Эрик Реймонд - Искусство программирования для Unix

- Название:Искусство программирования для Unix
- Автор:
- Жанр:
- Издательство:Издательский дом Вильямс
- Год:неизвестен
- Город:Москва
- ISBN:5-8459-0791-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Эрик Реймонд - Искусство программирования для Unix краткое содержание
Книги, подобные этой, редко появляются на прилавках магазинов, поскольку за ними стоит многолетний опыт работы их авторов. Здесь описывается хороший стиль Unix- программирования, многообразие доступных языков программирования, их преимущества и недостатки, различные IPC-методики и инструменты разработки. Автор анализирует философию Unix, культуру и основные традиции сформированного вокруг нее сообщества. В книге объясняются наилучшие практические приемы проектирования и разработки программ в Unix. Вместе с тем описанные в книге модели и принципы будут во многом полезны и Windows-разработчикам. Особо рассматриваются стили пользовательских интерфейсов Unix-программ и инструменты для их разработки. Отдельная глава посвящена описанию принципов и инструментов для создания хорошей документации.
Книга будет полезной для широкой категории пользователей ПК и программистов.
Искусство программирования для Unix - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
В тени DocBook работает определенный вид программ, который называется анализатором корректности (validating parser). Первым этапом при форматировании DocBook-документа является его обработка анализатором корректности (клиентская часть DocBook-форматера). Данная программа сравнивает документ с DocBook DTD, для того чтобы гарантировать, что пользователь не нарушает структурных правил DTD (в противном случае серверная часть форматера, т.е. та часть, которая применяет таблицу стилей, может быть поставлена в тупик).
Анализатор корректности либо перехватывает ошибку, отправляя пользователю сообщение о тех местах, где структура документа нарушена, либо транслирует документ в поток XML-элементов и текста, которые будут скомбинированы сервером с информацией из таблицы стилей для создания отформатированного вывода.
Данный процесс в целом схематически изображен на рис. 18.1.
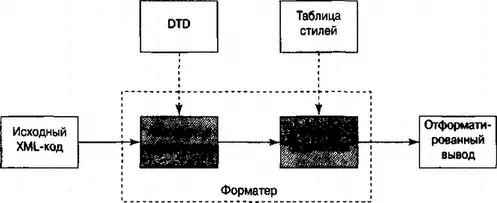
Рис. 18.1. Обработка структурированных документов
Часть диаграммы внутри пунктирного блока соответствует форматирующему программному обеспечению или инструментальной связке (toolchain) . Для того чтобы понять процесс, необходимо кроме очевидного и видимого ввода данных в форматер (исходного текста документа) учитывать два вида скрытого ввода форматера (DTD и таблица стилей).
18.5.2. Другие DTD-определения
Небольшое отступление к другим DTD-определениям поможет прояснить, какие сведения предыдущего раздела являются специфичными для DocBook, а какие являются общими для всех языков структурированной разметки.
TEI (Text Encoding Initiative, )— крупное, сложное DTD-определение, которое используется главным образом в академических учреждениях для компьютерной перезаписи литературных текстов. Применяемые в TEI связки Unix-инструментов состоят из множества тех же инструментов, которые задействованы в DocBook, но используются другие таблицы стилей и (естественно) другое DTD-определение.
XHTML, последняя версия HTML, также является XML-приложением, описанным DTD, что объясняет "родовое сходство" между XHTML- и DocBook-тегами. Инструментальная связка XHTML состоит из Web-браузеров, которые способны форматировать HTML как простой ASCII-текст, а также любого количества узкоспециальных утилит для печати HTML-текста.
Для того чтобы облегчить обмен структурированной информацией в других областях, таких как биоинформатика и банковское дело, поддерживаются также многие другие XML DTD-определения. Для того чтобы получить представление о доступном многообразии DTD-определений, можно воспользоваться списком репозитариев .
18.5.3. Инструментальная связка DocBook
Обычно для создания XHTML-документа из исходного DocBook-текета используется интерфейсный сценарий xmlto(1) . Ниже приводятся примерные команды.
bash$ xmlto xhtml foo.xml
bash$ ls *.html
ar01s02.html ar01s03.html ar01s04.html index.html
В данном примере XML-DocBook-документ с именем fоо.xml, содержащий три раздела верхнего уровня, преобразовывается в индексную страницу и три части. Также просто создать одну большую страницу.
bash$ xmlto xhtml-nochunks foo.xml
bash$ ls *.html
foo.html
Наконец, ниже приводятся команды для создания PostScript-представления для печати.
bash$ xmlto ps foo.xml # Создание PostScript
bash$ ls *.ps
foo.ps
Для того чтобы превратить существующие документы в HTML или PostScript, необходимо ядро, которое способно применить к данным документам комбинацию DocBook DTD и подходящей таблицы стилей. На рис. 18.2 показано, как для данной цели совместно используются инструменты с открытым исходным кодом.
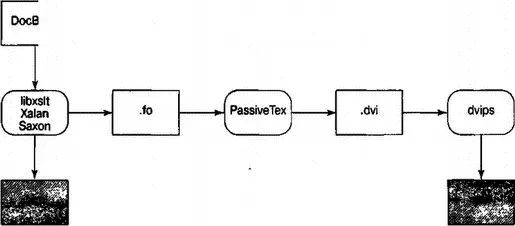
Рис. 18.2. Современная инструментальная связка XML-DocBook
Синтаксический анализ документа и его трансформация на основе таблицы стилей будет осуществляться одной из трех программ. Вероятнее всего, программой xsltproc , которая представляет собой синтаксический анализатор, поставляемый с Red Hat Linux. Два другие варианта представлены Java-программами Saxon и Xalan .
Сгенерировать высококачественный XHTML-документ из любого DocBook-текста сравнительно просто. Большую роль в данном случае играет тот факт, что XHTML является просто другим XML DTD-определением. Преобразование в HTML-документ осуществляется путем применения довольно простой таблицы стилей. Данный способ позволяет также просто генерировать RTF-документы, а из XHTML или RTF легко создать простой ASCII-текст.
Сложный случай представляет собой печать. Создание высококачественного распечатываемого вывода, что на практике означает преобразование в формат Adobe PDF (Portable Document Format), затруднено. Правильное решение данной задачи требует алгоритмического воспроизведения способа мышления наборщика (человека) при переходе от содержания к уровню представления.
Таким образом, прежде всего, с помощью таблицы стилей структурированная разметка DocBook преобразовывается в другой диалект XML — FO (Formatting Objects — объекты форматирования). FO-разметка является ярко выраженной разметкой уровня представления. Ее можно представить как некоторый функциональный XML-эквивалент troff . Данную разметку необходимо преобразовывать в PostScript для упаковки в PDF.
В инструментальной связке, поставляемой с Red Hat Linux, данная задача решается с помощью T EX-макропакета, который называется PassiveTeX. Данный макрос преобразовывает объекты форматирования, генерируемые xsltproc, в язык T EX Дональда Кнутта. Затем вывод T EX, называемый форматом DVI (DeVice Independent), преобразовывается в PDF.
Сложная цепь XML, T EX-макрос, DVI, PDF — неуклюжая конструкция. Она "гремит, хрипит и имеет уродливые наросты". Шрифты являются значительной проблемой, поскольку XML, T EX и PDF имеют очень разные модели. Кроме того, серьезные трудности связаны с поддержкой интернационализации и локализации. Единственной привлекательной особенностью данной конструкции является то, что она работает.
Изящным способом разрешения описываемой проблемы будет использование FOP, непосредственного преобразования FO в PostScript, разрабатываемого проектом Apache. С помощью FOP проблема интернационализации даже если и не будет решена полностью, то, по крайней мере, будет определена. XML-инструменты поддерживают Unicode на всем пути к FOP. Преобразование глифов Unicode в PostScript-шрифт является также исключительно проблемой FOP. Единственным недостатком данного подхода является то, что он пока не работает. В середине 2003 года FOP находился в незаконченной альфа-стадии. FOP-преобразование можно использовать, однако оно содержит множество "необработанных углов" и характеризуется недостатком функций.
На рис. 18.3 иллюстрируется схема инструментальной связки FOP.
Читать дальшеИнтервал:
Закладка:




