Роберт Лав - Разработка ядра Linux

- Название:Разработка ядра Linux
- Автор:
- Жанр:
- Издательство:Издательский дом Вильямс
- Год:2006
- Город:Москва
- ISBN:5-8459-1085-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роберт Лав - Разработка ядра Linux краткое содержание
В книге детально рассмотрены основные подсистемы и функции ядер Linux серии 2.6, включая особенности построения, реализации и соответствующие программны интерфейсы. Рассмотренные вопросы включают: планирование выполнения процессов, управление временем и таймеры ядра, интерфейс системных вызовов, особенности адресации и управления памятью, страничный кэш, подсистему VFS, механизмы синхронизации, проблемы переносимости и особенности отладки. Автор книги является разработчиком основных подсистем ядра Linux. Ядро рассматривается как с теоретической, так и с прикладной точек зрения, что может привлечь читателей различными интересами и потребностями.
Книга может быть рекомендована как начинающим, так и опытным разработчикам программного обеспечения, а также в качестве дополнительных учебных материалов.
Разработка ядра Linux - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Сейчас нет строгой необходимости где-либо использовать новый интерфейс работы с данными, которые связаны с процессорами. Вполне можно организовать такую работу вручную (на основании массива, как было рассказано ранее), если при этом запрещается вытеснение кода в режиме ядра. Тем не менее новый интерфейс более простой в использовании и, возможно, позволит в будущем выполнять дополнительные оптимизации. Если вы собираетесь использовать в своем коде данные, связанные с процессорами, то лучше использовать новый интерфейс. Единственный недостаток нового интерфейса — он не совместим с более ранними версиями ядер.
Какой способ выделения памяти необходимо использовать
Если необходимы смежные страницы физической памяти, то нужно использовать один из низкоуровневых интерфейсов выделения памяти, или функцию kmalloc(). Это стандартный способ выделения памяти в ядре, и, скорее всего, в большинстве случаев следует использовать именно его. Необходимо вспомнить, что два наиболее часто встречающихся флага, которые передаются этой функции, это флаги GFP_ATOMICи GFP_KERNEL. Для высокоприоритетных операций выделения памяти, которые не переводят процесс в состояние ожидания, необходимо указывать флаг GFP_ATOMIC. Это обязательно для обработчиков прерываний и других случаев, когда нельзя переходить в состояние ожидания. В коде, который может переходить в состояние ожидания, как, например код, выполняющийся в контексте процесса и не удерживающий спин-блокировку, необходимо использовать флаг GFP_KERNEL. Такой флаг указывает, что должна выполняться операция выделения памяти, которая при необходимости может перейти в состояние ожидания для получения необходимой памяти.
Если есть необходимость выделить страницы верхней памяти, то следует использовать функцию alloc_pages(). Функция alloc_pages()возвращает структуру struct page, а не логический адрес. Поскольку страницы верхней памяти могут не отображаться в адресное пространство ядра, единственный способ доступа к этой памяти — через структуру struct page. Для получения "настоящего" указателя на область памяти необходимо использовать функцию kmap(), которая позволяет отобразить верхнюю память в логическое адресное пространство ядра.
Если нет необходимости в физически смежных страницах памяти, а необходима только виртуально непрерывная область памяти, то следует использовать функцию vmalloc()(также следует помнить о небольшой потере производительности при использовании функции vmalloc()по сравнению с функцией kmalloc()). Функция vmalloc()выделяет область памяти, которая содержит только виртуально смежные страницы, но не обязательно физически смежные. Это выполняется почти так же, как и в программах пользователя путем отображения физически несмежных участков памяти в логически непрерывную область памяти.
Если необходимо создавать и освобождать много больших структур данных, то следует рассмотреть возможность построения слябового кэша. Уровень слябового распределения памяти позволяет поддерживать кэш объектов (список свободных объектов), уникальный для каждого процессора, который может значительно улучшить производительность операций выделения и освобождения объектов. Вместо того чтобы часто выделять и освобождать память, слябовый распределитель сохраняет кэш уже выделенных объектов. При необходимости получения нового участка памяти для хранения структуры данных, уровню слябового распределения часто нет необходимости выделять новые страницы памяти, вместо этого можно просто возвращать объект из кэша.
Глава 12
Виртуальная файловая система
Виртуальная файловая система (Virtual File System), иногда называемая виртуальным файловым коммутатором ( Virtual File Switch ) или просто VFS , — это подсистема ядра, которая реализует интерфейс пользовательских программ к файловой системе. Все файловые системы зависят от подсистемы VFS, что позволяет не только сосуществовать разным файловым системам, но и совместно функционировать. Это также дает возможность использовать стандартные системные вызовы для чтения и записи данных на различные файловые системы, которые находятся на различных физических носителях, как показано на рис. 12.1.
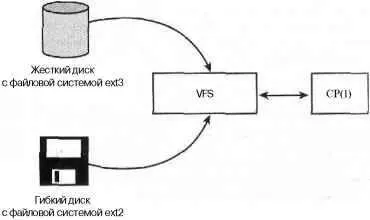
Рис. 12.1. Подсистема VFS в действии: использование команды cp(1)для копирования данных с жесткого диска, на котором монтируется файловая система, ext3, на гибкий диск, на котором монтируется файловая система ext2
Общий интерфейс к файловым системам
Подсистема VFS — это связующее звено, которое позволяет таким системным вызовам, как open(), read()и write(), работать независимо от файловой системы и физической среды носителя информации. Сегодня это может не впечатлять, поскольку такая возможность принимается как должное. Тем не менее сделать так, чтобы общие системные вызовы работали для всех поддерживаемых файловых систем и физических сред хранения данных, — задача не тривиальная. Более того, эти системные вызовы позволяют выполнять операции между различными файловыми системами и различными физическими носителями — мы можем копировать и перемещать данные с одной файловой системы на другую с помощью стандартных системных вызовов. В старых операционных системах (например, DOS) таких возможностей не было. Любые операции доступа к "неродным" файловым системам требовали использования специальных утилит. Сейчас такие возможности существуют, потому что все современные операционные системы, включая Linux, абстрагируют доступ к файловым системам с помощью виртуального интерфейса, который дает возможность совместной работы с данными и обобщенного доступа к данным. В операционной системе Linux может появиться поддержка новых типов файловых систем или новых физических средств хранения данных, при этом нет необходимости переписывать или перекомпилировать существующие программы.
Уровень обобщенной файловой системы
Общий интерфейс для всех типов файловых систем возможен только благодаря тому, что в ядре реализован обобщающий уровень, который скрывает низкоуровневый интерфейс файловых систем. Данный обобщающий уровень позволяет операционной системе Linux поддерживать различные файловые системы, даже если эти файловые системы существенно отличаются друг от друга своими функциями и особенностями работы. Это в свою очередь становится возможным благодаря тому, что подсистема VFS реализует общую файловую модель, которая в состоянии представить общие функции и особенности работы потенциально возможных файловых систем. Конечно, эта модель имеет уклон в сторону файловых систем в стиле Unix (что представляют собой файловые системы в стиле Unix, будет рассказано в следующем разделе). Несмотря на это в ОС Linux поддерживается довольно большой диапазон различных файловых систем.
Читать дальшеИнтервал:
Закладка:


