Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ

- Название:Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
- Автор:
- Жанр:
- Издательство:ДМК Пресс
- Год:2012
- Город:Москва
- ISBN:978-5-94074-448-1
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ краткое содержание
Книга «Параллельное программирование на С++ в действии» не предполагает предварительных знаний в этой области. Вдумчиво читая ее, вы научитесь писать надежные и элегантные многопоточные программы на С++11. Вы узнаете о том, что такое потоковая модель памяти, и о том, какие средства поддержки многопоточности, в том числе запуска и синхронизации потоков, имеются в стандартной библиотеке. Попутно вы познакомитесь с различными нетривиальными проблемами программирования в условиях параллелизма.
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Да, но ведь это относится к однопоточным программам, я-то тут при чем? — спросите вы. А все дело в контекстном переключении. Если количество потоков в системе превышает количество ядер, то каждое ядро будет исполнять несколько потоков. Это увеличивает давление на кэш, поскольку мы пытаемся сделать так, чтобы разные потоки обращались к разным строкам кэша — во избежание ложного разделения. Следовательно, при переключении потоков процессором вероятность перезагрузки строк кэша возрастает, если данные каждого потока находятся в разных строках кэша. Если потоков больше, чем ядер или процессоров, то операционная система может назначить потоку один процессор в течение одного кванта времени и другой — в следующем кванте. В результате строки кэша, содержащие данные этого потока, придётся передавать из одного кэша в другой. Чем больше таких передач, тем больше на них уходит времени. Конечно, операционные системы стараются избежать такого развития событий, но иногда это все же происходит и приводит к падению производительности.
Проблемы, связанные с контекстным переключением, возникают особенно часто, когда количество готовых к выполнению потоков намного превышает количество ожидающих . Мы уже говорили об этом феномене, который называется превышением лимита.
8.2.5. Превышение лимита и чрезмерное контекстное переключение
В многопоточных программах количество потоков нередко превышает количество процессоров, если только не используется массивно параллельное оборудование. Однако потоки часто тратят время на ожидание внешнего ввода/вывода, освобождения мьютекса, сигнала условной переменной и т.д., поэтому серьезных проблем не возникает. Наличие избыточных потоков позволяет приложению выполнять полезную работу, а не простаивать, пока потоки чего-то ждут.
Но не всегда это хорошо. Если избыточных потоков слишком много , то даже готовых к выполнению потоков будет больше, чем процессоров, и операционная система будет вынуждена интенсивно переключать потоки, чтобы никого не обделить временными квантами. В главе 1 мы видели, что это приводит к возрастанию накладных расходов на контекстное переключение, а также к проблемам с кэш-памятью из-за локальности. Превышение лимита может возникать, когда задача порождает новые потоки без ограничений, как, например, в алгоритме рекурсивной сортировки из главы 4, или когда количество потоков, естественно возникающих при распределении работы но типам задач, превышает количество процессоров, а рабочая нагрузка носит счетный характер и мало связана с вводом/выводом.
Количество потоков, запускаемых из-за особенностей алгоритма распределения данных, можно ограничить, как показано в разделе 8.1.2. Если же превышение лимита обусловлено естественным распределением работы, то тут ничего не поделаешь, остается разве что выбрать другой способ распределения. Но в таком случае для выбора подходящего распределения может потребоваться больше информации о целевой платформе, чем вы располагаете, поэтому заниматься этим следует лишь тогда, когда производительность неприемлема и можно убедительно продемонстрировать, что изменение способа распределения действительно повышает быстродействие.
Есть и другие факторы, влияющие на производительность многопоточной программы. Например, стоимость перебрасывания кэша может существенно зависеть от того, оснащена ли система двумя одноядерными процессорами или одним двухъдерным, даже если тип и тактовая частота процессоров одинаковы. Однако все основные факторы, эффект которых проявляется наиболее наглядно, были перечислены выше. Теперь рассмотрим, как от них зависит проектирование кода и структур данных.
8.3. Проектирование структур данных для повышения производительности многопоточной программы
В разделе 8.1 мы видели различные способы распределения работы между потоками, а в разделе 8.2 — факторы, от которых может зависеть производительность программы. Как воспользоваться этой информацией при проектировании структур данных для многопоточного кода? Этот вопрос отличается от рассмотренных в главах 6 и 7, где основное внимание было уделено проектированию структур данных, безопасных относительно одновременного доступа. В разделе 2 было показано, что размещение в памяти данных, используемых одним потоком, тоже может иметь значение, даже если эти данные ни с какими другими потоками не разделяются.
Основное, о чем нужно помнить при проектировании структур данных для многопоточной программы, — это конкуренция, ложное разделение и локальность данных . Все три фактора могут оказать большое влияние на производительность, так что нередко добиться улучшения удается, просто изменив размещение данных в памяти или распределение данных между потоками. Начнем с низко висящего плода: распределения элементов массива между потоками.
8.3.1. Распределение элементов массива для сложных операций
Допустим, что программа, выполняющая сложные математические расчеты, должна перемножить две больших квадратных матрицы. Элемент в левом верхнем углу результирующей матрицы получается следующим образом: каждый элемент первой строки левой матрицы умножается на соответственный элемент первого столбца правой матрицы и полученные произведения складываются. Чтобы получить элемент результирующей матрицы, расположенный на пересечении второй строки и первого столбца, эта операция повторяется для второй строки левой матрицы и первого столбца правой матрицы. И так далее. На рис. 8.3 показано, что элемент результирующей матрицы на пересечении второй строки и третьего столбца получается суммированием попарных произведений элементов второй строки левой матрицы и третьего столбца правой.
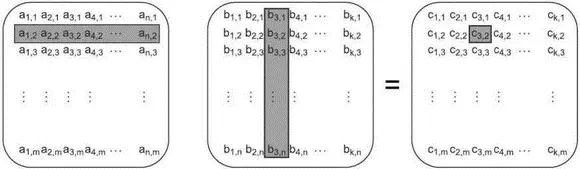
Рис. 8.3.Умножение матриц
Теперь предположим, что матрицы содержат по несколько тысяч строк и столбцов, иначе заводить несколько потоков для оптимизации умножения не имеет смысла. Обычно, если матрица не разрежена, то она представляется большим массивом в памяти, в котором сначала идут все элементы первой строки, потом все элементы второй строки и так далее. Следовательно, для перемножения матриц нам понадобятся три огромных массива. Чтобы добиться оптимальной производительности, мы должны внимательно следить за порядком доступа к данным, а особенно за операциями записи в третий массив.
Существует много способов распределить эту работу между потоками. В предположении, что строк и столбцов больше, чем имеется процессоров, можно поручить каждому потоку вычисление нескольких столбцов или строк результирующей матрицы или даже вычисление какой-то ее прямоугольной части.
Читать дальшеИнтервал:
Закладка: