Марейн Хавербеке - Выразительный JavaScript

- Название:Выразительный JavaScript
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:978-1593275846
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Марейн Хавербеке - Выразительный JavaScript краткое содержание
В процессе чтения вы познакомитесь с основами программирования и, в частности, языка JavaScript, а также выполните несколько небольших проектов. Один из самых интересных проектов — создание своего языка программирования.
Выразительный JavaScript - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Если нам надо принудить совпадение взять всю строку целиком, мы используем метки ^и $. ^совпадает с началом строки, а $– с концом. Поэтому /^\d+$/совпадает со строкой, состоящей только из одной или нескольких цифр, /^!/совпадает со строкой, начинающейся с восклицательного знака, а /x^/не совпадает ни с какой строчкой (перед началом строки не может быть x).
Если, с другой стороны, нам просто надо убедиться, что дата начинается и заканчивается на границе слова, мы используем метку \b. Границей слова может быть начало или конец строки, или любое место строки, где с одной стороны стоит алфавитно-цифровой символ \w, а с другой – не алфавитно-цифровой.
console.log(/cat/.test("concatenate"));
// → true
console.log(/\bcat\b/.test("concatenate"));
// → false
Отметим, что метка границы не представляет из себя символ. Это просто ограничение, обозначающее, что совпадение происходит только если выполняется определённое условие.
Шаблоны с выбором
Допустим, надо выяснить, содержит ли текст не просто номер, а номер, за которым следует pig, cow, или chicken в единственном или множественном числе.
Можно было бы написать три регулярки и проверить их по очереди, но есть способ лучше. Символ |обозначает выбор между шаблонами слева и справа от него. И можно сказать следующее:
var animalCount = /\b\d+ (pig|cow|chicken)s?\b/;
console.log(animalCount.test("15 pigs"));
// → true
console.log(animalCount.test("15 pigchickens"));
// → false
Скобки ограничивают часть шаблона, к которой применяется |, и можно поставить много таких операторов друг за другом, чтобы обозначить выбор из более чем двух вариантов.
Механизм поиска
Регулярные выражения можно рассматривать как блок-схемы. Следующая диаграмма описывает последний животноводческий пример.
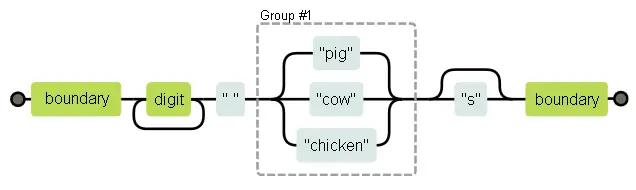
Выражение совпадает со строкой, если можно найти путь с левой части диаграммы в правую. Мы запоминаем текущее положение в строке, и каждый раз, проходя прямоугольник, проверяем, что часть строки сразу за нашим положением в ней совпадает с содержимым прямоугольника.
Значит, проверка совпадения нашей регулярки в строке "the 3 pigs"при прохождении по блок-схеме выглядит так:
• на позиции 4 есть граница слова, и проходим первый прямоугольник
• начиная с 4 позиции находим цифру, и проходим второй прямоугольник
• на позиции 5 один путь замыкается назад перед вторым прямоугольником, а второй проходит далее к прямоугольнику с пробелом. У нас пробел, а не цифра, и мы выбираем второй путь.
• теперь мы на позиции 6, начало “pigs”, и на тройном разветвлении путей. В строке нет “cow” или “chicken”, зато есть “pig”, поэтому мы выбираем этот путь.
• на позиции 9 после тройного разветвления, один путь обходит “s” и направляется к последнему прямоугольнику с границей слова, а второй проходит через “s”. У нас есть “s”, поэтому мы идём туда.
• на позиции 10 мы в конце строки, и совпасть может только граница слова. Конец строки считается границей, и мы проходим через последний прямоугольник. И вот мы успешно нашли наш шаблон.
В принципе, работают регулярные выражения следующим образом: алгоритм начинает в начале строки и пытается найти совпадение там. В нашем случае там есть граница слова, поэтому он проходит первый прямоугольник – но там нет цифры, поэтому на втором прямоугольнике он спотыкается. Потом он двигается ко второму символу в строке, и пытается найти совпадение там… И так далее, пока он не находит совпадение или не доходит до конца строки, в таком случае совпадение не найдено.
Откаты
Регулярка /\b([01]+b|\d+|[\da-f]h)\b/совпадает либо с двоичным числом, за которым следует b, либо с десятичным числом без суффикса, либо шестнадцатеричным (цифры от 0 до 9 или символы от a до f), за которым идёт h. Соответствующая диаграмма:
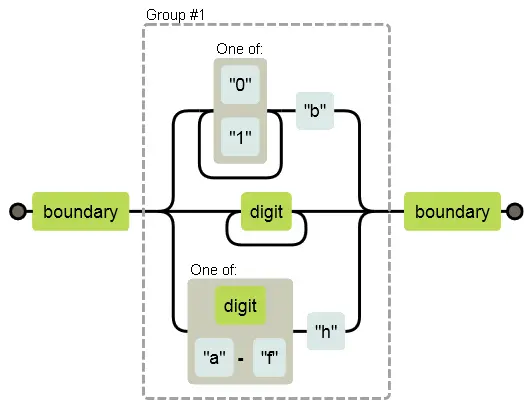
В поисках совпадения может случиться, что алгоритм пошёл по верхнему пути (двоичное число), даже если в строке нет такого числа. Если там есть строка “103”, например, понятно, что только достигнув цифры 3 алгоритм поймёт, что он на неправильном пути. Вообще строка совпадает с регуляркой, просто не в этой ветке.
Тогда алгоритм совершает откат. На развилке он запоминает текущее положение (в нашем случае, это начало строки, сразу после границы слова), чтобы можно было вернуться назад и попробовать другой путь, если выбранный не срабатывает. Для строки “103”после встречи с тройкой он вернётся и попытается пройти путь для десятичных чисел. Это сработает, поэтому совпадение будет найдено.
Алгоритм останавливается, как только найдёт полное совпадение. Это значит, что даже если несколько вариантов могут подойти, используется только один из них (в том порядке, в каком они появляются в регулярке).
Откаты случаются при использовании операторов повторения, таких, как +и *. Если вы ищете /^.*x/в строке "abcxe", часть регулярки .*попробует поглотить всю строчку. Алгоритм затем сообразит, что ему нужен ещё и “x”. Так как никакого “x”после конца строки нет, алгоритм попробует поискать совпадение, откатившись на один символ. После abcxтоже нет x, тогда он снова откатывается, уже к подстроке abc. И после строчки он находит xи докладывает об успешном совпадении, на позициях с 0 по 4.
Можно написать регулярку, которая приведёт ко множественным откатам. Такая проблема возникает, когда шаблон может совпасть с входными данными множеством разных способов. Например, если мы ошибёмся при написании регулярки для двоичных чисел, мы можем случайно написать что-то вроде /([01]+)+b/.
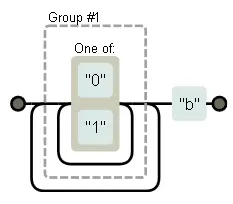
Если алгоритм будет искать такой шаблон в длинной строке из нолей и единиц, не содержащей в конце “b”, он сначала пройдёт по внутренней петле, пока у него не кончатся цифры. Тогда он заметит, что в конце нет “b”, сделает откат на одну позицию, пройдёт по внешней петле, опять сдастся, попытается откатиться на ещё одну позицию по внутренней петле… И будет дальше искать таким образом, задействуя обе петли. То есть, количество работы с каждым символом строки будет удваиваться. Даже для нескольких десятков символов поиск совпадения займёт очень долгое время.
Метод replace
У строк есть метод replace, который может заменять часть строки другой строкой.
Интервал:
Закладка:



