Роберт Лав - Разработка ядра Linux

- Название:Разработка ядра Linux
- Автор:
- Жанр:
- Издательство:Издательский дом Вильямс
- Год:2006
- Город:Москва
- ISBN:5-8459-1085-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роберт Лав - Разработка ядра Linux краткое содержание
В книге детально рассмотрены основные подсистемы и функции ядер Linux серии 2.6, включая особенности построения, реализации и соответствующие программны интерфейсы. Рассмотренные вопросы включают: планирование выполнения процессов, управление временем и таймеры ядра, интерфейс системных вызовов, особенности адресации и управления памятью, страничный кэш, подсистему VFS, механизмы синхронизации, проблемы переносимости и особенности отладки. Автор книги является разработчиком основных подсистем ядра Linux. Ядро рассматривается как с теоретической, так и с прикладной точек зрения, что может привлечь читателей различными интересами и потребностями.
Книга может быть рекомендована как начинающим, так и опытным разработчикам программного обеспечения, а также в качестве дополнительных учебных материалов.
Разработка ядра Linux - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
unsigned short pig; /* 2 байт */
char fox; /* 1 байт */
u8 __pad1; /* 1 байт */
};
Переменные заполнения вводятся для того, чтобы обеспечить естественное выравнивание всех элементов структуры. Первая переменная заполнения вводит дополнительные затраты памяти для того, чтобы разместить поле catна границе 4-байтового адреса. Вторая переменная используется для выравнивания размера самой структуры. Дополнительный байт гарантирует, что размер структуры будет кратен четырем байтам и что каждый элемент массива таких структур будет иметь естественное выравнивание.
Следует обратить внимание, что выражение sizeof (foo_struct)равно значению 12 для любого экземпляра этой структуры на большинстве 32-разрядных аппаратных платформ. Компилятор языка С автоматически добавляет элементы заполнения, чтобы гарантировать необходимое выравнивание.
Часто имеется возможность переставить поля структуры так, чтобы избежать необходимости заполнения. Это позволяет получить правильно выровненные данные без введения дополнительных элементов заполнения и, соответственно, структуру меньшего размера.
struct animal struct {
unsigned long cat; /* 4 байта */
unsigned short pig; /* 2 байта */
char dog; /* 1 байт */
char fox; /* 1 байт */
};
Эта структура данных имеет размер 8 байт. Однако не всегда существует возможность перестановки элементов структуры местами и изменения определения структуры. Например, если структура поставляется как часть стандарта, или уже используется в существующем коде, то порядок следования полей менять нельзя. Иногда, по некоторым причинам, может потребоваться специальный порядок следования полей структуры, например специальное выравнивание переменных для оптимизации попадания в кэш. Заметим, что, согласно стандарту ANSI С, компилятор никогда не должен менять порядок следования полей в структурах [95] Если бы компилятор имел возможность изменять порядок следования нолей структуры данных, то любой существующий код, который уже использует эту структуру, мог бы испортить данные. В языке программирования С функции вычисляют положение полей просто путем введения смещений от начального адреса структуры в памяти.
данных — этим правом обладает только программист.
Разработчики ядра должны учитывать особенности заполнения при обмене структурами данных: передача структур по сети или непосредственное сохранение на диск, потому что необходимое заполнение может быть разным для различных аппаратных платформ. Это одна из причин, по которой в языке программирования С нет оператора сравнения структур. Память, которая используется для заполнения структур данных, может содержать случайную информацию, что делает невозможным побайтовое сравнение структур. Разработчики языка, программирования С правильно сделали, что оставили решение задачи сравнения структур на усмотрение программиста, который может создавать свои функции сравнения в каждом конкретном случае, чтобы использовать особенности построения конкретных структур.
Порядок следования байтов
Порядок следования байтов ( byte ordering ) — это порядок, согласно которому байты расположены в машинном слове. Для разных процессоров может использоваться один из двух типов нумерации байтов в машинном слове: наименее значимый (самый младший) байт является либо самым первым (самым левым, left-most), либо самым последним (самым правым, right-most) в слове. Порядок байтов называется обратным ( big-endian ), если наиболее значимый (самый старший) байт хранится первым, а за ним идут байты в порядке убывания значимости. Порядок байтов называется прямым ( little-endian ), если наименее значимый (самый младший) байт хранится первым, а за ним следуют байты в порядке возрастания значимости.
Даже не пытайтесь основываться на каких-либо предположениях о порядке следования байтов при написании кода ядра (конечно, если код не предназначен для какой-либо конкретной аппаратной платформы). Операционная система Linux поддерживает аппаратные платформы с обоими порядками байтов, включая и те машины, на которых используемый порядок байтов можно сконфигурировать на этапе загрузки системы, а общий код должен быть совместим с любым порядком байтов.
На рис. 19.1 показан пример обратного порядка следования байтов, а на рис. 19.2 — прямого порядка следования байтов.
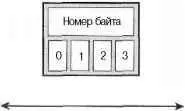
Рис. 19.1. Обратный (big-endian) порядок следования байтов
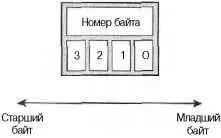
Рис. 19.2. Прямей (little-endian) порядок следования байтов
Аппаратная платформа i386 использует прямой (little-endian) порядок байтов. Большинство других аппаратных платформ обычно использует обратный (big-endian) порядок.
Рассмотрим, что эти типы кодирования обозначают на практике и как выглядит двоичное представление числа 1027, которое хранится в виде четырехбайтового целочисленного типа данных.
00000000 00000000 00000100 00000011
Внутренние представления этого числа в памяти при использовании прямого и обратного порядка байтов отличаются, как это показано в табл. 19.3.
Таблица 19.3. Расположение данных в памяти для разных порядков следования байтов
| Адрес | Обратный порядок | Прямой порядок |
|---|---|---|
| 0 | 00000000 | 00000011 |
| 1 | 00000000 | 00000100 |
| 2 | 00000100 | 00000000 |
| 3 | 00000011 | 00000000 |
Обратите внимание на то, что для аппаратной платформы с обратным порядком байтов самый старший байт записывается в самый минимальный адрес памяти.
И наконец, еще один пример — фрагмент кода, который позволяет определить порядок байтов для той аппаратной платформы, на которой он выполняется.
int x = 1;
if (*(char*)&x == 1)
/* прямой порядок */
else
/* обратный порядок */
Этот пример работает как в ядре, так и в пространстве пользователя.
История терминов big-endian и little-endian
Термины big-endian и little-endian заимствованы из сатирического романа Джонатана Свифта "Путешествие Гулливера", который был издан в 1726 году. В этом романс наиболее важной политической проблемой народа лилипутов была проблема, с какого конца следует разбивать яйцо: с тупого (big) или острого (little). Тех, кто предпочитал тупой конец называли "тупоконечниками" (big-endian), тех же, кто предпочитал острый конец, называли "остроконечниками" (little-endian).
Аналогия между дебатами лилипутов и спорами о том, какой порядок байтов лучше, говорит о том, что это вопрос больше политический, чем технический.
Читать дальшеИнтервал:
Закладка:


