину списка, сделайте вот так.
size_t i = lstStr.size();
list::iterator p = begin();
p += i/2; // Переход к середине последовательности
Но помните: в зависимости от типа используемого контейнера эта операция может иметь как постоянную, так и линейную сложность. При использовании контейнеров, которые хранят элементы последовательно, таких как vectorили deque, iteratorможет перейти на любое вычисленное значение за постоянное время. Но при использовании контейнера на основе узлов, такого как list, такая операция произвольного доступа недоступна. Вместо этого приходится перебирать все элементы, пока не будет найден нужный. Это очень дорого. Именно поэтому выбор контейнера, используемого в каждой конкретной ситуации, определяется требованиями к перебору элементов контейнера и их поиска в нем. (За более подробной информацией о работе стандартных контейнеров обратитесь к главе 6.)
При использовании контейнеров, допускающих произвольный доступ, для доступа к элементам использования operator[]с индексной переменной следует предпочитать iterator. Это особенно важно при написании обобщенного алгоритма в виде шаблона функции, так как не все контейнеры поддерживают iteratorс произвольным доступом.
С итератором можно делает еще много чего, но не с любым iterator. iteratorможет принадлежать к одной из пяти категорий, обладающих разной степенью функциональности. Однако они не так просты, как иерархия классов, так что именно это я далее и опишу.
Итераторы, предоставляемые различными типами контейнеров, не обязательно все умеют делать одно и то же. Например, vector::iteratorпозволяет использовать для перехода на некоторое количество элементов вперед operator+=, в то время как list::iteratorне позволяет. Разница между этими двумя типами итераторов определяется их категорией .
Категории итераторов — это, по сути, интерфейс (не технически; для реализации категорий итераторов абстрактные базовые классы не используются). Имеется пять категорий, и каждая предлагает увеличение возможностей. Вот как они выглядят — от наименее до наиболее функциональной.
Input iterator (Итератор ввода)
Итератор ввода поддерживает переход вперед с помощью p++или ++pи разыменовывание с помощью *p. При его разыменовывании возвращается rvalue, iteratorввода используется для таких вещей, как потоки, где разыменовывание итератора ввода означает извлечение очередного элемента из потока, что позволяет прочесть только один конкретный элемент.
Output iterator (Итератор вывода)
Итератор вывода поддерживает переход вперед с помощью p++или ++pи разыменовывание с помощью *p. От итератора ввода он отличается тем, что из него невозможно читать, а можно только записывать в него — по одному элементу за раз. Также, в отличие от итератора ввода, он возвращает не rvalue, a lvalue,так что в него можно записывать значение, а извлекать из него — нельзя.
Forward iterator (Однонаправленный итератор)
Однонаправленный итератор объединяет функциональность итераторов ввода и вывода: он поддерживает ++pи p++, а *pможет рассматриваться как rvalueили lvalue. Однонаправленный итератор можно использовать везде, где требуется итератор ввода или вывода, используя то преимущество, что читать из него и записывать в него после его разыменовывания можно без ограничений
Bidirectional iterator (Двунаправленный итератор)
Как следует из его названия, двунаправленный iteratorможет перемещаться как вперед, так и назад. Это однонаправленный iterator, который может перемещаться назад с помощью --pили p--.
Random-access iterator (Итератор произвольного доступа)
Итератор произвольного доступа делает все, что делает двунаправленный iterator, но также поддерживает операции, аналогичные операциям с указателями.. Для доступа к элементу, расположенному в позиции n после pпоследовательности, можно использовать p[n], можно складывать его значение или вычитать из него с помощью +, +=, -или -=, перемещая его вперед или назад на заданное количество элементов. Также с помощью <, >, <=или >=можно сравнивать два итератора p1и p2, определяя их относительный порядок (при условии, что они оба относятся к одной и той же последовательности).
Или можно представить все в виде диаграммы Венна. Она представлена на рис. 7.1.
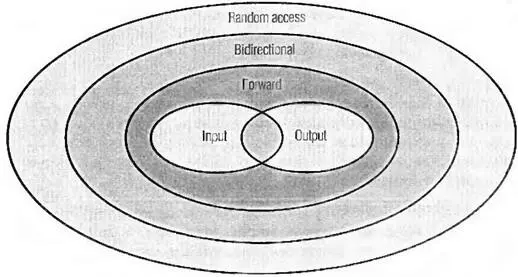
Рис. 7.1. Категории итераторов
Большая часть стандартных контейнеров поддерживает как минимум двунаправленный iterator, некоторые ( vectorи deque) предоставляют iteratorпроизвольного доступа. Категория итератора, поддерживаемая контейнером, определяется стандартом.
В большинстве случае вы будете использовать iteratorдля простейших задач: поиск элемента и его удаление или что-либо подобное. Для этой цели требуется только однонаправленный iterator, который доступен для всех контейнеров. Но когда потребуется написать нетривиальный алгоритм или использовать алгоритм из стандартной библиотеки, часто потребуется нечто большее, чем простой однонаправленный iterator. Но как определить, что вам требуется? Здесь на сцену выходят категории итераторов.
Различные категории итераторов позволяют стандартным (и нестандартным) алгоритмам указать диапазон требуемой функциональности. Обычно стандартные алгоритмы работают с диапазонами, указываемыми с помощью итераторов, а не с целыми контейнерами. Объявление стандартного алгоритма говорит, какую категорию iteratorон ожидает». Например, std::sortтребует итераторов произвольного доступа, так как ему требуется за постоянное время ссылаться на несмежные элементы. Таким образом, объявление sortвыглядит вот так.
template
void sort(RandomAccessIterator first, RandomAccessIterator last);
По имени типа итератора можно определить, что он ожидает итератор произвольного доступа. Если попробовать откомпилировать sortдля категории итератора, отличной от произвольного доступа, то она завершится ошибкой, так как младшие категории iteratorне реализуют операций, аналогичных арифметике с указателями.
Интервал:
Закладка:








