Олег Цилюрик - QNX/UNIX: Анатомия параллелизма

- Название:QNX/UNIX: Анатомия параллелизма
- Автор:
- Жанр:
- Издательство:Символ-Плюс
- Год:2006
- Город:Санкт-Петербург
- ISBN:5-93286-088-Х
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Олег Цилюрик - QNX/UNIX: Анатомия параллелизма краткое содержание
Книга адресована программистам, работающим в самых разнообразных ОС UNIX. Авторы предлагают шире взглянуть на возможности параллельной организации вычислительного процесса в традиционном программировании. Особый акцент делается на потоках (threads), а именно на тех возможностях и сложностях, которые были привнесены в технику параллельных вычислений этой относительно новой парадигмой программирования. На примерах реальных кодов показываются приемы и преимущества параллельной организации вычислительного процесса. Некоторые из результатов испытаний тестовых примеров будут большим сюрпризом даже для самых бывалых программистов. Тем не менее излагаемые техники вполне доступны и начинающим программистам: для изучения материала требуется базовое знание языка программирования C/C++ и некоторое понимание «устройства» современных многозадачных ОС UNIX.
В качестве «испытательной площадки» для тестовых фрагментов выбрана ОСРВ QNX, что позволило с единой точки зрения взглянуть как на специфические механизмы микроядерной архитектуры QNX, так и на универсальные механизмы POSIX. В этом качестве книга может быть интересна и тем, кто не использует (и не планирует никогда использовать) ОС QNX: программистам в Linux, FreeBSD, NetBSD, Solaris и других традиционных ОС UNIX.
QNX/UNIX: Анатомия параллелизма - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Другой путь — посылка процессу извне (из другого процесса) сигнала, реакцией на который (предопределенной или установленной) является завершение процесса (подробнее о сигналах и реакциях см. ниже). В противовес естественному завершению такое принудительное завершение извне в [12] (по крайней мере, в отношении потоков) названо отменой, и именно этим термином мы будем пользоваться далее, чтобы отчетливо отмечать, о каком варианте завершения идет речь. (Такая же терминология будет использоваться нами и относительно завершения потока.)
Здесь уместно сделать краткое отступление относительно «живучести», как это названо у У. Стивенса [2], или времени жизни объектов IPC, что в равной мере может быть отнесено не только к объектам IPC, но и ко всем прочим объектам операционной системы. У. Стивенс делит все объекты по времени жизни на:
• Объекты, время жизни которых определяется процессом (process-persistent). Такой объект существует до тех пор, пока не будет закрыт последним процессом, который его использует. Примерами такого объекта являются неименованные и именованные программные каналы (pipes, FIFO).
• Объекты, время жизни которых определяется ядром системы (kernel-persistent). Такой объект существует до перезагрузки ядра или явного удаления объекта. Примерами этого класса объектов являются семафоры (именованные) и разделяемая память.
• Объекты, время жизни которых определяется файловой системой (filesystem-persistent). Такой объект отображается на файловую систему и существует до тех пор, пока не будет явно удален. Примерами этого класса объектов в различных ОС в зависимости от реализации могут быть очереди сообщений POSIX, семафоры и разделяемая память.
Квалификация каждого из объектов по времени жизни отнюдь не тривиальная задача. Объекты, отнесенные к одному классу, мигрируют в другой при переходе от одной ОС к другой в зависимости от деталей их реализации.
Проблемы завершения и особенно отмены процесса могут возникать, если процесс оперирует с объектами, время жизни которых превышает process-persistent. Мы еще много раз коснемся этой проблемы при рассмотрении завершения потоков, так как там она может возникать и в отношении всех process-persistent-объектов, и для ее разрешения в технике потоков даже предложены специальные технологии, о которых мы детально поговорим далее, при рассмотрении потоков.
Соображения производительности
Интересны не только затраты на порождение нового процесса (мы еще будем к ним неоднократно возвращаться), но и то, насколько «эффективно» сосуществуют параллельные процессы в ОС, насколько быстро происходит переключение контекста с одного процесса на другой. Для самой грубой оценки этих затрат создадим простейшее приложение ( файл p5.cc ):
#include
#include
#include
#include
#include
#include
int main(int argc, char* argv[]) {
unsigned long N = 1000;
if (argc > 1 && atoi(argv[1]) > 0)
N = atoi(argv[1]);
pid_t pid = fork();
if (pid == -1)
cout << "fork error" << endl, exit(EXIT_FAILURE);
uint64_t t = ClockCycles();
for (unsigned long i = 0; i < N; i++) sched_yield();
t = ClockCycles() - t;
delay(200);
cout << pid << "\t: cycles - " << t << "; on sched - " << (t/N) / 2 << endl;
exit(EXIT_SUCCESS);
}
Два одновременно выполняющихся процесса настолько симметричны и идентичны, что они даже не анализируют PID после выполнения fork(), они только в максимальном темпе «перепасовывают» друг другу активность, как волейболисты делают это с мячом (рис. 2.2).
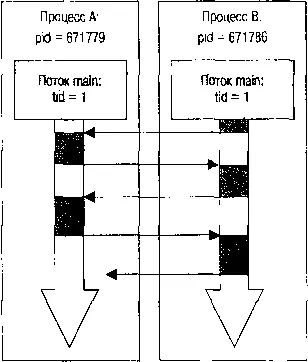
Рис. 2.2. Симметричное взаимодействие потоков
Рисунок 2.2 иллюстрирует взаимодействие двух идентичных процессов: вся их «работа» состоит лишь в том, чтобы как можно быстрее передать управление партнеру. Такую схему, когда два и более как можно более идентичных потоков или процессов в максимально высоком темпе (на порядок превосходящем последовательность «естественной» RR-диспетчеризации) обмениваются активностью, мы будем неоднократно использовать в дальнейшем для различных механизмов, называя ее для простоты «симметричной схемой».
Чтобы максимально упростить код приложения, при его написании мы не трогали события «естественной» диспетчеризации, имеющие место при RR-диспетчеризации каждые 4 системных тика (по умолчанию это ~4 миллисекунды). Как сейчас покажут результаты, события принудительной диспетчеризации происходят с периодичностью порядка 1 микросекунды, т.e. в 4000 раз чаще, и возмущения, возможно вносимые RR-диспетчеризацией, можно считать не настолько существенными.
Вот результаты выполнения этой программы:
# nice -n-19 p5 1000000
1069102 : cycles - 1234175656; on sched — 617
0 : cycles - 1234176052; on sched - 617
# nice -n-19 p5 100000
1003566 : cycles - 123439225; on sched — 617
0 : cycles - 123440347; on sched - 617
# nice -n-19 p5 10000
1019950 : cycles - 12339084; on sched — 616
0 : cycles - 12341520; on sched - 617
# nice -n-19 p5 1000
1036334 : cycles - 1243117; on sched — 621
0 : cycles - 1245123; on sched - 622
# nice -n-19 p5 100
1052718 : cycles - 130740; on sched — 653
0 : cycles - 132615; on sched - 663
Видна на удивление устойчивая оценка, практически не зависящая от общего числа актов диспетчеризации, изменяющегося на 4 порядка.
Отбросив мелкие добавки, привносимые инкрементом и проверкой счетчика цикла, можно считать, что передача управления от процесса к процессу требует порядка 600 циклов процессора (это порядка 1,2 микросекунды на компьютере 533 МГц, на котором выполнялся этот тест).
Потоки
Последующие расширения [14] Часто в публикациях ссылаются на расширения реального времени POSIX 1003b (1993). Но POSIX 1003b не описывают группу pthread_* , хотя именно в этой редакции определены семафоры sem_t . У. Стивенс [2] указывает, что программные потоки POSIX определены в редакции 1003.1 (1995).
POSIX специфицируют широкий спектр механизмов «легких процессов» — потоков (группа API pthread_*()). Техника потоков вводит новую парадигму программирования вместо уже ставших традиционными UNIX-методов. Это обстоятельство часто недооценивается. Например, использование pthread_create()вместо fork()может на порядки повысить скорость реакций, особенно в ОС с отсутствием механизмов COW (copy on write) при создании дубликатов физических страниц RAM сегментов данных (таких как QNX, хотя механизмы COW вряд ли вообще применимы в ОС реального времени) [4]. Другой пример: использование множественных потоков вместо ожиданий на множестве дескрипторов в операторе select().
Однако очень часто эти две парадигмы, традиционная и потоковая, не сочетаются в рамках единого кода из-за небезопасности (not thread safe) традиционных механизмов UNIX ( fork(), select()и др.) в многопоточной среде. Тогда приходится использовать либо одну, либо другую парадигму как альтернативы, не смешивая их между собой. Или смешивать, но с большой осторожностью и с хорошим пониманием того, что при этом может произойти в каждом случае.
Интервал:
Закладка:







