Педро Домингос - Верховный алгоритм

- Название:Верховный алгоритм
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2015
- ISBN:9785001001720
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Педро Домингос - Верховный алгоритм краткое содержание
Верховный алгоритм - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Наивный байесовский алгоритм — хорошая концептуальная модель обучающегося алгоритма для чтения прессы: улавливает попарные корреляции между каждым из входов и выходов. Но машинное обучение, конечно, не просто парные корреляции, не в большей степени, чем мозг — это нейрон. Настоящее действие начинается, если посмотреть на более сложные паттерны.
От «Евгения Онегина» до Siri
В преддверии Первой мировой войны русский математик Андрей Марков опубликовал статью, где вероятности применялись, помимо всего прочего, к поэзии. В своей работе он моделировал классику русской литературы — пушкинского «Евгения Онегина» — с помощью подхода, который мы сейчас называем цепью Маркова. Вместо того чтобы предположить, что каждая буква сгенерирована случайно, независимо от остальных, Марков ввел абсолютный минимум последовательной структуры: допустил, что вероятность появления той или иной буквы зависит от буквы, непосредственно ей предшествующей. Он показал, что, например, гласные и согласные обычно чередуются, поэтому, если вы видите согласную, следующая буква (если игнорировать знаки пунктуации и пробелы) с намного большей вероятностью будет гласной, чем если бы буквы друг от друга не зависели. Может показаться, что это невеликое достижение, но до появления компьютеров требовалось много часов вручную подсчитывать символы, и идея была довольно новой. Если гласная i — это булева переменная, которая верна, если i -я по счету буква «Евгения Онегина» — гласная, и неверна, если она согласная, можно представить модель Маркова как похожий на цепочку график со стрелками между узлами, указывающими на прямую зависимость между соответствующими переменными:

Марков сделал предположение (неверное, но полезное), что в каждом месте текста вероятности одинаковы. Таким образом нам нужно оценить только три вероятности: P(гласная 1 = верно) ; P(гласная i+1 = верно | гласная i = верно) и P(гласная i+1 = верно | гласная i = верно) . (Поскольку сумма вероятностей равна единице, из этого можно сразу получить P(гласная 1 = ложно) и так далее.) Как и в случае наивного байесовского алгоритма, переменных можно взять сколько угодно, не опасаясь, что число вероятностей, которые надо оценить, пробьет потолок, однако теперь переменные зависят друг от друга.
Если измерять не только вероятность гласных в зависимости от согласных, но и вероятность следования друг за другом для всех букв алфавита, можно поиграть в генерирование новых текстов, имеющих ту же статистику, что и «Евгений Онегин»: выбирайте первую букву, потом вторую, исходя из первой, и так далее. Получится, конечно, полная чепуха, но, если мы поставим буквы в зависимость от нескольких предыдущих букв, а не от одной, текст начнет напоминать скорее бессвязную речь пьяного — местами разборчиво, хотя в целом бессмыслица. Все еще недостаточно, чтобы пройти тест Тьюринга, но модели вроде этой — ключевой компонент систем машинного перевода, например Google Translate, которые позволяют увидеть весь интернет на английском (или почти английском), независимо от того, на каком языке написана исходная страница.
PageRank — алгоритм, благодаря которому появился Google, — тоже представляет собой марковскую цепь. Идея Ларри Пейджа заключалась в том, что веб-страницы, к которым ведут много ссылок, вероятно, важнее, чем страницы, где их мало, а ссылки с важных страниц должны сами по себе считаться больше. Из-за этого возникает бесконечная регрессия, но и с ней можно справиться с помощью цепи Маркова. Представьте, что человек посещает один сайт за другим, случайно проходя по ссылкам. Состояния в этой цепи Маркова — это не символы, а веб-страницы, что увеличивает масштаб проблемы, однако математика все та же. Суммой баллов страницы тогда будет доля времени, которую человек на ней проводит, либо вероятность, что он окажется на этой странице после долгого блуждания вокруг нее.
Цепи Маркова появляются повсюду, это одна из самых активно изучаемых тем в математике, но это все еще сильно ограниченная разновидность вероятностных моделей. Сделать шаг вперед можно с помощью такой модели:
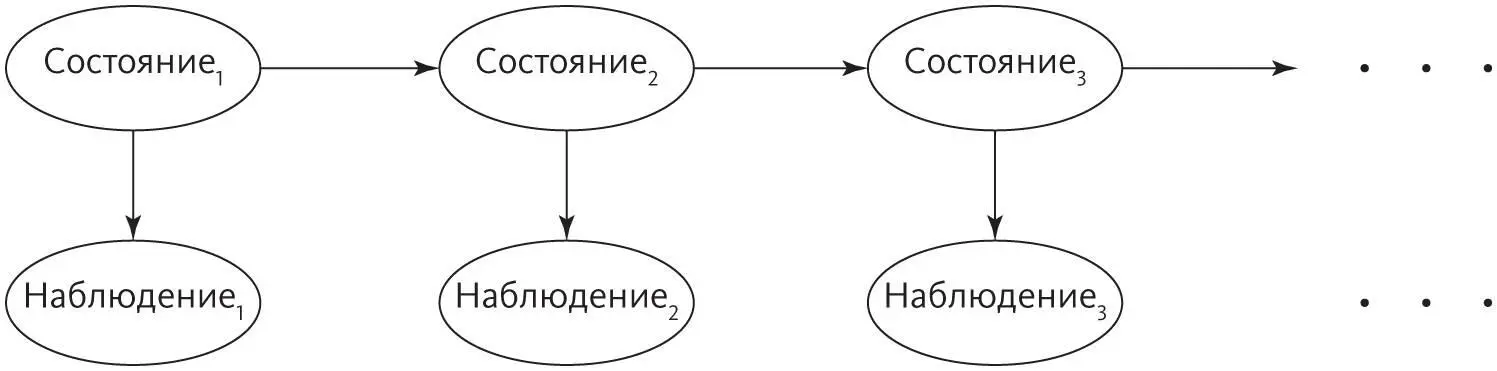
Состояния, как и ранее, образуют марковскую цепь, но мы их не видим, и надо вывести их из наблюдений. Это называется скрытой марковской моделью, сокращенно СММ (название немного неоднозначное, потому что скрыта не модель, а состояния). СММ — сердце систем распознавания речи, например Siri. В задачах такого рода скрытые состояния — это написанные слова, наблюдения — это звуки, которые слышит Siri, а цель — определить слова на основе звуков. В модели есть два элемента: вероятность следующего слова при известном текущем, как в цепи Маркова, и вероятность услышать различные звуки, когда произносят слово. (Как именно сделать такой вывод — интересная проблема, к которой мы обратимся после следующего раздела.)
Кроме Siri, вы используете СММ каждый раз, когда разговариваете по мобильному телефону. Дело в том, что ваши слова передаются по воздуху в виде потока битов, а биты при передаче искажаются. СММ определяет, какими они должны быть (скрытые состояния), на основе полученных данных (наблюдений), и, если испортилось не слишком много битов, у нее обычно все получается.
Скрытая марковская модель — любимый инструмент специалистов по вычислительной биологии. Белок представляет собой последовательность аминокислот, а ДНК — последовательность азотистых оснований. Если мы хотим предсказать, например, в какую трехмерную форму сложится белок, можно считать аминокислоты наблюдениями, а тип складывания в каждой точке — скрытым состоянием. Аналогично можно использовать СММ для определения мест в ДНК, где инициируется транскрипция генов, а также многих других свойств.
Если состояния и наблюдения — не дискретные, а непрерывные переменные, СММ превращается в так называемый фильтр Калмана88. Экономисты используют эти фильтры, чтобы убрать шум из временных рядов таких величин, как внутренний валовой продукт (ВВП), инфляция и безработица. «Истинные» значения ВВП — это скрытые состояния. На каждом временном отрезке истинное значение должно быть схоже и с наблюдаемым, и с предыдущим истинным значением, поскольку в экономике резкие скачки встречаются нечасто. Фильтр Калмана находит компромисс между этими условиями и позволяет получить более гладкую, но соответствующую наблюдениям кривую. Кроме того, фильтры Калмана не дают ракетам сбиться с курса, и без них человек не побывал бы на Луне.
Читать дальшеИнтервал:
Закладка:






