Array Array - Алгоритмы разума

- Название:Алгоритмы разума
- Автор:
- Жанр:
- Издательство:Наукова Думка
- Год:1979
- Город:Киев
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Array Array - Алгоритмы разума краткое содержание
Разумеется, я не смогу убедить в этом скептиков для этого нужно воспроизвести алгоритм интеллекта в программах. К сожалению, на этом пути стоят большие трудности.
Предупреждаю, что предмет исключительно сложен для понимания, поскольку лежит на стыке физиологии, психологии, техники и даже философии...
Н. Амосов
Возможно ли создать искусственный интеллект. Будет ли он способен к полноценному мышлению и творчеству. Кем предстоит ему стать — помощником или соперником человеческого разума. Эти вопросы давно уже обсуждаются многими учеными.
Свою точку зрения по ним высказывает академик АН УССР Н. М. Амосов. Автор известен своими работами в области моделирования мышления и поведения. В книге излагаются его идеи в их дальнейшем развитии. Анализируются возможные пути построения искусственного интеллекта. Подытожен опыт отдела биокибернетики Института кибернетики АН УССР по моделированию интеллекта и личности.
Рассчитана на широкий круг специалистов в области кибернетики, психологов, а также на всех интересующихся вопросами современной науки. Ответственный редактор
А. М. КАСАТКИН Редакция научно-популярной литературы
Алгоритмы разума - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
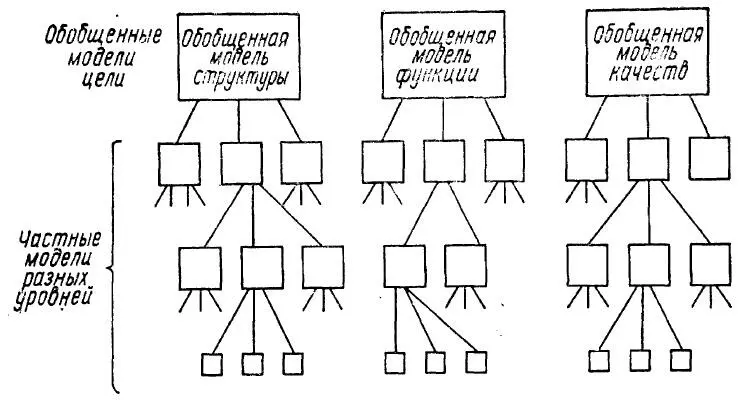
Рис. 39. Схема развертывания обобщенных моделей структуры, функций и качеств объекта цели в детальные для создания непротиворечивой модели.
Обобщенные модели цели не представляют никакой ценности, и их может создать каждый («изобрести бы машину для того-то» и т.п.). Творчество состоит в развертывании обобщенных моделей цели в детальные, причем так, чтобы они удовлетворяли главному критерию ценности, о котором говорилось. Как правило, творец действует методом перебора: спускаясь по ступеням обобщения с верхнего уровня на следующий, он перебирает уже имеющиеся в его памяти модели. Обычно перебор частных моделей начинается с главной обобщенной — со структуры, функций или качеств. Каждую выбранную частную модель проверяют по другим параметрам обобщения, при этом сразу же выбраковывается абсолютное большинство вариантов. Каждая из оставшихся моделей, которая удовлетворяет требованиям обобщения второго уровня, развертывается в более детальную модель третьего уровня и т.д., после чего снова идет проверка по другим критериям, уже детализированным до соответствующего уровня. Общий алгоритм творчества (как и планирования) хорошо представлен в конструкторском труде.
Казалось бы, раз известен такой алгоритм творчества, отчего не создавать гениальных произведений. Перебирай и перебирай, подключи к этому компьютер, если мозг работает медленно.
Есть несколько препятствий на пути к успеху творчества. Главное — великое множество деталей, которые, последовательно проходя через уровни обобщения, достигают вершины в общей модели цели. Это множество невозможно удержать в памяти, невозможно перебрать, поскольку оно включает в себя значительную часть всех моделей, накопленных человечеством. Нечего и говорить, что перебор неосуществим, если начинать «снизу» — с малых деталей. Даже опускаясь «сверху», последовательно отбрасывая целые крупные группы моделей, исключительно трудно получить необходимую структуру, если учесть, что нужно подобрать не только модели-элементы, но еще правильно их соотнести друг с другом. При этом неизвестно даже число элементов. Нет, расположение моделей по иерархии обобщения и использование алгоритма перебора отнюдь не обеспечивают легкого достижения цели.
Вторая трудность — в отсутствии необходимых деталей или, скажем, частных моделей — структурных подробностей. Их накоплено очень много и тем не менее совсем недостаточно для того, чтобы решить любую научную или техническую задачу. В познании сложного объекта одинаково важны как обобщенные модели, так и сугубо частные детали. Например, в развитии биологии огромную роль сыграло открытие того, каким образом из нуклеотидов складывается двойная спираль ДНК. Все широкие гипотезы о жизни без таких деталей не позволяют довести модели до высшего подтверждения их истинности — создания новых живых существ. Эта задача еще не решена, но подходы уже вырисовываются, например создан живой ген.
Детали добываются так же трудно, как и обобщения. Это черновая работа науки и производства.
Третья трудность — отсутствие четкости в обобщениях моделей. Это только в схеме существует иерархия обобщенности: крупные блоки, детали и пр. В действительных моделях процесс обобщения нестрого формализован и уровни обобщенности не существуют как нечто стабильное. По крайней мере, так обстоит дело в естественном сетевом интеллекте, каким является кора мозга. Правда, при создании ИИ можно задать дискретные уровни обобщения, и они помогут при переборе вариантов, но полностью не разрешат проблемы оптимума.
Переход от обобщенной модели к более детальной осуществляется по связям, которыми сформирована короткая «фраза»: обобщенная модель —> частная модель. Следовательно, в памяти алгоритмического интеллекта нужно иметь множество «словарей», фиксирующих обобщения. По ним будет осуществляться перебор-поиск частных моделей по обобщенной. В сетевом интеллекте коры мозга обобщенная модель представляется просто неясной частной моделью и связанной с ней моделью-«буквой», обозначающей действие обобщения, то есть последовательного сравнения ряда частных моделей по некоторому признаку. Пример — образ «четвероногое». Здесь обобщение произведено по признаку «четвероногость» на серии конкретных моделей четвероногих животных. Модель «четвероногое», как таковая, существует только в виде слова речи. Слово соединено связями различной проходимости с конкретными моделями — образами четвероногих животных. Такие модели имеют неодинаковую активность. Поэтому при перечислении животных с четырьмя ногами первыми вспоминаются наиболее знакомые, а затем — другие в порядке убывания проходимости связей и активности частных моделей, зависящих от частоты их использования.
Как говорилось, СУТ в сетевом интеллекте тормозит модели. Поэтому вспоминание частной модели по обобщенной, как действие перебора, иногда происходит не сразу: модели-адресаты могут оказаться сильно заторможенными, и вспомнить их не удается до тех пор, пока они не освободятся от тормозящего действия СУТ. Всем знакома эта особенность вспоминания: знаешь, что в памяти был образ или слово, иначе говоря, к нему есть линии связей, а вспомнить не можешь. Проходит время, и нужное слово всплывает в сознании само собой.
Организация памяти в алгоритмическом интеллекте — самая трудная проблема. Признаков-параметров, по которым можно обобщать модели, великое множество. Пример — те же «четвероногие». Значит, нужно много «словарей». Кроме того, внутри «словаря» необходим порядок значимости моделей, отражающий частоту их использования. Этот порядок должен периодически пересматриваться в зависимости от повторного привлечения модели в сознание. Конечно, переборы во внешней памяти компьютера — дело трудоемкое и требующее машинного времени, но положение не безнадежно, поскольку пересмотр массивов памяти возможен в интервалах между основными действиями.
Простое перечисление трудностей перебора показывает, что успешное творчество тем менее вероятно, чем выше степень обобщенности задач и чем больше количество моделей, описывающих цель. Гениальные изобретения или смелые гипотезы отличаются тем, что их творец использует модели, очень далеко отстоящие от проторенных путей поиска, такие, которые не приходят в голову при простом переборе по порядку используемости или значимости.
Все слыхали об «озарениях», когда решение трудной задачи приходит неожиданно, иногда в самое неподходящее время. В чем тут дело.
Читать дальшеИнтервал:
Закладка:




