Елена Клещенко - ДНК и её человек [litres]
![Елена Клещенко - ДНК и её человек [litres]](/books/1080264/elena-klechenko-dnk-i-ee-chelovek-litres.webp "Обложка книги")
- Название:ДНК и её человек [litres]
- Автор:
- Жанр:
- Издательство:Литагент Альпина
- Год:2019
- Город:Москва
- ISBN:978-5-0013-9137-1
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Елена Клещенко - ДНК и её человек [litres] краткое содержание
Детективную линию продолжает рассказ о поиске преступников с помощью анализа ДНК – от Джека-потрошителя до современных маньяков и террористов. Не менее увлекательны исторические расследования: кем был Рюрик – славянином или скандинавом, много ли потомков оставил Чингисхан, приходился ли герцог Монмут сыном королю Англии. Почему специалисты уверены в точности идентификации останков Николая II и его семьи (и отчего сомневаются неспециалисты)? В заключении читатель узнает, почему нельзя изобрести биологическое оружие против определенной этнической группы, можно ли реконструировать внешность по ДНК и опасно ли выкладывать свой геном в интернет.
ДНК и её человек [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
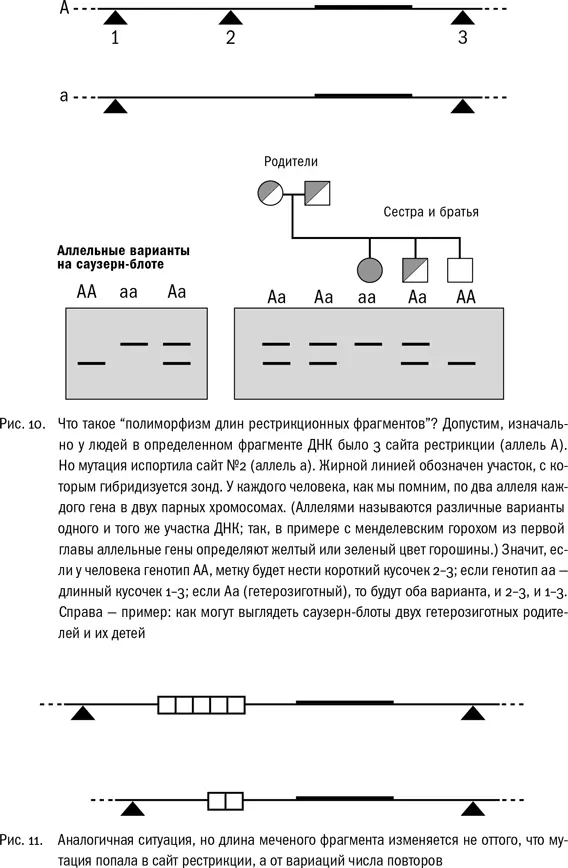
Очевидно, что в геномах у разных людей должны быть различия, но как найти эти крошечные индивидуальные различия среди миллиардов букв? Оказалось, для этого необязательно секвенировать весь геном. Можно использовать саузерн-блоттинг.
Алек Джеффрис одним из первых описал феномен полиморфизма длин рестрикционных фрагментов (restriction fragment length polymorphism, RFLP). Два образца ДНК – допустим, взятые у двух разных людей – обрабатывают одной и той же рестриктазой, потом гибридизуют отпечатки на мембране с одним и тем же зондом и получают неодинаковые картинки, длины меченых фрагментов не совпадают. Почему так происходит?
Оказалось, у некоторых людей может отсутствовать тот или иной сайт рестрикции по причине замены одного нуклеотида, например GGGCCC у них превращается в GGТCCC. Рестриктаза теперь его не узнаёт – она сурова, как поисковик программы Word, и, в отличие от Google, не делает поправок на опечатки. Если обработать рестриктазой ДНК человека с такой мутацией, то вместо двух коротких фрагментов, как у большинства людей, у него получится один длинный. И та же картина может наблюдаться у потомков этого человека.
STR и момент “эврика!”
Казалось бы, вот он, путь к изучению человеческого разнообразия. Но путь, с учетом тогдашних технических возможностей, не слишком удобный. Таких однобуквенных замен в геноме человека очень много – около 10 млн у каждого из нас. (Правильнее называть их однонуклеотидными полиморфизмами – single nucleotide polymorphism, SNP , или просто снипы ; запомним этот термин, нам с ним еще встречаться и встречаться!) Но невозможно угадать заранее, какой сайт рестрикции может быть испорчен нуклеотидной заменой у конкретного человека. “Их [SNP] трудно найти и проанализировать, и они не очень-то много говорят о разнообразии людей: ты или видишь отличие, или не видишь” , – говорил Джеффрис [14] Здесь и ниже цитируется по: https://www.lister-institute.org.uk/sir-alec-jeffreys-discusses-developments-dna-fingerprinting/ .
. Современных специалистов по ДНК-идентификации снипы очень интересуют, но тогда – нужен был другой метод. Что-то другое в геноме человека, то, что есть у всех, но при этом достаточно разнообразно и может использоваться в качестве индивидуальных характеристик.
И такие участки в геноме существуют. Теперь, после изобретения Джеффриса, кажется, будто эволюция их специально разработала для нужд судебных экспертов! Тандемные повторы ДНК – короткие участки, которые повторяются много раз, как сказка про белого бычка; тандемными они называются потому, что идут друг за другом, “голова в хвост”, в отличие от повторов диспергированных, которые друг к другу не примыкают. Возникают такие повторы, в частности, из-за “проскальзывания” ферментного комплекса по матрице при копировании ДНК (в результате участок копируется повторно) или из-за ошибок рекомбинации (обмена участками между парными хромосомами).
Хромосом у нас, как у большинства животных, двойной комплект: каждая представлена двумя копиями, одна получена от матери, другая от отца. Именно поэтому и гены в норме у нас представлены двумя копиями, не всегда идентичными – все по Грегору Менделю. А в процессе образования яйцеклеток и сперматозоидов гомологичные, или парные, хромосомы обмениваются участками – рекомбинируют. Это дополнительно разнообразит наборы наследственных признаков у потомства.
Интуитивно понятно, что число таких повторов должно быть изменчивым – где появились два или три повтора, там могут появиться и четыре, и шесть, по тем же самым причинам. К тому же если это некодирующие участки, то мутации в них не портят никаких белков и не приводят к болезням, следовательно такие мутации не отсекаются естественным отбором и могут накапливаться. Значит, можно предположить, что число тандемных повторов может быть индивидуальным признаком – у одного человека в определенном участке три повтора, у другого пять или восемь. Но это тоже приведет к полиморфизму длины фрагментов рестрикции: чем больше повторяющихся фрагментов окажется между сайтами, распознаваемыми рестриктазой, тем длиннее получится кусок.
Тандемные повторы бывают разные. Если длина повторяющегося мотива 7–60 нуклеотидов, это минисателлиты. Один из их видов – гипервариабельные минисателлиты (VNTR, variable number of tandem repeats), они расположены в некодирующих регионах и, в соответствии с названием, число их может быть различным у разных особей. Если же длина повторяющегося участка меньше, от 2 до 6 нуклеотидов, – это микросателлиты, или короткие тандемные повторы (STR, short tandem repeats). Сейчас золотым стандартом в установлении личности по ДНК считается исследование STR (потом разберемся почему), но начиналось все с VNTR. Впрочем, чтобы всех запутать, в некоторых источниках оба типа повторов называют VNTR.
А есть еще сателлитные повторы, наибольшие по размеру повторяющегося участка, – они в криминалистике не используются.
Но, чтобы получать картинки методом саузерн-блоттинга, мало полиморфизма длины фрагментов – еще нужна метка. Чем пометить полоски, содержащие повторы, чтобы сделать их видимыми? И еще хотелось бы, чтоб метка была для всех одинаковая (ее же надо готовить заранее), а рисунок полосок получался индивидуальным, своим для каждого человека.
Помощь пришла из совершенно другого проекта. В лаборатории Джеффриса изучали человеческий ген миоглобина – белка, который переносит кислород в мышцах, однако начать пришлось с гена серого тюленя. Тюлень – зверь ныряющий, кислорода ему нужно много, поэтому с его гена миоглобина активно считывается мРНК. Если выделить мРНК и синтезировать на ее матрице комплементарную ДНК (кДНК), она будет очень похожа на искомый ген. В природе у млекопитающих ДНК не синтезируется на матрице РНК, но для исследования это удобно, необходимый для этого фермент ревертазу можно позаимствовать у вирусов. А через ген тюленя, используя его как зонд, исследователи планировали выйти на ген миоглобина человека: при всем нашем внешнем несходстве с тюленями и другими зверями гены млекопитающих в целом довольно похожи.
“Подлинная история ДНК-фингерпринта началась в штаб-квартире Британской антарктической службы в Кембридже , – вспоминал профессор Джеффрис. (Вопреки названию, эта служба занимается не только Антарктикой, но и Арктикой. – Прим. авт. ) – Я взял большой кусок тюленьего мяса из их морозилки, запиравшейся на ключ, и, коротко говоря, мы получили ген миоглобина тюленя, поглядели на ген миоглобина человека – и там, внутри интрона этого гена, нашли тандемные повторы ДНК – минисателлиты”. Собственно, слово “минисателлиты” и придумали Джеффрис с соавторами.
Читать дальшеИнтервал:
Закладка:






