Роберт Лав - Разработка ядра Linux

- Название:Разработка ядра Linux
- Автор:
- Жанр:
- Издательство:Издательский дом Вильямс
- Год:2006
- Город:Москва
- ISBN:5-8459-1085-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роберт Лав - Разработка ядра Linux краткое содержание
В книге детально рассмотрены основные подсистемы и функции ядер Linux серии 2.6, включая особенности построения, реализации и соответствующие программны интерфейсы. Рассмотренные вопросы включают: планирование выполнения процессов, управление временем и таймеры ядра, интерфейс системных вызовов, особенности адресации и управления памятью, страничный кэш, подсистему VFS, механизмы синхронизации, проблемы переносимости и особенности отладки. Автор книги является разработчиком основных подсистем ядра Linux. Ядро рассматривается как с теоретической, так и с прикладной точек зрения, что может привлечь читателей различными интересами и потребностями.
Книга может быть рекомендована как начинающим, так и опытным разработчикам программного обеспечения, а также в качестве дополнительных учебных материалов.
Разработка ядра Linux - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Из соображений производительности и по историческим причинам — в основном, для совместимости с уже существующим кодом ядра — разработчики ядра предпочли оставить тип переменной jiffies— unsigned long. Для решения проблемы пришлось немного подумать и применить возможности компоновщика.
Как уже говорилось, переменная jiffiesопределяется в следующем виде и имеет тип unsigned long.
extern unsigned long volatile jiffies;
Вторая переменная определяется в файле в следующем виде.
extern u64 jiffies_64;
Директивы компоновщика ld(1), которые используются для сборки главного образа ядра (для аппаратной платформы x86 описаны в файле arch/i386/kernel/vmlinux.lds.S), указывают компоновщику, что переменную jiffiesнеобходимо совместить с началом переменной jiffies_64.
jiffies = jiffies_64;
Следовательно, переменная jiffies— это просто 32 младших разряда полной 64-разрядной переменной jiffies_64. Так как в большинстве случаев переменная jiffiesиспользуется для измерения промежутков времени, то для большей части кода существенными являются только младшие 32 бит.
В случае применения 64-разрядного значения, переполнение не может возникнуть за время существования чего-либо. В следующем разделе будут рассмотрены проблемы, связанные с переполнением (хотя переполнение счетчика импульсов системного таймера и не желательно, но это вполне нормальное и ожидаемое событие). Код, который используется для управления ходом времени, использует все 64 бит, и это предотвращает возможность переполнения 64-разрядного значения. На рис. 10.1 показана структура переменных jiffiesи jiffies_64.
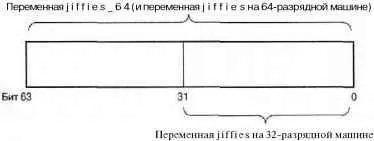
Рис. 10.1. Структура переменных jiffiesи jiffies_64
Код, который использует переменную jiffies, просто получает доступ к тридцати двум младшим битам переменной jiffies_64. Функция get_jiffies_64()может быть использована для получения полного 64-разрядного значения [57] Необходима специальная функция, так как на 32-разрядных аппаратных платформах нельзя атомарно обращаться к двум машинным словам 64-разрядного значения, Специальная функция, перед тем как считать значение, блокирует счетчик импульсов системного таймера с помощью блокировки xtime_lock .
. Такая необходимость возникает редко, следовательно большая часть кода просто продолжает считывать младшие 32 разряда непосредственно из переменной jiffies.
На 64-разрядных аппаратных платформах переменные jiffies_64и jiffiesпросто совпадают. Код может либо непосредственно считывать значение переменной jiffies, либо использовать функцию get_jiffies_64(), так как оба этих способа позволяют получить аналогичный эффект.
Переполнение переменной jiffies
Переменная jiffies, так же как и любое целое число языка программирования С, после достижения максимально возможного значения переполняется. Для 32-разрядного беззнакового целого числа максимальное значение равно 2³²- 1. Поэтому перед тем как счетчик импульсов системного таймера переполнится, должно прийти 4294967295 импульсов таймера. Если значение счетчика равно этому значению и счетчик увеличивается на 1, то значение счетчика становится равным нулю.
Рассмотрим пример переполнения.
unsigned long timeout = jiffies + HZ/2; /* значение лимита времени
равно 0.5 с */
/* выполним некоторые действия и проверим, не слишком ли это много
заняло времени ... */
if (timeout < jiffies) {
/* мы превысили лимит времени — это ошибка ... */
} else {
/* мы не превысили лимит времени — это хорошо ... */
}
Назначение этого участка кода — установить лимит времени до наступления некоторого события в будущем, а точнее полсекунды от текущего момента. Код может продолжить выполнение некоторой работы — возможно, записать некоторые данные в аппаратное устройство и ожидать ответа. После выполнения, если весь процесс превысил лимит установленного времени, код соответственным образом обрабатывает ошибку.
В данном примере может возникнуть несколько потенциальных проблем, связанных с переполнением. Рассмотрим одну из них. Что произойдет, если переменная jiffiesпереполнится и снова начнет увеличиваться с нуля после того, как ей было присвоено значение переменной timeout? При этом условие гарантированно не выполнится, так как значение переменной jiffiesбудет меньше, чем значение переменной timeout, хотя логически оно должно быть больше. По идее значение переменной jiffiesдолжно быть огромным числом, всегда большим значения переменной timeout. Так как эта переменная переполнилась, то теперь ее значение стало очень маленьким числом, которое, возможно, отличается от нуля на несколько импульсов таймера. Из-за переполнения результат выполнения оператора ifменяется на противоположный!
К счастью, ядро предоставляет четыре макроса для сравнения двух значений счетчика импульсов таймера, которые корректно обрабатывают переполнение счетчиков. Они определены в файле следующим образом.
#define time_after(unknown, known) ((long)(known) - (long)(unknown) < 0)
#define time_before(unknown, known) \
((long) (unknown) - (long) (known) < 0)
#define time_after_eq(unknown, known) \
((long)(unknown) - (long) (known) >= 0)
#define \
time_before_eq(unknown, known) ((long)(known) - (long) (unknown) >= 0)
Параметр unknown— это обычно значение переменной jiffies, а параметр known — значение, с которым его необходимо сравнить.
Макрос time_after(unknown, known)возвращает значение true, если момент времени unknown происходит после момента времени known, в противном случае возвращается значение false. Макрос time_before(unknown, known)возвращает значение true, если момент времени unknownпроисходит раньше, чем момент времени known, в противном случае возвращается значение false. Последние два макроса работают аналогично первым двум, за исключением того, что возвращается значение "истинно", если оба параметра равны друг другу.
Версия кода из предыдущего примера, которая предотвращает ошибки, связанные с переполнением, будет выглядеть следующим образом.
unsigned long timeout = jiffies + HZ/2; /* значение лимита времени
равно 0.5 с */
/* выполним некоторые действия и проверим, не слишком ли это много
заняло времени ... */
if (time_after(jiffies, timeout}) {
/* мы превысили лимит времени — это ошибка ... */
} else {
/* мы не превысили лимит времени — это хорошо ... */
}
Если любопытно, каким образом эти макросы предотвращают ошибки, связанные с переполнением, то попробуйте подставить различные значения параметров. А затем представьте, что один из параметров переполнился, и посмотрите, что при этом произойдет.
Читать дальшеИнтервал:
Закладка:


