Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум

- Название:Системное программное обеспечение. Лабораторный практикум
- Автор:
- Жанр:
- Издательство:Array Издательство «Питер»
- Год:2005
- Город:Санкт-Петербург
- ISBN:978-5-469-00391-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум краткое содержание
Книга ориентирована на студентов, обучающихся в технических вузах по специальностям, связанным с вычислительной техникой. Но она будет также полезна всем, чья деятельность так или иначе касается разработки программного обеспечения.
Системное программное обеспечение. Лабораторный практикум - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Текст программы распознавателя
Кроме перечисленных выше модулей необходим еще модуль, обеспечивающий интерфейс с пользователем. Как и в лабораторной работе № 1, этот модуль (FormLab2) реализует графическое окно TLab2Form на основе класса TForm библиотеки VCL и включает в себя две составляющие:
• файл программного кода (файл FormLab2.pas);
• файл описания ресурсов пользовательского интерфейса (файл FormLab2.dfm).
Кроме описания интерфейсной формы и ее органов управления модуль FormLab2 содержит переменную (listLex), в которую записывается ссылка на таблицу лексем.
Интерфейсная форма, описанная в модуле, содержит следующие основные органы управления:
• многостраничную вкладку (PageControll) с двумя закладками (SheetFile и SheetLexems) под названиями «Исходный файл» и «Таблица лексем» соответственно;
• на закладке SheetFilе:
– поле ввода имени файла (EditFile), кнопка выбора имени файла из каталогов файловой системы (BtnFile), кнопка чтения файла (BtnLoad);
– многострочное поле для отображения прочитанного файла (Listldents);
• на закладке SheetLexems:
– сетка (GridLex) с тремя колонками для отображения данных о прочитанных лексемах;
• кнопка завершения работы с программой (BtnExit).
Внешний вид двух закладок этой формы приведен на рис. 2.3 и 2.4.
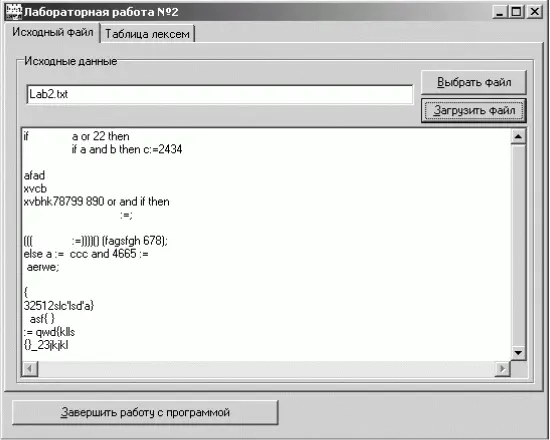
Рис. 2.3. Внешний вид первой закладки интерфейсной формы для лабораторной работы № 2.
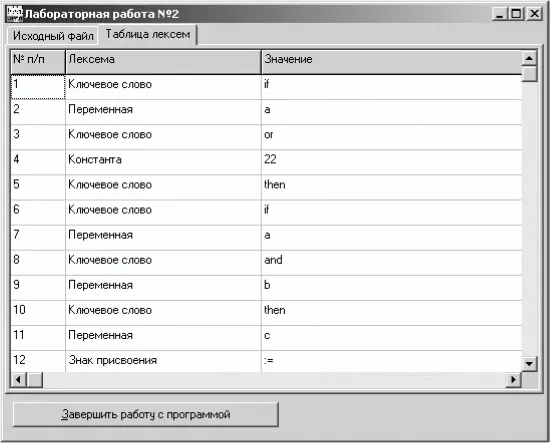
Рис. 2.4. Внешний вид второй закладки интерфейсной формы для лабораторной работы № 2.
Чтение содержимого входного файла организовано точно так же, как в лабораторной работе № 1.
После чтения файла создается таблица лексем (ссылка на нее запоминается в переменной listLex) и вызывается функция MakeLexList, результат работы которой помещается во временную переменную iErr.
Если обнаружена ошибка, пользователю выдается сообщение об этом и указатель в списке строк позиционируется на место, где обнаружена ошибка.
Если ошибок не обнаружено, то на основании считанной таблицы лексем listLex заполняется сетка GridLex, которая очень удобна для наглядного представления таблицы лексем:
• первая колонка – порядковый номер лексемы;
• вторая колонка – тип лексемы (ее внешний вид);
• третья колонка – информация о лексеме.
Полный текст программного кода модуля интерфейса с пользователем приведен в листинге П2.4 в приложении 2, а описание ресурсов пользовательского интерфейса – в листинге П2.5 в приложении 2.
Полный текст всех программных модулей, реализующих рассмотренный пример для лабораторной работы № 2, приведен в приложении 2.
Выводы по проделанной работе
В результате лабораторной работы № 2 построен лексический анализатор на основе конечного автомата. Построенный лексический анализатор позволяет выделять в тексте исходной программы лексемы следующих типов:
• ключевые слова (if, then, else, or, xor и and);
• идентификаторы (при этом в именах идентификаторов различаются строчные и прописные английские буквы);
• знак операции присваивания;
• целые десятичные константы без знака;
• разделители (круглые скобки и точка с запятой).
Лексический анализатор игнорирует в тексте входной программы пробелы, знаки табуляции и переводы строки, а также комментарии, выделенные фигурными скобками.
В случае обнаружения неверной лексемы (например числа, содержащего букву), незакрытого комментария или незавершенной лексемы (такой лексемой может быть только символ «:») лексический анализатор выдает сообщение об ошибке и прекращает дальнейший анализ. При наличии нескольких неверных лексем анализатор обнаруживает только первую из них.
Результатом выполнения лексического анализа является структура данных, которая представляет таблицу лексем. Построенный лексический анализатор предназначен для подготовки данных, необходимых для выполнения следующих лабораторных работ, связанных с синтаксическим анализом и генерацией кода.
Лабораторная работа № 3
Построение простейшего дерева вывода
Цель работы
Цель работы: изучение основных понятий теории грамматик простого и операторного предшествования, ознакомление с алгоритмами синтаксического анализа (разбора) для некоторых классов КС-грамматик, получение практических навыков создания простейшего синтаксического анализатора для заданной грамматики операторного предшествования.
Краткие теоретические сведения
Назначение синтаксического анализатора
По иерархии грамматик Хомского выделяют четыре основные группы языков (и описывающих их грамматик) [1, 3, 4, 7]. При этом наибольший интерес представляют регулярные и контекстно-свободные (КС) грамматики и языки. Они используются при описании синтаксиса языков программирования. С помощью регулярных грамматик можно описать лексемы языка – идентификаторы, константы, служебные слова и прочие. На основе КС-грамматик строятся более крупные синтаксические конструкции: описания типов и переменных, арифметические и логические выражения, управляющие операторы и, наконец, полностью вся программа на входном языке.
Входные цепочки регулярных языков распознаются с помощью конечных автоматов (КА). Они лежат в основе сканеров, выполняющих лексический анализ и выделение слов в тексте программы на входном языке. Результатом работы сканера является преобразование исходной программы в список или таблицу лексем. Дальнейшую ее обработку выполняет другая часть компилятора – синтаксический анализатор. Его работа основана на использовании правил КС-грамматики, описывающих конструкции исходного языка.
Синтаксический анализатор (синтаксический разборщик) – это часть компилятора, которая отвечает за выявление и проверку синтаксических конструкций входного языка. В задачу синтаксического анализатора входит:
• найти и выделить синтаксические конструкции в тексте исходной программы;
• установить тип и проверить правильность каждой синтаксической конструкции;
• представить синтаксические конструкции в виде, удобном для дальнейшей генерации текста результирующей программы.
Синтаксический анализатор – это основная часть компилятора на этапе анализа. Без выполнения синтаксического разбора работа компилятора бессмысленна, в то время как лексический разбор, в принципе, не является обязательной фазой компиляции. Все задачи по проверке синтаксиса входного языка могут быть решены на этапе синтаксического разбора. Лексический анализатор только позволяет избавить сложный по структуре синтаксический анализатор от решения примитивных задач по выявлению и запоминанию лексем исходной программы.
Читать дальшеИнтервал:
Закладка: