Эндрю Уэзеролл - Компьютерные сети. 5-е издание

- Название:Компьютерные сети. 5-е издание
- Автор:
- Жанр:
- Издательство:Питер
- Год:2011
- ISBN:9785446100682
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Эндрю Уэзеролл - Компьютерные сети. 5-е издание краткое содержание
Компьютерные сети. 5-е издание - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
1. HTML и CSS, чтобы представлять информацию в виде страниц.
2. DOM (Document Object Model — объектная модель документов), чтобы менять части страниц при просмотре.
3. XML (extensible Markup Language — расширяемый язык разметки), чтобы программам обмениваться данными приложений с сервером.
4. Асинхронный способ, при помощи которого программы отсылают и получают XML-данные.
5. JavaScript — язык, который связывает все эти технологии.
Так как все это представляет из себя некоторый набор, мы рассмотрим каждую из частей, чтобы оценить ее вклад в создание веб-приложений. Мы уже рассмотрели HTML и CSS. Они являются стандартами описания контента и того, как он должен отображаться. Любая программа, которая может создавать HTML и CSS, может использовать веб-браузер, как средство отображения.
DOM — это представление HTML-страницы, доступное программам. Это представление имеет структуру дерева, отражающего структуру HTML-элементов. Например, DOM-дерево HTML-текста, приведенного в листинге 7.8, а, дано на рис. 7.14. В корне находится элемент html, который представляет весь блок HTML. Этот элемент является родительским по отношению к элементу body, который, в свою очередь, является родительским для элемента form. У элемента form есть два атрибута, которые вы можете увидеть справа, один из них относится к методу формы (POST ) и один предназначен для действия, которое нужно провести с формой (URL-запрос). У этого элемента есть три дочерних, включающих два тега абзацев и один тег для ввода информации, которая содержится в форме. В нижней части расположены листья, являющиеся либо элементами, либо константами, такими как текстовые строки. Значение модели DOM состоит в том, что она предоставляет программам простой способ менять части страницы. Таким образом, не возникает необходимости полностью переписывать страницу. Заменяется только тот узел, в который вносятся изменения. Когда они внесены, браузер обновит соответствующую часть страницы. Например, если в DOM была изменена часть страницы, содержащая изображение, браузер обновит это изображение, оставив остальные части страницы неизменными. Мы уже видели, как работает DOM, когда пример JavaScript из листинга 7.9 добавлял строки к элементу document, чтобы вызвать появление новых строк в нижней части окна браузера. DOM — это отличный способ создания страниц, которые могут меняться.
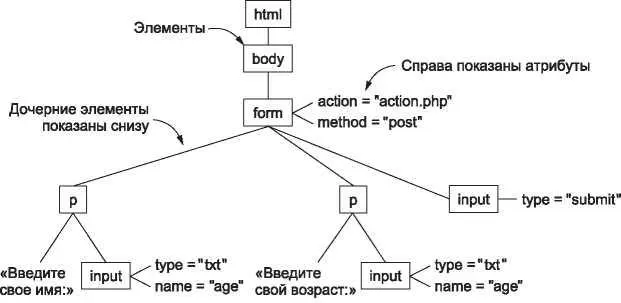
Рис. 7.14. Дерево DOM для HTML из листинга 7.8, a
Третья технология, XML, — это язык, предназначенный для описания структурированного контента. HTML мешает контент с форматированием, так как он связан со способом представления информации. Однако по мере того, как веб-приложения становятся более распространенными, нарастает потребность разделить структурированный контент и его представление. Например, рассмотрим программу, которая ищет
в сети лучшую цену на какую-либо книгу. Когда веб-страницы написаны на HTML, программе очень трудно выяснить, где указаны название и цена.
По этой причине консорциум WWW (W3C) разработал XML (Bray и др. 2006), чтобы веб-контент можно было структурировать для автоматической обработки. В отличие от HTML для XML не существует четко определенных тегов. Каждый пользователь может создавать свои. Простой пример XML-документа приведен в листинге 7.10. Он определяет структуру под названием book_list, являющуюся списком книг. У каждой книги есть 3 поля: название, автор и год издания. Эти структуры очень просты. В структурах могут повторяться поля (например, в случае коллектива авторов), могут быть дополнительные поля (например, URL аудиокниги) и альтернативные поля (например, URL книжного магазина, если книга есть в наличии, или URL сайта аукциона, если она распродана).
Листинг 7.10.Простой документ XML

В этом примере каждое из трех полей является неделимой сущностью, но теоретически поля можно делить и дальше. Например, чтобы хорошо контролировать поиск и форматирование, поле «автор» может быть оформлено следующим образом:
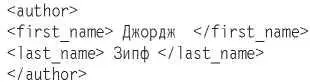
Каждое поле может быть подразделено на подполя (а подполя на подподполя и т. д.) произвольное количество раз.
Файл, проиллюстрированный листингом 7.10, просто определяет список из трех книг. Он хорошо подходит для передачи информации между программами, работающими в браузерах и на серверах, но ничего не говорит о том, каким образом документ должен быть представлен в виде веб-страницы. Чтобы сделать это, программа, которая собирает информацию и решает, что 1949 год был весьма урожаен на книги,
может выдать HTML, в котором названия выделены курсивом. Кроме того, язык под названием XSLT( extensible Stylesheet Language Transformations — стилевые трансформации расширяемого языка разметки) может использоваться для того, чтобы определить, каким образом трансформировать XML в HTML. XSLT похож на CSS, но у него гораздо больше возможностей. Мы, пожалуй, избавим вас от деталей.
Еще одно преимущество представления данных в виде XML, а не HTML состоит в том, что программам проще их анализировать. На HTML изначально писали вручную (да и сейчас не многое изменилось), так что часто он выглядит несколько сырым. Иногда закрывающие теги, такие как , опускаются. У других, таких как
, нет соответствующих закрывающих тегов. Кроме того, другие теги могут размещаться не там, где следует, а положение имен тегов и атрибутов может варьироваться. Большинству браузеров приходится нелегко, когда они пытаются разобраться в таком коде. У XML гораздо более строгая структура. Имена тегов и атрибутов всегда пишутся в нижнем регистре, теги всегда должны закрываться в порядке, обратном порядку их появления (или же должно быть строго определено, что определенному тегу не нужен соответствующий закрывающий тег), а значения атрибутов должны быть заключены в кавычки. Эта точность определений делает разбор проще, а результат получается однозначный.
HTML даже был определен в терминах XML. Этот подход называется XHTML( eXtended HyperText Markup Language— расширенный язык гипертекстовой разметки). В общем-то это просто версия HTML с очень жесткими требованиями. Страницы XHTML должны строго соответствовать правилам XML, иначе они не принимаются браузером. Так что с низкокачественными веб-страницами и несовместимости страниц с браузерами покончено. Так же как в случае с XML, целью было создание страниц, которые бы легче обрабатывались программами (в данном случае веб-приложениями). Хотя XHTML существовал с 1998 года, он долго не мог завоевать популярность. Те, кто пользовался HTML, не понимали, зачем им нужен XHTML, и он долго не поддерживался браузерами. Сегодня HTML 5.0 определен таким образом, что страница может быть написана либо на HTML, либо на XHTML, чтобы переход на новый стандарт не был таким резким. В итоге XHTML должен заменить HTML, но пройдет еще много времени, прежде чем этот переход будет завершен.
Читать дальшеИнтервал:
Закладка:


