Олег Деревенец - Песни о Паскале

- Название:Песни о Паскале
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Олег Деревенец - Песни о Паскале краткое содержание
Песни о Паскале - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Спокойно, друзья, в Паскале заготовлено все! Познакомьтесь с процедурой Read (без суффикса), которая почти не отличается от своей «сестренки» – принимает те же параметры и читает те же данные. Но при этом самовольно не продвигает позицию чтения в начало следующей строки. А нам того и нужно! Продвижение позиции чтения процедурой Read показано на рис. 67.
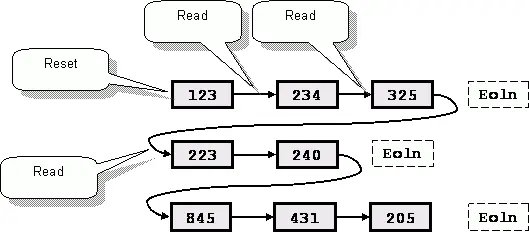
После чтения каждого числа позиция продвигается за это число и остается там. Следующий вызов процедуры прочитает очередное число в этой же строке и так далее, пока не будет достигнут конец строки. А потом? Потом позиция сдвинется в начало следующей строки, и чтение продолжится тем же чередом до конца файла.
Итак, решение найдено, и теперь для правильной работы программы надо лишь удалить суффикс в имени процедуры, то есть заменить вызов
Readln(aFile, N);
на вызов
Read(aFile, N);
Внесите это исправление в программу, сохраните её под именем «P_29_2» и проверьте, работает ли она.
Предвижу законный вопрос: к чему в языке две похожие процедуры, нельзя ли обойтись только Read? Нет, нельзя, – процедура Readln незаменима при построчной обработке файлов, и очень скоро вы в этом убедитесь.
• База данных – это организованное хранилище информации, приспособленное для быстрого её поиска. Простейшую базу данных можно создать редактором текста.
• Перед поиском данных в текстовом файле, надо установить позицию чтения в начало файла процедурой Reset.
• Процедура Readln после чтения затребованных данных продвигает позицию чтения в начало следующей строки. При этом все непрочитанные данные в текущей строке пропускаются.
• Процедура Read после чтения затребованных данных продвигает позицию чтения за последний прочитанный элемент. Она подходит для последовательного чтения данных без учета разбивки на строки.
А) Напишите программу для преобразования второго варианта базы данных «Police.txt» (с несколькими числами в строке) в первый вариант (по одному числу в строке). Или слабо?
Б) Можно ли в решении предыдущей задачи назначить одно и то же имя как входному, так и выходному файлам? Испытайте на практике.
Глава 30
Журнальная история

Давно ли вы заглядывали в классный журнал? Хорошо бы делать это раньше своих родителей. Ах, если бы журнал можно было и править!.. Нет, я не подбиваю вас подтирать оценки! Мы всего лишь подвергнем журнал статистической обработке. Статистика – это наука, находящая закономерности в массе данных. Она как тот холм, взобравшись на который, за деревьями видишь лес. Нужен пример? Пожалуйста.
В некой школе некоторого царства-государства для сравнения учеников и классов учредили рейтинги. Что такое рейтинг? – это вроде места в турнирной таблице. Чем выше рейтинг, тем сильнее спортсмен или команда, то есть ученик или класс. Определять рейтинг условились по средней оценке ученика или всего класса. Так, совокупность многих оценок заменялась одним числом – средним баллом. Когда вместо десятков чисел получаешь одно, – это и есть плод статистической обработки.
Вычисление средних оценок возложили на компьютер, заказав для этого программу. Входные данные для нее извлекались из журнала, который велся в виде текстового файла. Вот как выглядел входной файл, то есть классный журнал.
Акулова 3 5 4
Быков 5 5 5 5
Воронов 4 5 5 4
Галкина 3 4 3
Крокодилкин 4 3
А вот что получалось после обработки его упомянутой программой.
Номер Фамилия Количество Сумма Средний
оценок баллов балл
1 Акулова 3 12 4.0
2 Быков 4 20 5.0
3 Волков 4 18 4.5
4 Галкина 3 10 3.3
5 Крокодилкин 2 7 3.5
Стало быть, средний балл вычислялся как частное от деления суммы баллов на количество оценок, а результат записывался с одним знаком после запятой.
И все было хорошо, пока вирусная атака не уничтожила бесценную программу. А где распечатка исходника? Увы, к тому времени её погрызли мыши! Друзья, теперь надежда только на вас, выручайте школу!
С первого взгляда на задачу ясно: входной файл надо обрабатывать построчно, выбирая из каждой строки данные двух типов: строковые – фамилии учеников, и числа – их оценки. Это не так просто, как может показаться, а потому решать задачу будем в два счёта. На первом этапе упростим её, оставив во входном файле лишь оценки учеников, а полное решение отложим до следующей главы. Входной файл без фамилий будет теперь таким.
3 5 4
5 5 5 5
4 5 5 4
3 4 3
4 3
А в результате обработки мы должны получить такой выходной файл.
Номер Количество Сумма Средний
оценок баллов балл
1 3 12 4.0
2 4 20 5.0
3 4 18 4.5
4 3 10 3.3
5 2 7 3.5
Набросаем план предстоящего сражения, то есть блок-схемы алгоритмов. На рис. 68 показан алгоритм главной программы. Он очень похож на тот, что применялся при шифровании текста, и это объяснимо: и там, и здесь выполняется построчная обработка файла.
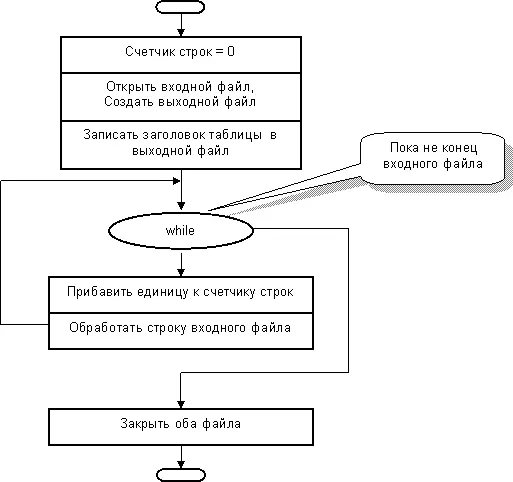
Рванув со старта, программа открывает входной файл, создает выходной и пишет туда заголовок таблицы – так называемую шапку. По окончании обработки оба файла будут закрыты. В этом алгоритме предусмотрен также и подсчет строк входного файла, необходимый для нумерации учеников в выходном файле.
Разобравшись с главной программой, сосредоточимся на обработке отдельной строки. Здесь заметно сходство со вторым вариантом полицейской базы данных (глава 29). И там, и тут читается ряд чисел, размещенных в одной строке. Но если в полицейской программе нам было безразлично, где кончается строка, то теперь иное дело, – ведь на следующей строке расположены оценки другого ученика! Нужен признак, сообщающий о достижении конца читаемой строки. Где его взять?
Ну, вы же понимаете, – в Паскале предусмотрено все! Познакомьтесь с функцией булевого типа по имени EoLn (от английского End of Line, что значит «конец строки»). Заголовок этой функции выглядит так:
Читать дальшеИнтервал:
Закладка:
