Компьютерра - Журнал «Компьютерра» № 13 от 04 апреля 2006 года

- Название:Журнал «Компьютерра» № 13 от 04 апреля 2006 года
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Компьютерра - Журнал «Компьютерра» № 13 от 04 апреля 2006 года краткое содержание
Журнал «Компьютерра» № 13 от 04 апреля 2006 года - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
На этапе композиции можно выполнять условные присваивания, вычислять линейную комбинацию векторов, так же как и на этапе фильтрации. Однако эти действия не поддерживаются всеми современными платами для интересующих нас чисел высокой точности. Но если вас устроит «половинная» точность (16 бит), то оценка производительности может быть поднята еще выше.
Вы должны понимать, что это крайне оптимистичные оценки, реально достижимая скорость счета заметно ниже. На практике не всегда удается задействовать даже вершинные процессоры. Дело в том, что до Shader Model 3.0 они были лишены доступа к текстурам, то есть к памяти. К тому же их вывод не записывает в память непосредственно, а лишь определяет области, которые будут обсчитаны пиксельными процессорами. Конечно, и этим можно умело пользоваться, чтобы уменьшить размер и повысить скорость пиксельных шейдеров, но трудоемкость разработки всей программы для GPU сильно возрастает. Впрочем, здесь тоже ожидается скорый прогресс — уже вовсю говорят об унифицированных шейдерных процессорах, способных выполнять обработку как вершин, так и пикселов и не простаивать при любом виде нагрузки.
Для совершения первых шагов в освоении сопроцессора GPU начинающий разработчик должен научиться переводить графические термины на более привычный ему компьютерный язык.
Самое главное — понимание организации памяти. Универсальной встроенной структурой данных в GPU является текстура. Текстуры бывают одномерные, двухмерные и трехмерные[Т. Кормен, Ч. Лейзерсон, Р. Ривест. Алгоритмы. Построение и анализ. — М.: МЦНМО, 2000]. Это прямой аналог многомерному массиву. Пиксел текстуры (тексел) -элемент массива. К сожалению, максимальные ширина, высота и глубина текстуры строго ограничены. Этот предел зависит от платы и от размерности и обычно равен 2048 или 4096. Поэтому одномерные текстуры становятся малоинтересными — в них вмещается слишком мало данных. Трехмерные текстуры отпадают по другой причине — они могут быть только считаны, но рисование в них невозможно. Остаются только двухмерные текстуры, в которые нужно научиться упаковывать все прочие структуры данных. Заметим, что эффективная размерность всех текстур на единицу больше, поскольку каждый тексел может содержать до четырех цветовых компонентов. Например, длинный одномерный массив можно упаковать таким образом: первые четыре элемента записываются в тексел на пересечении первой строки и первого столбца, следующие четыре — в тексел из второго столбца и так до исчерпания первой строки, затем всё продолжается со следующей строки и т. д.
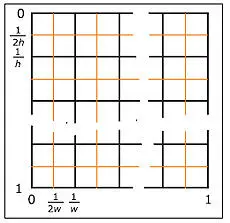
Любопытна система адресации в текстуре, которая осуществляется заданием по каждой координате действительного числа из диапазона [0,1]. Расстояние (изменение индекса при переходе) между соседними текселами уже не 1, как в обычном массиве, а зависит от разрешения текстуры (рис. 3). Для получения точного значения тексела необходимо указать координаты центра его «квадратика», при запросе по другому адресу результат будет зависеть от текущего режима фильтрации.
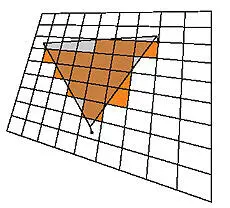
Запись данных в текстуру достигается назначением ее в качестве цели рендеринга (render target). Последующее рисование какой-либо фигуры фактически выбирает обновляемые элементы текстуры (рис. 4). Обычно рисуют один большой треугольник, покрывающий цель рендеринга с запасом, либо прямоугольник точно совпадающих размеров. Неудобно то, что координаты углов фигур нужно задавать уже не в текстурных, а в отличающихся от них экранных (viewport) координатах. Итак, координаты вершины определяют рассчитываемые фрагменты. Входные аргументы пиксельному шейдеру передаются через ассоциированные с вершиной данные, в первую очередь через текстурные координаты.
Процедура обработки одинакова для всех пикселов. Поэтому о пиксельном шейдере можно думать как о теле некоторого цикла. Также можно, рисуя меньшие фигуры и «играя» с тестом глубины, применять различные шейдеры избирательно. Такая необходимость возникает, когда алгоритмы обработки внутренних и приграничных точек текстуры существенно отличаются и их невозможно или нецелесообразно совмещать в одном шейдере.
Сейчас мы уже знаем, что GPU способен применять одинаковую программу для вычисления значения каждого элемента одного массива, основываясь на данных других массивов. Есть ли алгоритмы, которые формулируются именно таким образом? Оказывается, есть. К этому классу относятся, например, методы фильтрации изображений и часть способов приближенного решения дифференциальных уравнений, отражающих динамические явления физики. Именно такие алгоритмы проще всего переносятся на GPU, и именно на них достигается наибольшее ускорение.
Давайте рассмотрим что-нибудь посложнее. Задача редукции массива заключается в нахождении какой-то скалярной функции его элементов. Это может быть сумма всех чисел массива, или величина максимума, или что-то в том же духе. Поскольку шейдер ограничен в количестве операций, за один проход рендеринга решить задачу решительно невозможно. Применяется следующий способ. Порождается вспомогательная текстура, размерами чаще всего вдвое меньше исходной по обеим осям. Используемый шейдер, заполняя ее, вычисляет функцию только от четырех величин. Затем вспомогательная текстура назначается на вход шейдера, а выходом служит еще вчетверо меньшая текстура. И так до получения текстуры из одного пиксела, которая содержит ответ (рис. 5). Число проходов составляет логарифм от начального размера массива.
Умножить матрицу на вектор при ограничениях Shader Model 2.0 тоже не так-то просто. Одно из определений гласит, что произведение является линейной комбинацией столбцов исходной матрицы, взятых с весами из второго сомножителя. Поступают таким образом. На первом шаге каждый элемент матрицы умножается на соответствующий ему вес — получается вторая матрица. Последующие шаги посвящаются комбинированию столбцов — редукции только по горизонтали.
Еще интереснее дела обстоят с сортировкой массива. Сразу понятно, что в случае с GPU понадобится второй вспомогательный массив из-за невозможности выполнять чтение и запись одновременно с одним массивом. Но на этом сложности не кончаются. Алгоритмы сортировки основываются на операции сравнить-и-обменять: для выбранных двух позиций в массиве производится сравнение элементов, и, если они нарушают порядок сортировки, происходит их обмен. В GPU, как мы помним, определение новых значений массива выполняется независимо, поэтому каждое сравнение приходится делать дважды. Но и это еще не все. Выбор позиций для очередной операции сравнить-и-обменять в быстрых последовательных алгоритмах зависит от результата сравнения в предыдущих операциях. К счастью, в теории параллельных вычислений уже разработана тема сортирующих сетей, которую можно адаптировать для GPU. Количество операций, выполняемых параллельным алгоритмом, больше, чем у лучших последовательных алгоритмов, и их отношение растет с ростом массива. Тем не менее, благодаря своей мощи, современные GPU не уступают в скорости сортировки, хотя о существенном ускорении речь пока не идет.
Читать дальшеИнтервал:
Закладка:









