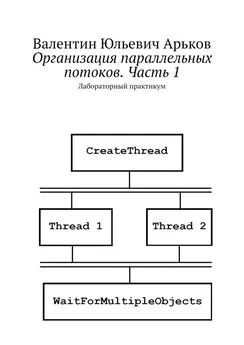
Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум

- Название:Системное программное обеспечение. Лабораторный практикум
- Автор:
- Жанр:
- Издательство:Array Издательство «Питер»
- Год:2005
- Город:Санкт-Петербург
- ISBN:978-5-469-00391-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум краткое содержание
Книга ориентирована на студентов, обучающихся в технических вузах по специальностям, связанным с вычислительной техникой. Но она будет также полезна всем, чья деятельность так или иначе касается разработки программного обеспечения.
Системное программное обеспечение. Лабораторный практикум - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Выходом лексического анализатора является таблица лексем. Эта таблица образует вход синтаксического анализатора, который исследует только один компонент каждой лексемы – ее тип. Остальная информация о лексемах используется на более поздних фазах компиляции при семантическом анализе, подготовке к генерации и генерации кода результирующей программы.
Синтаксический анализатор воспринимает выход лексического анализатора и разбирает его в соответствии с грамматикой входного языка. Однако в грамматике входного языка программирования обычно не уточняется, какие конструкции следует считать лексемами. Примерами конструкций, которые обычно распознаются во время лексического анализа, служат ключевые слова, константы и идентификаторы. Но эти же конструкции могут распознаваться и синтаксическим анализатором. На практике не существует жесткого правила, определяющего, какие конструкции должны распознаваться на лексическом уровне, а какие надо оставлять синтаксическому анализатору. Обычно это определяет разработчик компилятора исходя из технологических аспектов программирования, а также синтаксиса и семантики входного языка. Принципы взаимодействия лексического и синтаксического анализаторов были рассмотрены в лабораторной работе № 2.
В основе синтаксического анализатора лежит распознаватель текста исходной программы, построенный на основе грамматики входного языка. Как правило, синтаксические конструкции языков программирования могут быть описаны с помощью КС-грамматик; реже встречаются языки, которые могут быть описаны с помощью регулярных грамматик.
Главную роль в том, как функционирует синтаксический анализатор и какой алгоритм лежит в его основе, играют принципы построения распознавателей для КС-языков. Без применения этих принципов невозможно выполнить эффективный синтаксический разбор предложений входного языка.
Проблема распознавания цепочек КС-языков
Взаимодействие лексического и синтаксического анализаторов рассматривалось в предыдущей лабораторной работе, здесь же будут рассмотрены алгоритмы, лежащие в основе синтаксического анализа. Перед синтаксическим анализатором стоят две основные задачи: проверить правильность конструкций программы, которая представляется в виде уже выделенных слов входного языка, и преобразовать ее в вид, удобный для дальнейшей семантической (смысловой) обработки и генерации кода. Одним из способов такого представления является дерево синтаксического разбора.
Основой для построения распознавателей КС-языков являются автоматы с магазинной памятью – МП-автоматы – односторонние недетерминированные распознаватели с линейно-ограниченной магазинной памятью (полная классификация распознавателей приведена в [1, 4, 3, 7]). Поэтому важно рассмотреть, как функционирует МП-автомат и как для КС-языков решается задача разбора – построение распознавателя языка на основе заданной грамматики. Далее рассмотрены технические аспекты, связанные с реализацией синтаксических анализаторов.
МП-автомат в отличие от обычного КА имеет стек (магазин), в который можно помещать специальные «магазинные» символы (обычно это терминальные и нетерминальные символы грамматики языка). Переход МП-автомата из одного состояния в другое зависит не только от входного символа, но и от одного или нескольких верхних символов стека. Таким образом, конфигурация автомата определяется тремя параметрами: состоянием автомата, текущим символом входной цепочки (положением указателя в цепочке) и содержимым стека.
При выполнении перехода МП-автомата из одной конфигурации в другую из стека удаляются верхние символы, соответствующие условию перехода, и добавляется цепочка, соответствующая правилу перехода. Первый символ цепочки становится верхушкой стека. Допускаются переходы, при которых входной символ игнорируется (и тем самым он будет входным символом при следующем переходе). Эти переходы называются ^-переходами. Если при окончании цепочки автомат находится в одном из заданных конечных состояний, а стек пуст, цепочка считается принятой (после окончания цепочки могут быть сделаны Х-переходы). Иначе цепочка символов не принимается.
МП-автомат называется недетерминированным, если при одной и той же его конфигурации возможен более чем один переход. В противном случае (если из любой конфигурации МП-автомата по любому входному символу возможно не более одного перехода в следующую конфигурацию) МП-автомат считается детерминированным (ДМП-автоматом). ДМП-автоматы задают класс детерминированных КС-языков, для которых существуют однозначные КС-грамматики. Именно этот класс языков лежит в основе синтаксических конструкций всех языков программирования, так как любая синтаксическая конструкция языка программирования должна допускать только однозначную трактовку [1–4, 7].
По произвольной КС-грамматике
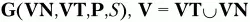
всегда можно построить недетерминированный МП-автомат, который допускает цепочки языка, заданного этой грамматикой [1–3, 7]. А на основе этого МП-автомата можно создать распознаватель для заданного языка.
Однако при алгоритмической реализации функционирования такого распознавателя могут возникнуть проблемы. Дело в том, что построенный МП-автомат будет, как правило, недетерминированным, а для МП-автоматов, в отличие от обычных КА, не существует алгоритма, который позволял бы преобразовать произвольный МП-автомат в ДМП-автомат. Поэтому программирование функционирования МП-автомата – нетривиальная задача. Если моделировать его функционирование по шагам с перебором всех возможных состояний, то может оказаться, что построенный для тривиального МП-автомата алгоритм никогда не завершится на конечной входной цепочке символов при определенных условиях. Примеры таких МП-автоматов можно найти в [1, 3, 7].
Поэтому для построения распознавателя для языка, заданного КС-грамматикой, рекомендуется воспользоваться соответствующим математическим аппаратом и одним из существующих алгоритмов.
Виды распознавателей для КС-языков
Существуют несложные преобразования КС-грамматик, выполнение которых гарантирует, что построенный на основе преобразованной грамматики МП-автомат можно будет промоделировать за конечное время на основе конечных вычислительных ресурсов. Описание сути и алгоритмов этих преобразований можно найти в [1, 3, 7].
Эти преобразования позволяют строить два основных типа простейших распознавателей:
• распознаватель с подбором альтернатив;
Читать дальшеИнтервал:
Закладка: