Макс Тегмарк - Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта

- Название:Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта
- Автор:
- Жанр:
- Издательство:Литагент Corpus
- Год:2019
- Город:Москва
- ISBN:978-5-17-105999-6
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Макс Тегмарк - Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта краткое содержание
Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
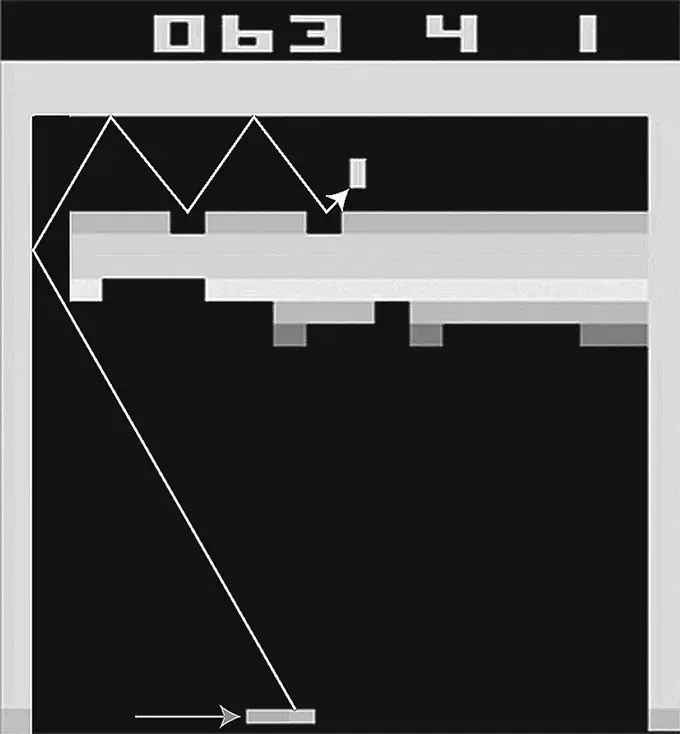
Рис. 3.1
Искусственный интеллект DeepMind учился проходить аркадную игру Breakout на платформе Atari с нуля, для чего использовались методы машинного обучения с подкреплением. Вскоре DeepMind самостоятельно открыл оптимальную стратегию: пробивать в левом краю кирпичной стены дыру и загонять в эту дыру игровой шарик, который, оказавшись в замкнутом пространстве, быстро увеличивает счет. Я добавил на этом рисунке стрелки, показывающие траектории платформы и шарика.
Поначалу AI играл ужасно: он бессмысленно толкал платформу влево и вправо, как слепой, почти каждый раз промахиваясь мимо шарика. В какой-то момент у него, казалось, возникла идея, что двигать платформу по направлению к шарику – это, наверное, правильно, но шарик все равно пролетал мимо. Мастерство AI, однако, продолжало расти с практикой, и вскоре он стал играть значительно лучше, чем я когда бы то ни было, безошибочно отбивая шарик, как бы быстро тот ни двигался. И тут-то и пришло время моей челюсти отвиснуть: AI непостижимым образом смог раскрыть знакомую мне стратегию максимизации очков: всегда целиться в верхний левый угол, чтобы, пробив дырку в кирпичной кладке, загонять шарик туда, позволяя ему там долго прыгать между тыльной стороной стены и границей игрового поля. Это действительно казалось разумным решением. Позже Демис Хассабис говорил мне, что программисты компании DeepMind не знали этого трюка, пока созданный ими искусственный интеллект не открыл им глаза. Я всем рекомендую посмотреть этот ролик, перейдя по ссылке, которую я здесь привожу {8} 8 DeepMind алгоритм глубокого машинного обучения с подкреплением позволил довольно быстро научиться играть в Breakout: https://tinyurl.com/atariai
.
В том, как все это делалось, было что-то до такой степени человеческое, что мне стало не по себе: я видел AI, у которого была цель и который достиг совершенства на пути к ней, значительно обогнав своих создателей. В предыдущей главе мы определили интеллект просто как способность достигать сложных целей, и в этом смысле AI DeepMind становился все более умным в моих глазах (хотя бы и в очень узком смысле освоения премудростей единственной игры). В первой главе мы уже встречались с тем, что специалисты по информатике называют интеллектуальными агентами: это сущности, которые собирают информацию об окружающей среде от датчиков, а затем обрабатывают эту информацию, чтобы решить, как действовать в этой среде. Хотя игровой искусственный интеллект DeepMind жил в чрезвычайно простом виртуальном мире, состоящем из кирпичей, шариков и платформы, я не мог отрицать, что этот агент был разумным.
DeepMind вскоре опубликовала и свой метод, и использованный код, объяснив, что в основе лежала очень простая, но действенная идея, получившая название глубокого обучения с подкреплением {9} 9 См. статью, в которой описывается искусственный интеллект DeepMind, совершенствующийся в играх на платформе Atari: http://tinyurl.com/ataripaper
. Обучение с подкреплением – классический метод машинного обучения, основанный на бихевиористской психологии, которая утверждает, что достижение положительного результата подкрепляет ваше стремление повторить выполненное действие, и наоборот. Словно собака, которая учится выполнять команды хозяина, опираясь на его поддержку и в надежде на угощение, искусственный интеллект DeepMind учился двигать платформу, ловя шарик, в надежде на увеличение счета. DeepMind объединила эту идею с глубоким обучением: там научили глубокую нейронную сеть, описанную в предыдущей главе, предсказывать, сколько очков в среднем заработает АI, нажимая ту или иную из доступных клавиш, и, исходя из этого и учитывая текущее состояние игры, он выбирал ту клавишу, которую нейронная сеть оценивала как наиболее перспективную.
Рассказывая о том, что поддерживает мою положительную самооценку, я включил в этот список и способность решать разнообразные не решенные до меня задачи. Интеллект, ограниченный лишь способностью научиться хорошо играть в Breakout и больше ни на что не годный, следует считать чрезвычайно узким. Для меня вся важность прорыва DeepMind заключалась в том, что глубокое обучение с подкреплением – исключительно универсальный метод. Нет сомнений, что они практиковали его же, когда их AI учился играть в сорок девять различных игр Atari и достиг уровня, при котором стал уверенно обыгрывать любых человеческих соперников в двадцать девять из них, от Pong до Boxing, Video Pinball и Space Invaders.
Не надо было долго ждать момента, когда эту идею начнут использовать для обучения AI более современным играм – с трехмерными, а не двухмерными мирами. Вскоре конкурент компании DeepMind, базирующийся в Сан-Франциско OpenAI, выпустил платформу под названием Universe, где DeepMind AI и другие интеллектуальные агенты могли совершенствоваться во взаимодействии с компьютером так же, как если бы это была игра, – орудуя мышкой, набирая что угодно на клавиатуре, открывая любое программное обеспечение, например запуская веб-браузер и роясь в интернете.
Охватывая взглядом будущее углубленного обучения с подкреплением, трудно предсказать, к чему оно может привести. Возможности метода явно не ограничиваются виртуальным миром компьютерных игр, поскольку, если вы робот, сама жизнь может рассматриваться как игра. Стюарт Рассел рассказывал мне о своем первом настоящем HS-моменте, когда он наблюдал, как его робот Big Dog поднимается по заснеженному лесному склону, изящно решая проблему координации движений конечностей, которую он сам не мог решить в течение многих лет {10} 10 Робот Биг Дог в действии: https://www.youtube.com/watch?v=W1czBcnX1Ww
. Для прохождения этого эпохального этапа в 2008 году потребовались усилия огромного количества первоклассных программистов. После описанного прорыва DeepMind не осталось причин, по которым робот не может рано или поздно воспользоваться каким-нибудь вариантом глубокого обучения с подкреплением, чтобы самостоятельно научиться ходить, без помощи людей-программистов: все, что для этого необходимо, – это система, начисляющая ему очки при достижении успеха. Роботы в реальном мире также без помощи людей-программистов могут научиться плавать, летать, играть в настольный теннис, драться и делать все остальное из почти бесконечного списка других двигательных задач. Для ускорения процесса и снижения риска где-нибудь застрять или повредить себя в процессе обучения прохождение его начальных этапов будет, вероятно, осуществляться в виртуальной реальности.
Еще одним поворотным моментом для меня стала победа созданного DeepMind искусственного интеллекта AlphaGo в матче из пяти партий в го против Ли Седоля, который на начало XXI века считался лучшим игроком в го в мире.
Читать дальшеИнтервал:
Закладка:









