Стюарт Рассел - Совместимость. Как контролировать искусственный интеллект

- Название:Совместимость. Как контролировать искусственный интеллект
- Автор:
- Жанр:
- Издательство:Альпина нон-фикшн
- Год:2021
- Город:Москва
- ISBN:978-5-0013-9370-2
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Стюарт Рассел - Совместимость. Как контролировать искусственный интеллект краткое содержание
В своей новаторской книге автор рассказывает, каким образом люди уже научились использовать ИИ, в диапазоне от смертельного автономного оружия до манипуляций нашими предпочтениями, и чему еще смогут его научить. Если это случится и появится сверхчеловеческий ИИ, мы столкнемся с сущностью, намного более могущественной, чем мы сами. Как гарантировать, что человек не окажется в подчинении у сверхинтеллекта?
Для этого, полагает Рассел, искусственный интеллект должен строиться на новых принципах. Машины должны быть скромными и альтруистичными и решать наши задачи, а не свои собственные.
О том, что это за принципы и как их реализовать, читатель узнает из этой книги, которую самые авторитетные издания в мире назвали главной книгой об искусственном интеллекте.
Все, что может предложить цивилизация, является продуктом нашего интеллекта; обретение доступа к существенно превосходящим интеллектуальным возможностям стало бы величайшим событием в истории. Цель этой книги — объяснить, почему оно может стать последним событием цивилизации и как нам исключить такой исход.
Введение понятия полезности — невидимого свойства — для объяснения человеческого поведения посредством математической теории было потрясающим для своего времени. Тем более что, в отличие от денежных сумм, ценность разных ставок и призов с точки зрения полезности недоступна для прямого наблюдения.
Первыми, кто действительно выиграет от появления роботов в доме, станут престарелые и немощные, которым полезный робот может обеспечить определенную степень независимости, недостижимую иными средствами. Даже если робот выполняет ограниченный круг заданий и имеет лишь зачаточное понимание происходящего, он может быть очень полезным.
Очевидно, действия лояльных машин должны будут ограничиваться правилами и запретами, как действия людей ограничиваются законами и социальными нормами. Некоторые специалисты предлагают в качестве решения безусловную ответственность.
Совместимость. Как контролировать искусственный интеллект - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Были времена, когда подобных действий как таковых не существовало. Например, чтобы получить право на полет на самолете в 1910 г., нужно было пройти долгий, затратный и непредсказуемый процесс изучения вопроса, написания писем и переговоров с пионерами авиации. В библиотеку добавились и другие действия: мы пишем электронные письма, гуглим и пользуемся Uber. В 1911 г. Альфред Норт Уайтхед писал: «Цивилизация развивается, расширяя количество важных операций, которые мы можем осуществлять не задумываясь» [127] Раннее упоминание важности использования комплексных операций как новых примитивных действий см. в кн.: Alfred North Whitehead, An Introduction to Mathematics (Henry Holt, 1911).
.
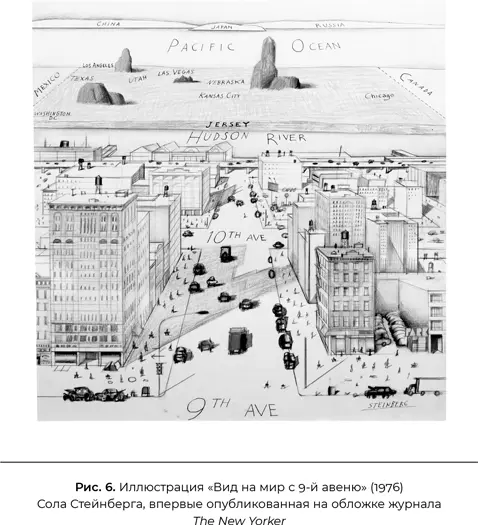
Знаменитая обложка Сола Стейнберга для журнала The New Yorker (рис. 6) блистательно демонстрирует в пространственной форме, как интеллектуальный агент управляет собственным будущим. Непосредственное будущее исключительно тонко детализировано — в действительности мой мозг уже загрузил конкретные последовательности актов двигательного контроля для того, чтобы напечатать следующие слова. Если заглянуть немного вперед, деталей становится меньше: так, я планирую закончить этот раздел, перекусить, написать еще фрагмент и посмотреть, как Франция играет с Хорватией в Кубке мира. Еще дальше в будущем мои планы становятся более обширными, но и более расплывчатыми: вернуться из Парижа в Беркли в начале августа, прочитать курс аспирантам и закончить эту книгу. По мере движения индивида во времени будущее приближается к настоящему, и планы становятся более подробными, тогда как могут появиться и новые неопределенные планы на более отдаленное будущее. Планы ближайшего будущего становятся такими подробными, что исполняются напрямую системой управления движением.
В настоящее время у нас имеются лишь некоторые фрагменты этой общей картины для ИИ-систем. При наличии иерархии абстрактных действий, в том числе знания о том, как систематизировать каждое из абстрактных действий в подраздел, состоящий из конкретных действий, у нас есть алгоритмы, которые могут составить комплексные планы достижения поставленных целей. Это алгоритмы, способные выполнять абстрактные иерархические планы так, что у агента всегда имеется «готовое к исполнению» примитивное физическое действие, даже если будущие действия остаются абстрактными и пока невыполнимы.
Главным отсутствующим элементом пазла является метод построения иерархии абстрактных действий. Например, можно ли начинать с нуля, когда робот будет знать только, что может посылать разные электрические токи к различным двигателям, и самостоятельно выяснять, какие действия нужно предпринять, чтобы стоять? Важно понимать, что я не спрашиваю, можем ли мы научить робота стоять, — это легко сделать методом обучения с подкреплением, вознаграждая робота за то, что его голова остается как можно дальше от пола [128] Работа, демонстрирующая, что смоделированный робот способен совершенно самостоятельно научиться вставать: John Schulman et al., «High-dimensional continuous control using generalized advantage estimation», arXiv:1506.02438 (2015). Видеодемонстрация доступна на YouTube: youtube.com/watch?v=SHLuf2ZBQSw .
. Чтобы научить робота стоять, обучающий его человек уже должен знать, что значит стоять , и идентифицировать правильный вознаграждающий сигнал. Мы хотим, чтобы робот самостоятельно узнал, что стояние — это полезное абстрактное действие, обеспечивающее выполнение обязательного условия (пребывание в вертикальном положении) для того, чтобы ходить, бегать, здороваться за руку, или заглядывать в окно, следовательно, является частью многих абстрактных планов достижения всевозможных целей. Аналогично мы хотим, чтобы робот овладел для себя такими действиями, как перемещение с одного места на другое, подбирание предметов, открывание дверей, завязывание узлов, приготовление ужина, поиск моих ключей, строительство домов, и многими другими, не имеющими названия ни на одном человеческом языке, потому что мы, люди, их еще не открыли.
Я считаю эту способность самым важным шагом на пути к достижению ИИ человеческого уровня. Это стало бы, если снова воспользоваться фразой Уайтхеда, расширением количества важных операций, которые ИИ-системы способны выполнять не задумываясь. Многочисленные исследовательские группы по всему миру упорно трудятся над решением этой проблемы. Например, в статье компании DeepMind от 2018 г. о достижении человеческого уровня в компьютерной игре Quake III Arena Capture the Flag утверждается, что их обучающаяся система «по-новому конструирует временное иерархическое пространство представлений для обеспечения… согласованных по времени последовательностей действий» [129] Описание системы обучения с подкреплением, которая учится играть в видеоигру «Захват флага»: Max Jaderberg et al., «Human-level performance in first-person multiplayer games with population-based deep reinforcement learning», arXiv:1807.01281 (2018).
. (Я не вполне понимаю, что имеется в виду, но это, определенно, похоже на приближение к цели изобретения новых высокоуровневых действий.) Я подозреваю, что у нас пока нет полного ответа, но это достижение, которое может случиться в любой момент, когда удастся просто правильным образом свести воедино уже имеющиеся идеи.
Интеллектуальные машины, обладающие этой способностью, смогут заглядывать в будущее дальше людей, а также учитывать намного больше информации. Эти две способности неизбежно ведут к принятию лучших решений в реальном мире. В конфликтной ситуации любого типа между людьми и машинами мы быстро обнаружим, как Гарри Каспаров и Ли Седоль, что каждый наш шаг просчитан заранее и нейтрализован. Мы проиграем раньше, чем игра начнется.
Если управление деятельностью в реальном мире выглядит сложным, представьте, какой головоломкой для вашего бедного мозга является управление деятельностью «самого сложного объекта в известной нам Вселенной» — его самого. Мы не начинаем думать, ходить или играть на пианино, если не знаем как это делается. Мы этому учимся. Мы можем в определенной степени выбирать , какие мысли иметь. (Попробуйте подумать о сочном гамбургере или таможенных правилах Болгарии, выбор за вами!) В каком-то смысле наша мыслительная деятельность более сложна, чем практическая деятельность, потому что наш мозг имеет намного больше «движущихся частей», чем тело, и двигаются они намного быстрее. Это относится и к компьютерам: на каждый ход, который AlphaGo делает на игровой доске, машина совершает миллионы или миллиарды единиц вычисления, каждая из которых включает в себя добавление ветви к дереву опережающего поиска и оценку игровой позиции в конце этой ветви. Каждая из этих единиц вычисления осуществляется, потому что программа делает выбор относительно того, какую часть дерева исследовать следующей. Очень приблизительно говоря, AlphaGo выбирает вычисления, которые, по ее ожиданиям, улучшат ее последующее решение на доске.
Читать дальшеИнтервал:
Закладка:




![Мередит Бруссард - Искусственный интеллект [Пределы возможного] [litres]](/books/1073206/meredit-brussard-iskusstvennyj-intellekt-predely.webp)




