Роберт Лав - Разработка ядра Linux

- Название:Разработка ядра Linux
- Автор:
- Жанр:
- Издательство:Издательский дом Вильямс
- Год:2006
- Город:Москва
- ISBN:5-8459-1085-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роберт Лав - Разработка ядра Linux краткое содержание
В книге детально рассмотрены основные подсистемы и функции ядер Linux серии 2.6, включая особенности построения, реализации и соответствующие программны интерфейсы. Рассмотренные вопросы включают: планирование выполнения процессов, управление временем и таймеры ядра, интерфейс системных вызовов, особенности адресации и управления памятью, страничный кэш, подсистему VFS, механизмы синхронизации, проблемы переносимости и особенности отладки. Автор книги является разработчиком основных подсистем ядра Linux. Ядро рассматривается как с теоретической, так и с прикладной точек зрения, что может привлечь читателей различными интересами и потребностями.
Книга может быть рекомендована как начинающим, так и опытным разработчикам программного обеспечения, а также в качестве дополнительных учебных материалов.
Разработка ядра Linux - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
unsigned int bv_offset;
};
Для каждой операции блочного ввода-вывода создается массив из bi_vcntэлементов типа bio_vec, начало которого содержится в поле bi_io_vecs. В процессе выполнения операции блочного ввода-вывода поле bi_idxиспользуется для указания на текущий элемент массива.
В общем, каждый запрос на выполнение блочного ввода-вывода представляется с помощью структуры bio. Каждый такой запрос состоит из одного или более блоков, которые хранятся в массиве структур bio_vec. Каждая из этих структур представляет собой вектор, который описывает положение в физической памяти каждого сегмента запроса. На первый сегмент для операции ввода-вывода указывает поле bi_io_vec. Каждый следующий сегмент следует сразу за предыдущим. Всего в массиве bi_vcntсегментов. В процессе того, как уровень блочного ввода-вывода обрабатывает сегменты запроса, обновляется значение поля bi_idx, чтобы его значение соответствовало номеру текущего сегмента. На рис. 13.2 показана связь между структурами bio, bio_vecи page.
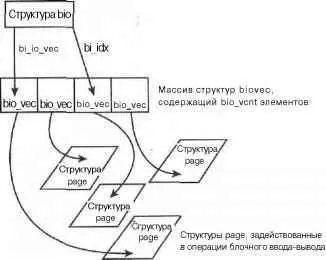
Рис. 13.2. Связь между структурами struct bio, struct bio_vecи struct page
Поле bi_idxуказывает на текущую структуру bio_vecв массиве, что позволяет уровню блочного ввода-вывода поддерживать частично выполненные операции блочного ввода-вывода. Однако более важное использование состоит в том, что драйверы таких устройств, как RAID (Redundant Array of Inexpensive/Independent Disks, массив недорогих/независимых дисковых устройств с избыточностью — специальный способ использования жестких дисков, при котором один логический том может быть распределен но нескольким физическим дискам для увеличения надежности или производительности), могут одну структуру bio, которая изначально была адресована одному устройству, разбивать на несколько частей, которые предназначаются различным дискам RAID массива. Все, что необходимо сделать драйверу RAID, это создать необходимое количество копий структуры bio, которая предназначалась одному устройству, и изменить для каждой копии значение поля bi_idx, чтобы оно указывало на ту часть массива, откуда каждый диск должен начать свою операцию ввода-вывода.
Структура bioсодержит счетчик использования, который хранится в поле bi_cnt. Когда значение этого поля становится равным нулю, структура удаляется, и занятая память освобождается. Следующие две функции позволяют управлять счетчиком использования.
void bio_get(struct bio *bio);
void bio_put(struct bio *bio);
Первая увеличивает на единицу значение счетчика использования, а вторая — уменьшает значение этого счетчика на единицу и, если это значение становится равным нулю, уничтожает соответствующую структуру bio. Перед тем как работать с активной структурой bio, необходимо увеличить счетчик использования, чтобы гарантировать, что экземпляр структуры не будет удален во время работы. После окончания работы необходимо уменьшить счетчик использования.
И наконец, поле bio_private— это поле данных создателя (владельца) структуры. Как правило, это поле необходимо считывать или записывать только тому, кто создал данный экземпляр структуры bio.
Сравнение старой и новой реализаций
Между заголовками буферов и новой структурой bioсуществуют важные отличия. Структура bioпредставляет операцию ввода-вывода, которая может включать одну или больше страниц в физической памяти. С другой стороны, заголовок буфера связан с одним дисковым блоком, который занимает не более одной страницы памяти. Поэтому использование заголовков буферов приводит к ненужному делению запроса ввода-вывода на части, размером в один блок, только для того, чтобы их потом снова объединить. Работа со структурами bio выполняется быстрее, эта структура может описывать несмежные блоки и не требует без необходимости разбивать операции ввода-вывода на части.
Переход от структуры struct buffer_headк структурам struct bioпозволяет получить также и другие преимущества.
• Структура bioможет легко представлять верхнюю память (см. главу 11), так как структура struct bioработает только со страницами физической памяти, а не с указателями.
• Структура bioможет представлять как обычные страничные операции ввода- вывода, так и операции непосредственного (direct) ввода-вывода (т.е. те, которые не проходят через страничный кэш; страничный кэш обсуждается в главе 15).
• Структура bioпозволяет легко выполнять операции блочного ввода-вывода типа распределения-аккумуляции (scatter-gather), в которых данные находятся в нескольких страницах физической памяти.
• Структура bioзначительно проще заголовка буфера, потому что она содержит только минимум информации, необходимой для представления операции блочного ввода-вывода, а не информацию, которая связана с самим буфером.
Тем не менее заголовки буферов все еще необходимы для функций, которые выполняют отображение дисковых блоков на страницы физической памяти. Структура bioне содержит никакой информации о состоянии буфера, это просто массив векторов, которые описывают один или более сегментов данных одной операции блочного ввода-вывода, плюс соответствующая дополнительная информация. Структура buffer_headнеобходима для хранения информации о буферах. Применение двух отдельных структур позволяет сделать размер обеих этих структур минимальным.
Очереди запросов
Для блочных устройств поддерживаются очереди запросов ( request queue ), в которых хранятся ожидающие запросы на выполнение операций блочного ввода-вывода. Очередь запросов представляется с помощью структуры request_queue, которая определена в файле . Очередь запросов содержит двухсвязный список запросов и соответствующую управляющую информацию. Запросы добавляются в очередь кодом ядра более высокого уровня, таким как файловые системы. Пока очередь запросов не пуста, драйвер блочного устройства, связанный с очередью, извлекает запросы из головы очереди и отправляет их на соответствующее блочное устройство. Каждый элемент списка запросов очереди— это один запрос, представленный с помощью структуры struct request.
Запросы
Отдельные запросы представляются с помощью структуры struct request, которая тоже определена в файле . Каждый запрос может состоять из более чем одной структуры bio, потому что один запрос может содержать обращение к нескольким смежным дисковым блокам. Обратите внимание, что хотя блоки на диске и должны быть смежными, данные этих блоков не обязательно должны быть смежными в физической памяти — каждая структура bioможет содержать несколько сегментов (вспомните, сегменты — это непрерывные участки памяти, в которых хранятся данные блока), а запрос может состоять из нескольких структур bio.
Интервал:
Закладка:


