Рамиля Латыпова - Базы данных. Курс лекций. Учебное пособие

- Название:Базы данных. Курс лекций. Учебное пособие
- Автор:
- Жанр:
- Издательство:Литагент Проспект (без drm)
- Год:2015
- ISBN:9785392191512
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Рамиля Латыпова - Базы данных. Курс лекций. Учебное пособие краткое содержание
Базы данных. Курс лекций. Учебное пособие - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Неформализуемая задача – та, в которой невозможно выделить элементы и установить между ними связи. При решении неформализуемых задач возникают трудности из-за невозможности создания точного математического описания. Здесь большое значение могут иметь эвристические соображения человека на основе опыта и косвенной информации из разных источников.
На практике о большинстве задач можно сказать, что известна лишь часть их элементов и связей между ними. Такие задачи называются частично формализуемыми . В этих условиях можно создать информационную систему. Получаемая в ней информация анализируется человеком, который будет играть определяющую роль. Такие информационные системы являются автоматизированными, так как в их функционировании принимает участие человек [5].
Для решения неформализуемых и частично формализуемых задач разрабатываются экспертные системы, или системы обработки знаний [14].
Лекция 2
История развития баз данных
В настоящее время базы данных (БД) – наиболее массовая область информационных технологий.
Всякая программа для ЭВМ является моделью некоторой предметной области. База данных – это также модель взаимосвязей между объектами реального мира и описание этих объектов.
В настоящее время наиболее распространены реляционные БД, исторически им предшествовали иерархические и сетевые БД.
Первые БД, появившиеся в 1960-е гг., были предназначены для планирования выпуска продукции. Очень часто возникала потребность определить, сколько требуется комплектующих для выпуска того или иного вида продукции. Таким задачам соответствует древовидная (иерархическая) структура.
Например, при выпуске автомобиля получается структура, показанная на рис. 3.
Каждому прямоугольнику на рис. 3 соответствует запись в БД.
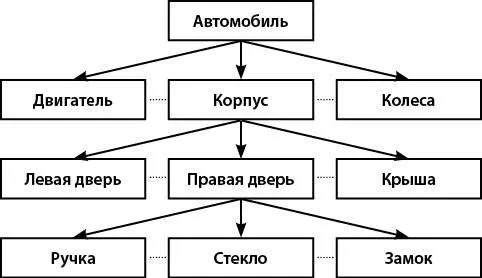
Рис. 3.Пример иерархической структуры
Между записями существуют отношения «предок – потомок». Для получения доступа к данным в иерархической БД можно указать номер записи, а также выполнить ряд действий:
1. Найти дерево по признаку;
2. Перейти «вниз» к первому потомку;
3. Перейти «в сторону» к следующему потомку;
4. Перейти «вверх» к предку;
5. Вставлять и удалять записи.
Таким образом, по записям можно перемещаться, переходя вниз, вверх или в сторону.
Иерархические БД имеют следующие достоинства:
1. Структура БД проста для понимания;
2. Отношения «предок – потомок» позволяют моделировать высказывания типа « А – часть В » или « А владеет В »;
3. Записи можно оптимально размещать на носителе информации, т. е. предки возле потомков, тем самым сокращается время доступа.
Самая известная из таких БД – это IMS (англ.: Information management system – система управления информацией) фирмы IBM (1968 г.). Эта система управления базами данных (СУБД) все еще активно эксплуатируется на больших ЭВМ.
Сетевые БД (здесь не имеются в виду сети ЭВМ) позволяют описать те случаи, когда одна запись может участвовать в нескольких отношениях «предок – потомок», т. е. иметь несколько предков (рис. 4). Такие отношения в сетевой модели называют множествами.
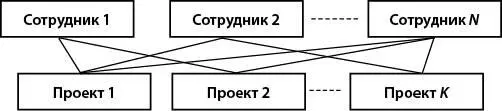
Рис. 4.Пример сетевой организации данных
Официальный стандарт сетевых БД был предложен в 1971 г., он получил название CODASYL (англ. COnference on DAta SYstems Language – Конференция по языкам систем обработки данных).
Доступ к данным в сетевой модели напоминает доступ к данным в иерархической модели. Программа может выполнять следующие действия:
1. Найти запись по ее номеру (признаку);
2. Перейти к первому потомку в конкретном множестве;
3. Перейти «в сторону» от потомка к потомку в конкретном множестве;
4. Перейти «вверх» от потомка к предку в другом множестве;
5. Вставлять и удалять записи.
Сетевые БД отличаются большей гибкостью, так как позволяют описать более сложные структуры данных.
Но иерархические и сетевые БД имеют общий недостаток: структура данных описывается жестко на этапе проектирования. При перестройке структуры нужно перестраивать всю БД.
Кроме того, иерархические и сетевые БД требовали участия специалиста – программиста для реализации запросов. Это вызывало задержки при эксплуатации БД.
Поэтому такие БД сейчас имеют меньшее распространение, чем реляционные БД. В переводе с англ. relation означает «отношение». Математический аппарат, который используется в таких БД, позволяет описывать таблицы и операции над ними.
Теоретический фундамент реляционных БД заложил Э. Кодд, разработавший в 70-е гг. математический аппарат теории отношений. Реляционная модель является теорией, но фактически ни одна из современных БД не придерживается на все 100 % положений этой теории. То есть пользователь должен учитывать теоретические рекомендации, но имеет возможности для их нарушения.
При математическом описании понятию таблицы соответствует понятие отношение , столбцу – атрибут, и строке – кортеж .
При практической разработке строки называют записями , а столбцы – полями . То есть запись – это набор полей, содержащих связанную информацию. Поле – это элемент данных в БД. Поле должно иметь имя и тип.
База данных – набор связанных таблиц, обычно идентифицируемых с помощью каталога, содержащего эти таблицы, или с помощью псевдонима, дающего имя БД.
По отношению к пользователю реляционные БД поддерживают два основных принципа:
1. Данные для пользователя представляются в виде таблиц;
2. Пользователь имеет в своем распоряжении операторы, позволяющие получить новые таблицы из старых.
При построении реляционных БД используется несколько простых правил:
1. Все значения данных состоят из простых типов данных. Отсутствуют сложные типы, такие как массивы, указатели, векторы и т. д.;
2. Все данные отображаются в виде двумерных таблиц (отношений). Каждая таблица содержит некоторое число строк (кортежей) и один или несколько столбцов (атрибутов);
3. После ввода данных можно сравнивать значения в различных столбцах и соотносить строки (в том числе и для разных таблиц);
4. Все операции определяются только логикой, а не положением строки в таблице;
5. Поскольку определить строку по ее положению в таблице нельзя, бывает необходимо иметь специальное поле в каждой строке – первичный ключ ;
6. Каждое значение в столбце должно быть атомарной величиной, т. е. содержать только одно значение.
Читать дальшеИнтервал:
Закладка: