Марина Коновалова - Экспериментальная психология: конспект лекций

- Название:Экспериментальная психология: конспект лекций
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Марина Коновалова - Экспериментальная психология: конспект лекций краткое содержание
Непосредственной сдаче экзамена или зачета по любой учебной дисциплине всегда предшествует достаточно краткий период, когда студент должен сосредоточиться, систематизировать свои знания. Выражаясь компьютерным языком, он должен «вывести информацию из долговременной памяти в оперативную», сделать ее готовой к немедленному и эффективному использованию. Специфика периода подготовки к экзамену или зачету заключается в том, что студент уже ничего не изучает (для этого просто нет времени): он лишь вспоминает и систематизирует изученное.
Содержание и структура пособия соответствуют требованиям Государственного образовательного стандарта высшего профессионального образования.
Экспериментальная психология: конспект лекций - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Мода (Мо) – это значение, наиболее часто встречающееся в выборке, т. е. значение с наибольшей частотой. Если все значения в группе встречаются одинаково часто, то считается, что моды нет. Если два соседних значения имеют одинаковую частоту и больше частоты любого другого значения, мода есть среднее этих двух значений. Если то же самое относится к двум несмежным значениям, то существует две моды, а группа оценок является бимодальной.
Обычно выборочное среднее применяется при стремлении к наибольшей точности в определении центральной тенденции. Медиана вычисляется в том случае, когда в серии есть «нетипичные» данные, резко влияющие на среднее. Мода используется в ситуациях, когда не нужна высокая точность, но важна быстрота определения меры центральной тенденции.
Вычисление всех трех показателей производится также для оценки распределения данных. При нормальном распределении значения выборочного среднего, медианы и моды одинаковы или очень близки.
Меры разброса (изменчивости) – это статистические показатели, характеризующие различия между отдельными значениями выборки. Они позволяют судить о степени однородности полученного множества, его компактности, а косвенно и о надежности полученных данных и вытекающих из них результатов. Наиболее используемые в психологических исследованиях показатели: среднее отклонение, дисперсия, стандартное отклонение.
Размах (Р) – это интервал между максимальным и минимальным значениями признака. Определяется легко и быстро, но чувствителен к случайностям, особенно при малом числе данных.
Среднее отклонение (МД) – это среднеарифметическое разницы (по абсолютной величине) между каждым значением в выборке и ее средним.
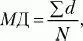
где d = |Х – М |, М – среднее выборки, X – конкретное значение, N – число значений.
Множество всех конкретных отклонений от среднего характеризует изменчивость данных, но если не взять их по абсолютной величине, то их сумма будет равна нулю и мы не получим информации об их изменчивости. Среднее отклонение показывает степень скученности данных вокруг выборочного среднего. Кстати, иногда при определении этой характеристики выборки вместо среднего (М) берут иные меры центральной тенденции – моду или медиану.
Дисперсия (D) характеризует отклонения от средней величины в данной выборке. Вычисление дисперсии позляет избежать нулевой суммы конкретных разниц (d = Х – М) не через их абсолютные величины, а через их возведение в квадрат:

где d = |Х – М|, М – среднее выборки, X – конкретное значение, N – число значений.
Стандартное отклонение (б). Из-за возведения в квадрат отдельных отклонений d при вычислении дисперсии полученная величина оказывается далекой от первоначальных отклонений и потому не дает о них наглядного представления. Чтобы этого избежать и получить характеристику, сопоставимую со средним отклонением, проделывают обратную математическую операцию – из дисперсии извлекают квадратный корень. Его положительное значение и принимается за меру изменчивости, именуемую среднеквадратическим, или стандартным, отклонением:

где d = |Х– М|, М – среднее выборки, X– конкретное значение, N – число значений.
МД, D и ? применимы для интервальных и пропорционных данных. Для порядковых данных в качестве меры изменчивости обычно берут полуквартильное отклонение (Q), именуемое еще полуквартильным коэффициентом. Вычисляется этот показатель следующим образом. Вся область распределения данных делится на четыре равные части. Если отсчитывать наблюдения начиная от минимальной величины на измерительной шкале, то первая четверть шкалы называется первым квартилем, а точка, отделяющая его от остальной части шкалы, обозначается символом Qv Вторые 25 % распределения – второй квартиль, а соответствующая точка на шкале – Q2. Между третьей и четвертой четвертями распределения расположена точка Q3. Полуквартильный коэффициент определяется как половина интервала между первым и третьим квартилями:
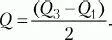
При симметричном распределении точка Q2 совпадет с медианой (а следовательно, и со средним), и тогда можно вычислить коэффициент Q для характеристики разброса данных относительно середины распределения. При несимметричном распределении этого недостаточно. Тогда дополнительно вычисляют коэффициенты для левого и правого участков:
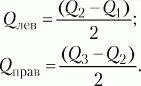
7.3. Вторичная статистическая обработка данных
К вторичным относят такие методы статистической обработки, с помощью которых на базе первичных данных выявляют скрытые в них статистические закономерности. Вторичные методы можно подразделить на способы оценки значимости различий и способы установления статистических взаимосвязей.
Способы оценки значимости различий.Для сравнения выборочных средних величин, принадлежащих к двум совокупностям данных, и для решения вопроса о том, отличаются ли средние значения статистически достоверно друг от друга, используют t-критерий Стьюдента. Его формула выглядит следующим образом:
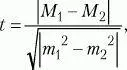
где М1, М2 – выборочные средние значения сравниваемых выборок, m1, m2 – интегрированные показатели отклонений частных значений из двух сравниваемых выборок, вычисляются по следующим формулам:
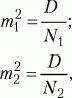
где D1, D2 – дисперсии первой и второй выборок, N1, N2 – число значений в первой и второй выборках.
После вычисления значения показателя t по таблице критических значений (см. Статистическое приложение 1), заданного числа степеней свободы ( N 1 + N 2 – 2) и избранной вероятности допустимой ошибки (0,05, 0,01, 0,02, 001 и т.д.) находят табличное значение t. Если вычисленное значение t больше или равно табличному, делают вывод о том, что сравниваемые средние значения двух выборок статистически достоверно различаются с вероятностью допустимой ошибки, меньшей или равной избранной.
Читать дальшеИнтервал:
Закладка:






