Cет Cтивенс-Давидовиц - Все лгут. Поисковики, Big Data и Интернет знают о вас всё

- Название:Все лгут. Поисковики, Big Data и Интернет знают о вас всё
- Автор:
- Жанр:
- Издательство:Литагент 5 редакция
- Год:2018
- Город:Москва
- ISBN:978-5-04-090836-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Cет Cтивенс-Давидовиц - Все лгут. Поисковики, Big Data и Интернет знают о вас всё краткое содержание
Все лгут. Поисковики, Big Data и Интернет знают о вас всё - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Слова как данные
Однажды в 2004 году два молодых экономиста с опытом работы в СМИ, Мэтт Генцкоу и Джесси Шапиро, бывшие тогда аспирантами в Гарварде, прочитали о недавнем решении суда в Массачусетсе легализовать однополые браки.
Парни обратили внимание на нечто интересное: две газеты использовали разительно отличающиеся выражения, описывая одно и то же событие. «Вашингтон Таймс», имеющая репутацию консервативной, озаглавила статью «Гомосексуальная “свадьба” в Массачусетсе». А «Вашингтон пост», считающаяся либеральной, сообщила о «победе однополых пар».
Неудивительно, что различные новостные источники могут склоняться к разным мнениям, что газеты могут пересказать одну и ту же историю в разном ключе. В течение многих лет Генцкоу и Шапиро размышляли, могут ли они использовать свое экономическое образование для того, чтобы понять причины этой предвзятости СМИ. Почему некоторые из них кажутся более либеральными, а другие – более консервативными?
Но у парней не было никаких идей о том, как им решать эту задачу – они не могли понять, каким образом систематически и объективно измерять субъективность СМИ.
Интересным для Генцкоу и Шапиро в истории о гей-браках было не то, что газеты разошлись во взглядах – их заинтересовало, как именно разнилось освещение событий. Речь идет о заметном смещении акцентов при выборе слов. В 2004 году слово «гомосексуалисты», которое использовала «Вашингтон Таймс», было старомодным и унизительным способом описания геев. А вот термин «однополые пары», который употребила «Вашингтон пост», подчеркивает, что отношения геев – просто еще одна форма любви.
Ученые задались вопросом: не может ли язык быть ключом к пониманию необъективности. Возможно, либералы и консерваторы последовательно использовали разные выражения? И можно ли слова, употребляемые газетами при описании той или иной истории, превратить в данные? И что эти сведения могут рассказать об американской прессе? Могли бы мы определить по словам, является пресса либеральной или консервативной? И могли бы мы понять, почему? В 2004 году это были не праздные вопросы. Миллиарды слов в американских изданиях больше не попадали на газетную бумагу или микропленку. Некоторые сайты сейчас записывают каждое слово из каждой статьи почти каждой газеты в США. Генцкоу и Шапиро могли бы прошерстить эти сайты и быстро протестировать, в какой степени язык может показать перекос газеты в ту или иную сторону. Эти тесты помогли бы им улучшить наше понимание принципов работы СМИ.
Но прежде чем описывать их находки, давайте оставим на минутку историю Генцкоу и Шапиро, а также их попытки количественно описать газетный язык, и обсудим, как ученые уже использовали этот новый тип данных – слова – для более глубокого понимания человеческой природы.
Конечно, язык всегда был предметом интереса социологов. Однако для его изучения, как правило, требуется внимательное чтение текстов. И превращение огромных кусков текста в данные раньше не представлялось возможным. Сейчас же, используя компьютеры и оцифровку, легко осуществить классификацию слов, взятых из огромного массива документов. Таким образом, язык стал предметом анализа больших данных. Ссылки, с которыми работает Google, также состоят из слов – равно как и поисковые запросы в Google, с которыми работаю я. Язык настолько важен в информационной революции, что заслуживает отдельного, посвященного только ему раздела книги. На самом деле сейчас он используется настолько широко, что появилось даже понятие «текст как данные».
Основной разработкой в этой области является Google Ngrams. Несколько лет назад два молодых биолога, Эрез Эйден и Жан-Батист Мишель, предложили своим помощникам одно за другим подсчитывать слова в старых пыльных текстах – чтобы выяснить, как часто в них встречается та или иная лексика. Однажды Эйден и Мишель услышали о новом проекте компании Google по оцифровке книг со всего мира и почти сразу же сообразили: так в истории языка будет разобраться гораздо проще.
«Мы поняли, что наши методы безнадежно устарели, – рассказывал Эйден в интервью журналу « Discover» . – Было понятно: конкурировать с этой всепобеждающей цифровой мощью невозможно». Поэтому они решили с ней сотрудничать. При помощи инженеров Google Эйден и Мишель создали сервис, осуществляющий поиск по определенному слову или фразе по миллионам оцифрованных книг. Потом приложение сообщает исследователям, как часто это слово или фраза появлялись ежегодно в период с 1800 по 2010 годы.
Так что же мы можем узнать по частоте, с которой слова или фразы появляются в книгах в разные годы? Прежде всего, о медленном росте популярности колбасы и относительно недавнем быстром росте популярности пиццы.
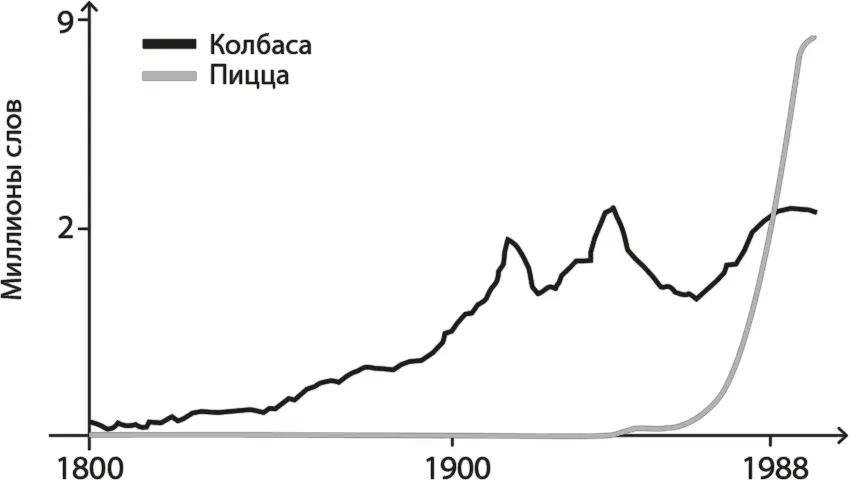
Но есть и гораздо более серьезные результаты. Например, Ngrams Google может показать, как формировалась наша национальная самобытность. Вот, скажем, увлекательный пример из книги Эйдена и Мишеля «Uncharted» («Неизведанное»).
Но сначала один вопрос. Как вы думаете, сегодня Соединенные Штаты – единая или разобщенная страна? Если вы принадлежите к большинству обычных людей, то скажете, что США сильно разобщены из-за высокого уровня политической поляризации. Можно даже сказать, что сегодня страна разобщена как никогда. Америка, в конце концов, теперь разделена по цвету: красные штаты – республиканские, синие – демократические. Но в книге «Uncharted» Эйдена и Мишеля есть один впечатляющий момент, демонстрирующий, насколько сильнее Соединенные Штаты были разобщены в прошлом. Об этом свидетельствуют слова, которые люди используют, говоря о своей стране.
Обратите внимание на слова, которые я использовал в предыдущем абзаце, говоря о разобщенности страны. Я писал: «США – разобщенная страна». Я говорил о США как о существительном в единственном числе. Это естественно, это правильная грамматика и стандартный вариант употребления слов. Уверен, вы этого даже не заметили.
Однако американцы далеко не всегда говорят подобным образом. На заре формирования Соединенных Штатов люди, упоминая свою страну, использовали множественное число. Например, Джон Адамс в докладе о положении дел в 1799 году говорил о «Соединенных Штатах и ИХ договорах с его британским Величеством». Если бы моя книга была написана в 1800 году, я бы сказал: «Соединенные Штаты разобщены». Эта небольшая разница в использовании слов давно заинтересовала историков, поскольку предполагает существование момента, когда Америка перестала думать о себе как о совокупности штатов и начала думать о себе как о единой нации.
Читать дальшеИнтервал:
Закладка:



![Алексей Благирев - Big data простым языком [litres]](/books/1084716/aleksej-blagirev-big-data-prostym-yazykom-litres.webp)




