Леонард Млодинов - (Не)совершенная случайность. Как случай управляет нашей жизнью

- Название:(Не)совершенная случайность. Как случай управляет нашей жизнью
- Автор:
- Жанр:
- Издательство:Livebook/Гаятри
- Год:2010
- Город:Москва
- ISBN:978-5-9689-0171-2
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Леонард Млодинов - (Не)совершенная случайность. Как случай управляет нашей жизнью краткое содержание
В книге «(Не)совершенная случайность. Как случай управляет нашей жизнью» Млодинов запросто знакомит всех желающих с теорией вероятностей, теорией случайных блужданий, научной и прикладной статистикой, историей развития этих всепроникающих теорий, а также с тем, какое значение случай, закономерность и неизбежная путаница между ними имеют в нашей повседневной жизни.
Эта книга — отличный способ тряхнуть стариной и освежить в памяти кое-что из курса высшей математики, истории естественнонаучного знания, астрономии и статистики для тех, кто изучал эти дивные дисциплины в вузах; понятно и доступно изложенные основы теории вероятностей и ее применимости в житейских обстоятельствах (с многочисленными примерами) для тех, кому не посчастливилось изучать их специально; наконец, профессиональный и дружелюбный подсказчик грызущим гранит соответствующих наук в данный момент.
(Не)совершенная случайность. Как случай управляет нашей жизнью - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Идея о том, что распределение ошибок подчиняется некому универсальному закону, который называют законом случайного распределения ошибок, является основополагающей для теории измерения. И вот что примечательно: допущение состоит в том, что при условии удовлетворения определенных условий довольно общего характера установить истинное значение некоторой переменной на основе ряда измерений можно с использованием одного и того же математического аппарата. Если в дело вступает универсальный закон, то задача установления истинного положения небесного тела на основе ряда наблюдений астрономов приравнивается к задаче нахождения центра мишени на основе дырочек от стрел или определения «качества» вина на основе ряда экспертных оценок. Именно поэтому математическая статистика — последовательная и согласованная область, а не просто набор трюков: неважно, осуществляете ли вы ряд измерений для того, чтобы установить положение Юпитера в 4 часа утра на Рождество или средний вес булок с изюмом, выходящих с конвейера, распределение ошибок будет одним и тем же.
Однако отсюда не следует, что случайная ошибка — единственный вид ошибок, которые могут повлиять на измерение. Если половина дегустаторов предпочитает красное вино, а другая половина — белое, однако во всех остальных отношениях они сходятся в своих суждениях (и предельно последовательны в их вынесении), то оценка каждого конкретного вина не будет определяться законом случайного распределения ошибок: распределение получится резко двугорбым, причем причиной появления одного из пиков станут любители красного вина, а другого — любители белого. Но даже в тех случаях, когда применимость закона случайного распределения ошибок не столь очевидна (начиная от футбольного тотализатора {143} 143 Hal Stern, «On the Probability of Winning a Football Game», American Statistician 45, no. 3 (August 1991): 179-82.
и заканчивая измерением коэффициента интеллекта), зачастую он все же оказывается применим. Много лет назад мне в руки попали несколько тысяч регистрационных карточек покупателей компьютерной программы, которую разработал для восьми- и девятилетних школьников мой приятель. Продажи шли не так хорошо, как ожидалось. Кто же покупал программу? После некоторых подсчетов я установил, что наибольшее число пользователей приходится на семилетних, указывая на нежелательное, но не то чтобы неожиданное расхождение. Но вот что самое удивительное: когда я построил гистограмму зависимости количества пользователей от возраста, взяв семь лет за среднее значение, я обнаружил, что построенный мною график принял крайне знакомую форму — форму закона случайного распределения ошибок.
Одно дело — подозревать, что лучники и астрономы, химики и маркетологи сталкиваются с одним и тем же законом распределения ошибок, и совсем другое — самому натолкнуться на частный случай этого закона. Подталкиваемые необходимостью анализировать данные астрономических наблюдений ученые, такие как Даниил Бернулли и Лаплас, постулировали в конце XVIII в. несколько вариантов закона, оказавшихся неверными. Однако выяснилось, что математическая функция, верно отражающая закон случайного распределения ошибок, — колоколообразная кривая — все это время была у них под носом. За много десятилетий до них она была открыта в Лондоне в контексте решения совсем иных задач.
Среди троих ученых, благодаря которым на колоколообразную кривую обратили внимание, реже всех воздается по заслугам именно ее первооткрывателю. Абрахам де Муавр совершил свое открытие в 1733 г., когда ему было за шестьдесят, однако до появления второго издания его книги «Об измерении случайности», вышедшего в свет пять лет спустя, об этом никто не знал. Де Муавр пришел к искомой форме кривой, когда пытался аппроксимировать числа, заполняющие треугольник Паскаля значительно дальше той строки, на которой оборвал его я, — сотнями и даже тысячами строк ниже. Когда Якоб Бернулли обосновывал свой вариант закона больших чисел, ему пришлось столкнуться с некоторыми свойствами чисел, появляющихся в этих строках. А числа действительно очень велики: например, одно из чисел в двухсотой строке треугольника Паскаля состоит из пятидесяти девяти цифр! Во времена Бернулли, да и вообще до тех пор, пока не появились компьютеры, эти числа было очень трудно высчитать. Именно поэтому, как я сказал, Бернулли обосновывал свой закон больших чисел, используя различные способы приближенного вычисления, что снижало практическую значимость результатов его работы. Де Муавр со своей кривой осуществил несравненно более точную аппроксимацию и потому значительно улучшил оценки Бернулли.
Как де Муавр осуществил свою аппроксимацию, становится понятно, если числа в ряду треугольника представить в виде высоты столбика на гистограмме — я поступил так с регистрационными карточками. Например, числа в третьей строке треугольника — 1, 2, 1. Тогда на гистограмме первый столбик будет высотой в одно деление, второй — вдвое выше, а третий — вновь высотой в одно деление. Рассмотрим теперь пять чисел в пятой строке: 1, 4, 6, 4, 1. На гистограмме будет пять столбиков, она вновь начнется с минимальной высоты, достигнет максимума в центре и продемонстрирует симметричное снижение. Если спуститься по треугольнику вниз, получатся гистограммы с огромным количеством столбиков, но поведение их будет тем же самым. Гистограммы для 10-й, 100-й и 1000-й строк треугольника Паскаля приведены ниже.
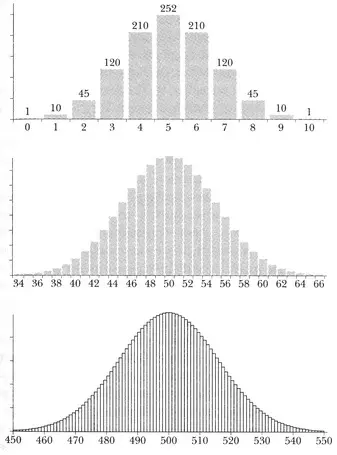
Столбцы в представленных выше гистограммах отображают относительную величину числа в 10-м, 100-м и 1000-м рядах треугольника Паскаля (см. выше). Числа по оси абсцисс — элементы строки треугольника, к которым относятся столбики. По традиции нумерация начинается с 0, а не с 1 (средняя и нижняя гистограммы обрезаны так, что элементы, столбики для которых имеют пренебрежимую высоту, на рисунке не представлены).
Если теперь провести кривые, соединяющие вершины столбиков на каждой из гистограмм, все они окажутся характерной формы, напоминающей колокол. А если несколько сгладить эти кривые, можно подобрать соответствующее им математическое выражение. Колоколообразная кривая — не просто визуализация чисел в треугольнике Паскаля: это инструмент, позволяющий получить точные и удобные в употреблении оценки значений чисел, появляющихся в расположенных ниже строках треугольника. В этом и состояло открытие де Муавра.
Сегодня колоколообразную кривую называют обычно нормальным распределением, а иногда — Гауссовой кривой (вскоре читатель узнает, откуда взялось это название). Нормальное распределение — не отдельная фиксированная кривая, но целое семейство кривых, определяемых двумя параметрами, задающими положение кривой и ее форму. Первый из них — расположение пика: в графиках выше это 5, 50 и 500 соответственно. Второй — степень разброса. Этот показатель, получивший свое современное наименование лишь в 1894 г., называется стандартным отклонением и представляет собой теоретический аналог понятия, о котором я уже упоминал — выборочного стандартного отклонения. Грубо говоря, это половина ширины кривой в той точке, где кривая достигает своей 60%-ной высоты. В наше время значение нормального распределения выходит далеко за пределы аппроксимации чисел в треугольнике Паскаля. Это самая распространенная форма распределения любого рода данных.
Читать дальшеИнтервал:
Закладка:









