Хелен Борри - Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ

- Название:Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ
- Автор:
- Жанр:
- Издательство:БХВ-Петербург
- Год:2006
- Город:Санкт-Петербург
- ISBN:5-94157-609-9
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Хелен Борри - Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ краткое содержание
Рассмотрены вопросы, необходимые разработчику для создания клиент-серверных приложений с использованием СУБД Firebird, явившейся развитием СУБД Borland Interbase 6. Содержится обзор концепций и моделей архитектуры клиент/сервер, а также практические рекомендации по работе с клиентскими библиотеками Firebird. Детально описаны особенности типов данных SQL, язык манипулирования данными (Data Manipulation Language, DML), а также синтаксис и операторы языка определения данных ( Data Definition Language, DDL). Большое внимание уделено описанию транзакций и приведены советы по их использованию при разработке приложений. Описано программирование на стороне клиента и сервера написание триггеров и хранимых процедур, создание и использование событий базы данных, обработка ошибок в коде на сервере и многое другое. Материал сопровождается многочисленными примерами, советами и практическими рекомендациями.
Для разработчиков баз данных
Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Два фактора оказывают влияние на глубину: размеры страницы и ключа. Если глубина больше 3 и размер страницы меньше 8192, то увеличение размера страницы до 8192 или 16 386 должно уменьшить количество косвенных уровней и увеличить скорость.
! ! !
СОВЕТ. Вы можете вычислить приблизительный размер (в страницах) цепочки мах dup на основании статистических данных. Для получения количества узлов на странице разделите узлы (nodes) на количество листьев (leaf buckets). Умножение результата на максимальное количество дублирующих узлов (max dup) дает приблизительное количество страниц.
. ! .
Следующие выдержки являются выводом gstat -index для базы данных с плохой производительностью.
Первый из поддерживаемых индексов, который был создан автоматически для внешнего ключа:
Index RDB$FOREIGNl4 (3)
Depth: 2, leaf buckets: 109, nodes: 73373
Average data length: 0.00, total dup: 73372, max dup: 32351
Fill distribution:
80 - 99% = 109
Строка Depth: 2, leaf buckets: 109, nodes: 73373 Сообщает нам, что нижний уровень индекса имеет 109 листьев (страниц), количество узлов 73 373. Это может и не быть общим количеством строк таблицы. С одной стороны, утилита gstat ничего не знает о транзакциях, поэтому она не может сообщить, найдены ли подтвержденные или неподтвержденные страницы. С другой - столбцы могут иметь значения NULL и не будут попадать в статистику.
Нижний уровень индекса- где хранятся узлы листьев- имеет всего 109 страниц. Кажется подозрительным наличие малого количества страниц для такого большого количества строк. Следующая статистика объясняет, почему.
В строке Average data length: 0.00, total dup: 73372, max dup: 32351 число max dup указывает длину самой длинной цепочки дубликатов, подсчитанной почти для половины узлов. Число total dup говорит, что каждый узел, за исключением одного, является дубликатом.
Это самый классический случай, когда проектировщик применяет внешний ключ без рассмотрения его распределения. Вероятно, это столбец стиля BOOLEAN или таблица соответствия (lookup) либо с очень небольшим количеством значений, либо практически с одним значением.
Примером этому было приложение формирования списка избирателей, которое сохраняло столбец страны проживания. Избирателей было приблизительно 3 миллиона, а регистрация была принудительной. База данных имела таблицу COUNTRY, содержащую более 300 стран, снабженную ключами в кодах стран CCCIT. Она присутствовала чуть ли не в каждой таблице базы данных в качестве внешнего ключа. Беда была в том, что почти все избиратели жили в одной стране.
Средняя длина данных (Average data length) - это средняя длина хранимого ключа. Здесь мало что можно сделать с объявленной длиной. Нулевое значение средней длины означает лишь то, что в процессе сжатия не осталось "пищи" для вычисления среднего значения.
Строка Fill distribution показывает, что все 109 страниц находятся в диапазоне 80-99 процентов, что является хорошим заполнением. Распределение заполнения является долей пространства каждой страницы, используемой для данных и указателей. От восьмидесяти до девяноста процентов - это хорошо. Меньшее распределение заполнения является весьма серьезным напоминанием, что вы должны пересоздать индекс.
Следующий пример показывает статистику сгенерированного системой индекса для первичного ключа в той же таблице:
Index RDB$PRIMARY10 (0)
Depth: 3, leaf buckets: 298, nodes: 73373
Average data length: 10.00, total dup: 0, max dup: 0
Fill distribution:
0 - 19% = 1
80 - 99% = 297
Длина ключа 10 означает, что выполнено некоторое сжатие. Это нормально и хорошо. То что одна строка мало заполнена- вполне нормально: количество узлов не соответствует точно страницам.
Эта база данных имеет маленькую таблицу, хранящую временные данные для проверки достоверности. Она периодически очищается и наполняется снова. Следующая статистика генерируется для внешнего ключа этой таблицы:
Index RDB$FOREIGN263 (1)
Depth: 1, leaf buckets: 10, nodes: 481
Average data length: 0.00, total dup: 480, max dup: 480
Fill distribution:
0 - 19% = 10
Total dup и max dup идентичны - каждая строка имеет одинаковое значение в ключе индекса. Селективность не может быть хуже этой. Уровень заполнения, очень низкий для всех страниц, наводит на мысль о разнородных удалениях. Если бы это не было маленькой таблицей, такой индекс был бы ужасен.
Данная таблица - очередь обработки - очень динамична, она хранит до 1000 новых строк в день. После проверки данных строки переносятся в порождающие таблицы, а строки разрабатываемой таблицы удаляются, приводя к замедлению работы системы. Частое резервное копирование и восстановление базы данных необходимо, чтобы дела шли нормально.
Проблема в том, что в этом случае следует избегать внешних ключей, и если они являются необходимыми, то их можно реализовать с помощью триггеров, созданных пользователем.
Однако, если проектирование базы данных, безусловно, требует ограничений внешних ключей для временных таблиц со столбцами низкой селективности, существуют рекомендованные способы уменьшения накладных расходов и снижения ухудшения состояния индексных страниц, являющихся следствием удаления и дальнейшего наполнения данными таблицы. Отслеживайте уровень заполнения проблемных индексов и принимайте меры, когда он упадет ниже 40%. Выбор действий зависит от ваших требований.
* Если возможно, удаляйте все строки за один раз, а не выполняйте их удаление одну за другой в случайном порядке. Удалите ограничение внешнего ключа, удалите строки и подтвердите транзакцию. Заново создайте ограничение. Поскольку это не длинная транзакция, задерживающая сборку мусора, новый индекс будет полностью пустым.
* Если удаления должны быть последовательными, выберите время, чтобы получить исключительный доступ и использовать ALTER INDEX для пересоздания индекса. Это будет более быстро и предсказуемо, чем инкрементная сборка мусора в огромной цепочке дубликатов.
Другие переключатели gstat
Статистика утилиты gstat может предоставить полезную информацию о других действиях с базой данных.
Эта строка
gstat -header база-данных
отображает суммарную информацию заголовочной страницы базы данных. На рис. 18.5 показан пример.
Первая строка отображает имя и размещение первичного файла базы данных. Следующие строки содержат информацию из заголовочной страницы базы данных. В табл. 18.3 описывается этот вывод.
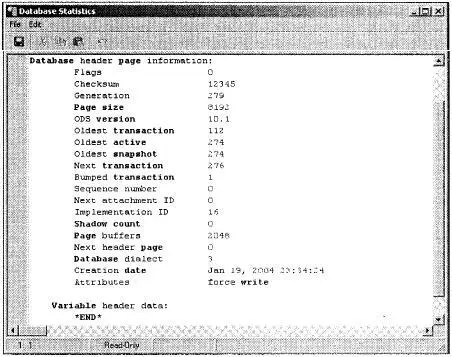
Рис. 18.5. Пример вывода заголовочной страницы утилитой gstat
Таблица 18.3. Вывод gstat -h[eader]
|
Элемент |
Описание |
|
Flags |
Флаги |
|
Checksum |
Контрольная сумма заголовочной страницы. В прототипе (InterBase) это было уникальное значение, вычислявшееся по всем данным заголовочной страницы. В Firebird это всегда 12 345. Когда заголовочная страница сохраняется на диске, а затем считывается, контрольная сумма найденной страницы сравнивается с 12 345, и если они не соответствуют, то вызывается ошибка контрольной суммы. Это перехватывает некоторые виды физического разрушения |
Интервал:
Закладка:


