Роберт Лав - Разработка ядра Linux

- Название:Разработка ядра Linux
- Автор:
- Жанр:
- Издательство:Издательский дом Вильямс
- Год:2006
- Город:Москва
- ISBN:5-8459-1085-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роберт Лав - Разработка ядра Linux краткое содержание
В книге детально рассмотрены основные подсистемы и функции ядер Linux серии 2.6, включая особенности построения, реализации и соответствующие программны интерфейсы. Рассмотренные вопросы включают: планирование выполнения процессов, управление временем и таймеры ядра, интерфейс системных вызовов, особенности адресации и управления памятью, страничный кэш, подсистему VFS, механизмы синхронизации, проблемы переносимости и особенности отладки. Автор книги является разработчиком основных подсистем ядра Linux. Ядро рассматривается как с теоретической, так и с прикладной точек зрения, что может привлечь читателей различными интересами и потребностями.
Книга может быть рекомендована как начинающим, так и опытным разработчикам программного обеспечения, а также в качестве дополнительных учебных материалов.
Разработка ядра Linux - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Одна из наибольших проблем, связанных со списком свободных ресурсов в ядре, это то, что над ними нет никакого централизованного контроля. Когда ощущается недостаток свободной памяти, нет никакой возможности взаимодействовать между ядром и всеми списками свободных ресурсов, которые в такой ситуации должны уменьшить размер своего кэша, чтобы освободить память. В ядре нет никакой информации о случайно созданных списках свободных ресурсов. Для исправления положения и для универсальности кода ядро предоставляет уровень слябового распределения памяти (slab layer), который также называется просто слябовым распределителем памяти (slab allocator). Уровень слябового распределения памяти выполняет функции общего уровня кэширования структур данных.
Концепции слябового распределения памяти впервые были реализованы в операционной системе SunOS 5.4 фирмы Sun Microsystems [65] И позже документированы в работе Bonwirk J. "The Slab Allocator: An Object-Caching Kernel Memory Allocator," USENIX, 1994.
. Для уровня кэширования структур данных в операционной системе Linux используется такое же название и похожие особенности реализации.
Уровень слябового распределения памяти служит для достижения следующих целей.
• Часто используемые структуры данных, скорее всего, будут часто выделяться и освобождаться, поэтому их следует кэшировать.
• Частые операции выделения и освобождения памяти могут привести к фрагментации памяти (к невозможности найти большие участки физически однородной памяти). Для предотвращения этого, кэшированные списки свободных ресурсов организованы непрерывным образом в физической памяти. Так как структуры данных возвращаются снова в список свободных ресурсов, то в результате никакой фрагментации не возникает.
• Список свободных ресурсов обеспечивает улучшенную производительность при частых выделениях и освобождениях объектов, так как освобожденные объекты сразу же готовы для нового выделения.
• Если распределитель памяти может использовать дополнительную информацию, такую как размер объекта, размер страницы памяти и общий размер кэша, то появляется возможность принимать в критических ситуациях более интеллектуальные решения.
• Если кэш организован, как связанный с определенным процессором (т.е. для каждого процессора в системе используется свой уникальный отдельный кэш), то выделение и освобождение структур данных может выполняться без использования SMP-блокировок.
• Если распределитель памяти рассчитан на доступ к неоднородной памяти (Non-Uniform Memory Access NUMA), то появляется возможность выделения памяти с того же узла (node), на котором эта память запрашивается.
• Хранимые объекты могут быть " окрашены ", чтобы предотвратить отображение разных объектов на одни и те же строки системного кэша.
Уровень слябового распределения памяти в ОС Linux был реализован с учетом указанных принципов.
Устройство слябового распределителя памяти
Уровень слябового распределения памяти делит объекты на группы, которые называются кэшами ( cache ). Разные кэши используются для хранения объектов различных типов. Для каждого типа объектов существует свой уникальный кэш. Например, один кэш используется для дескрипторов процессов (список свободных структур struct task_struct), а другой — для индексов файловых систем ( struct inode). Интересно, что интерфейс kmalloc()построен на базе уровня слябового распределения памяти и использует семейство кэшей общего назначения.
Далее кэши делятся на слябы (буквально slab — однородная плитка, отсюда и название всей подсистемы). Слябы занимают одну или несколько физически смежных страниц памяти. Обычно сляб занимает только одну страницу памяти. Каждый кэш может содержать несколько слябов.
Каждый сляб содержит некоторое количество объектов , которые представляют собой кэшируемые структуры данных. Каждый сляб может быть в одном из трех состояний: полный (full), частично заполненный (partial) и пустой (empty). Полный сляб не содержит свободных объектов (все объекты сляба выделены для использования). Частично заполненный сляб содержит часть выделенных и часть свободных объектов. Когда некоторая часть ядра запрашивает новый объект, то этот запрос удовлетворяется из частично заполненного сляба, если такой существует. В противном случае запрос выполняется из пустого сляба. Если пустого сляба не существует, то он создается. Очевидно, что полный сляб никогда не может удовлетворить запрос, поскольку в нем нет свободных объектов. Такая политика уменьшает фрагментацию памяти.
В качестве примера рассмотрим структуры inode, которые являются представлением в оперативной памяти индексов дисковых файлов (см. главу 12). Эти структуры часто создаются и удаляются, поэтому есть смысл управлять ими с помощью слябового распределителя памяти. Структуры struct inodeвыделяются из кэша inode_cachep(такое соглашение по присваиванию названий является стандартом). Этот кэш состоит из одного или более слябов, скорее всего слябов много, поскольку много объектов. Каждый сляб содержит максимально возможное количество объектов типа struct inode. Когда ядро выделяет новую структуру типа struct inode, возвращается указатель на уже выделенную, но не используемую структуру из частично заполненного сляба или, если такого нет, из пустого сляба. Когда ядру больше не нужен объект типа inode, то слябовый распределитель памяти помечает этот объект как свободный. На рис. 11.1 показана диаграмма взаимоотношений между кэшами, слябами и объектами.
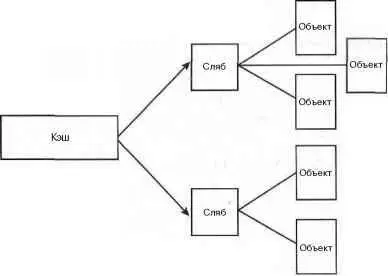
Рис. 11.1. Взаимоотношения между кэшами, слябами и объектами
Каждый кэш представляется структурой kmem_cache_s. Эта структура содержит три списка slab_full, slab_partialи slab_empty, которые хранятся в структуре kmem_list3. Эти списки содержат все слябы, связанные с данным кэшем. Каждый сляб представлен следующей структурой struct slab, которая является дескриптором сляба.
struct slab {
struct list head list; /* список полных, частично заполненных
или пустых слябов */
unsigned long colouroff; /* смещение для окрашивания слябов */
void *s_mem; /* первый объект сляба */
unsigned int inuse; /* количество выделенных объектов */
kmem_bufctl_tfree; /* первый свободный объект, если есть */
};
Дескриптор сляба выделяется или за пределами сляба, в кэше общего назначения, или в начале самого сляба. Дескриптор хранится внутри сляба, либо если общий размер сляба достаточно мал, либо если внутри самого сляба остается достаточно места, чтобы разместить дескриптор.
Читать дальшеИнтервал:
Закладка:


