Джин Ким - Руководство по DevOps

- Название:Руководство по DevOps
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2018
- Город:Москва
- ISBN:9785001007500
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джин Ким - Руководство по DevOps краткое содержание
Руководство по DevOps - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Хотя вначале может оказаться трудным убедить разработчиков, рано или поздно они увидят исключительные преимущества такого подхода и, скорее всего, станут сторонниками постоянных преобразований, как это показывают примеры HP LaserJet и Bazaarvoice. Методы непрерывной интеграции создают основание для следующего шага — автоматизации процесса развертывания и низкого риска при релизе ПО.
Глава 12. Автоматизация и запуск релизов с низким уровнем риска
Чак Росси — технический директор в Facebook. Одна из его задач — контроль за ежедневным релизом кода. В 2012 г. Росси так описал процесс: «Начиная с часа дня я переключаюсь в “режим эксплуатации” и вместе с командой готовлюсь запустить обновления, которые выйдут на Facebook.comв этот день. Эта наиболее напряженная часть работы в значительной степени зависит от решений моей команды и от прошлого опыта. Мы стремимся убедиться, что каждый, кто вносил релизные изменения, отчитывается за них, а также активно тестирует и поддерживает изменения».
Незадолго до релиза все разработчики релизных изменений должны появиться на своем канале интернет-чата — отсутствующим разработчикам приходит возврат обновлений, автоматически удаленных из пакета развертывания. Росси продолжает: «Если все хорошо и наши инструменты тестирования и “канареечные тесты” успешны [89], мы нажимаем большую красную кнопку, и весь “парк” серверов Facebook.comполучает новый код. В течение 20 минут тысячи и тысячи компьютеров переходят на новый код без какого-либо заметного влияния на тех, кто использует сайт» [90].
Позже в том же году Росси увеличил частоту релизов программного обеспечения до двух раз в день. Он объяснил, что второй релиз кода позволил инженерам, находящимся не на Западном побережье США, «вносить изменения и отправлять их так же быстро, как любой другой инженер в компании», а также предоставил всем еще одну возможность каждый день отправлять код и запускать новые функциональные возможности.
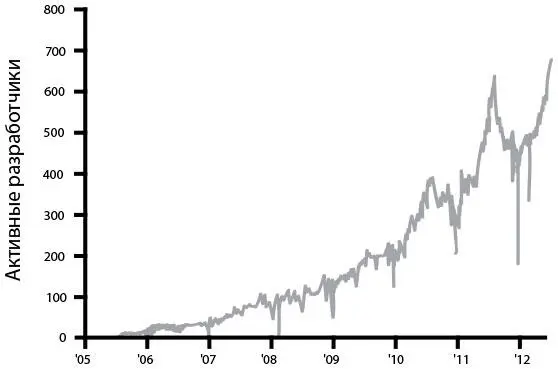
Рис. 16. Количество разработчиков Facebook в неделю, развертывающих свой код (источник: Chuck Rossi, Ship early and ship twice as often)
Кент Бек, создатель методологии экстремального программирования, один из основных сторонников разработки на основе тестирования и технический наставник в компании Facebook, прокомментировал стратегию релиза кода компании в статье, опубликованной на его странице в Facebook: «Чак Росси отметил: создается впечатление, что за одно развертывание Facebook может обработать только ограниченное количество изменений. Если мы хотим сделать больше изменений, то нам нужно выполнить больше развертываний. Это привело к неуклонному росту темпов развертывания в течение последних пяти лет, с одного раза в неделю до ежедневного, а затем — до трех раз в день для кода PHP и с шестинедельного до четырехнедельного, а затем двухнедельного цикла развертывания мобильных приложений. Улучшение было обеспечено главным образом инженерной группой, ответственной за релизы».
Используя непрерывную интеграцию и развертывание кода с помощью процесса с низким уровнем риска, компания Facebook сделала развертывание кода частью повседневной работы разработчиков, чем способствовала их производительности. Для этого необходимо, чтобы развертывание кода было автоматизированным, повторяемым и предсказуемым. Хотя в методиках, описанных выше, наши код и среды тестировались вместе, скорее всего, развертывание в производство выполнялось не очень часто, поскольку делалось вручную, занимало много времени, было трудным и утомительным, оказывалось подвержено ошибкам и часто вытекало из неудобной и ненадежной передачи работы от отдела разработки к отделу эксплуатации.
И поскольку все это непросто, мы склонны делать так все реже, что приводит к другой самоусиливающейся нисходящей спирали. Откладывая развертывание изменений в производство, мы накапливаем все больше различий между кодом, который будет развернут, и кодом, в данный момент работающим в производстве, увеличивающим размер пакетной работы. Так растет риск неожиданных результатов, вызванных изменением, а также трудности, связанные с их исправлением.
В этой главе мы снизим внутренние трения, связанные с развертыванием в производство, чтобы оно могло выполняться часто и легко, как разработчиками, так и отделом эксплуатации. Мы можем сделать это за счет расширения конвейера развертывания.
Вместо простой непрерывной интеграции кода в среде, близкой к производственной, обеспечим продвижение в производство любой сборки, проходящей автоматизированные тесты и процессы валидации или по запросу (например, нажатием на кнопку), или автоматически (например, любая сборка, которая проходит все тесты, развертывается автоматически).
Поскольку в данной главе описано значительное количество методик, то, чтобы не прерывать представления концепций, будут использоваться обширные сноски, многочисленные примеры и дополнительная информация.
Достижение таких же результатов, как в компании Facebook, требует наличия автоматизированного механизма, развертывающего код в производственную среду. Если процесс развертывания существует много лет, то особенно необходимо в полной мере документировать все его этапы, например в картах процесса создания продукта. Их мы можем собрать в ходе рабочих совещаний или постепенно пополняя документацию (например, в форме wiki).
После того как мы задокументировали процесс, наша цель — упростить и автоматизировать как можно больше выполняемых вручную шагов, а именно:
• упаковка кода подходящим для развертывания образом;
• создание предварительно настроенных образов виртуальных машин или контейнеров;
• автоматизация развертывания и настройки конфигурации промежуточного ПО;
• копирование пакетов или файлов на производственные серверы;
• перезапуск серверов, приложений или служб;
• создание файлов конфигурации из шаблонов;
• запуск автоматизированных smoke-тестов, чтобы убедиться, что система работает и правильно настроена;
• запуск процедур тестирования;
• сценарии и автоматизация миграции базы данных.
Где это возможно, будем перерабатывать архитектуру с целью удаления некоторых шагов, в частности требующих длительного времени. Желая уменьшить опасность ошибок и потери знаний, мы также хотели бы сократить не только сроки выполнения, но и в максимально возможной степени — количество случаев, когда работа передается от одного отдела другому.
Читать дальшеИнтервал:
Закладка:

