Симон Робинсон - C# для профессионалов. Том II

- Название:C# для профессионалов. Том II
- Автор:
- Жанр:
- Издательство:Лори
- Год:2003
- Город:Москва
- ISBN:5-85582-187-0
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Симон Робинсон - C# для профессионалов. Том II краткое содержание
Платформа .NET предлагает новую среду, в которой можно разрабатывать практически любое приложение, действующее под управлением Windows, а язык C# — новый язык программирования, созданный специально для работы с .NET.
В этой книге представлены все основные концепции языка C# и платформы .NET. Полностью описывается синтаксис C#, приводятся примеры построения различных типов приложений с использованием C# — создание приложений и служб Windows, приложений и служб WWW при помощи ASP.NET, а также элементов управления Windows и WWW Рассматриваются общие библиотеки классов .NET, в частности, доступ к данным с помощью ADO.NET и доступ к службе Active Directory с применением классов DirectoryServices.
Для кого предназначена эта книгаЭта книга предназначена для опытных разработчиков, возможно, имеющих опыт программирования на VB, C++ или Java, но не использовавших ранее в своей работе язык C# и платформу .NET. Программистам, применяющим современные технологии, книга даст полное представление о том, как писать программы на C# для платформы .NET.
Основные темы книги• Все особенности языка C#
• C# и объектно-ориентированное программирование
• Приложения и службы Windows
• Создание web-страниц и web-служб с помощью ASP NET
• Сборки .NET
• Доступ к данным при помощи ADO NET
• Создание распределённых приложений с помощью NET Remoting
• Интеграция с COM, COM+ и службой Active Directory
C# для профессионалов. Том II - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
using MSXML2;
на
using System.Xml;
Мы должны это сделать, поскольку используем теперь не MSXML 3.0, а пространство имен System.Xml. Нужно также удалить метод listBox1_SelectedIndexChanged ,так как он включает в себя некоторые неподдерживаемые методы и строку:
private DOMDocument30 doc;
protected void button1_Click(object sender, System.EventArgs e) {
// Измените этот путь доступа, чтобы найти books.xml
string fileName = "..\\..\\..\\books.xml";
// Создать новый объект TextReader
XmlTextReader tr = new XmlTextReader(fileName);
// Прочитать узел за раз
while(tr.Read()) {
if (tr.NodeType == XmlNodeType.Text) listBox1.Items.Add(tr.Value);
}
}
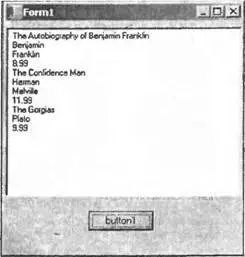
Это XmlTextReaderв простейшей форме. Сначала создается строковый объект fileNameс именем файла XML. Затем создается новый объект XmlTextReader, передавая в качестве параметра строку fileName.XmlTextReaderв настоящее время имеет 13 различных перегружаемых конструкторов, которые получают различные комбинации строк (имен файлов и URL), потоков и таблиц имен. После инициализации объекта XmlTextReaderни один узел не выбран. Это единственный момент, когда узел не является текущим. Когда мы начинаем цикл tr.Read, первая операция чтения Readпереместит нас в первый узел документа. Обычно это бывает узел Declaration XML. В этом примере при переходе к каждому узлу tr.NodeTypeсравнивается с перечислением XmlNodeType, и когда встречается текстовый узел, значение текста добавляется в listbox. Вот экран после того, как было загружено окно списка:
Существует несколько способов перемещения по документу. Как мы только что видели, Readперемещает нас к следующему узлу. Затем можно проверить, имеет ли узел значение ( HasValue) или, как мы скоро увидим, имеет ли узел атрибуты ( HasAttributes). Существует метод ReadStartElement, который проверяет, является ли текущий узел начальным элементом, и затем перемешает текущую позицию к следующему узлу. Если текущая позиция не является начальным элементом, то порождается исключение XmlException. Этот метод совпадает с вызовом метода IsStartElement, за которым следует метод Read.
Методы ReadStringи ReadChartsсчитывают текстовые данные из элемента. ReadStringвозвращает строковый объект, содержащий данные, в то время как ReadChartsсчитывает данные в заданный массив символов.
Метод ReadElementStringаналогичен методу ReadString, за исключением того, что при желании можно передать в него имена элемента. Если следующий узел содержимого не является начальным тегом или, если параметр Nameне совпадает с именем ( Name) текущего узла, то порождается исключение. Вот пример того, как это может использоваться (код можно найти в папке XmlReaderSample2):
protected void button1_Click(object sender, System.EventArgs e) {
// Использовать файловый поток для получения данных
FileStream fs = new FileStream("..\\..\\..\\books.xml", FileMode.Open);
XmlTextReader tr = new XmlTextReader(fs);
while(!tr.EOF) {
// если встретился тип элемента, проверить и загрузить его в окно списка
if (tr.MoveToContent()==XmlNodeType.Element && tr.Name=="title") {
listBox1.Items.Add(tr.ReadElementString());
} else
//иначе двигаться дальше
tr.Read();
}
}
В цикле whileиспользуется метод MoveToContentдля поиска каждого узла типа XmlNodeType.Elementс именем title. Если это условие не выполняется, то предложение elseвызывает метод Readдля перехода к следующему узлу. Если будет найден узел, соответствующий критерию, то результат работы метода ReadElementStringдобавляется в listbox. Таким образом мы получим заглавия книг в listbox. Отметим, что после успешного применения ReadElementStringметод Readне вызывается. Это связано с тем, что метод ReadElementStringобрабатывает весь Elementи перемещается к следующему узлу.
Если удалить && tr.Name=="title"из предложения if, то придется отслеживать исключение XmlException, когда оно будет порождаться. При просмотре файла данных можно заметить, что первым элементом, который найдет метод MoveToContent, является элемент . Как элемент он будет проходить проверку в операторе if. Но так как он не содержит простой текстовый тип, он вынуждает метод ReadElementStringпорождать исключение XmlException. Одним из способов обхода этой проблемы является размещение вызова ReadElementStringв своей собственной функции. Назовем ее LoadList. XmlTextReaderпередается в нее в качестве параметра. Теперь, если вызов ReadElementStringотказывает внутри этой функции, мы можем иметь дело с ошибкой и вернуться назад в вызывающую функцию. Вот как выглядит пример с этими изменениями (код можно найти в папке XmlReaderSample3):
protected void button1_Click(object sender, System.EventArgs e) {
// использовать файловый поток для получения данных
FileStream fs = new FileStream("..\\..\\..\\books.xml", FileMode.Open);
XmlTextReader tr = new XmlTextReader(fs);
while(!tr.EOF) {
// если встретился тип элемента, проверить и загрузить его в окно списка
if (tr.MoveToContent() == XmlNodeType.Element) {
LoadList(tr);
} else
// иначе двигаться дальше
tr.Read();
}
}
private void LoadList(XmlReader reader) {
try {
listBox1.Items.Add(reader.ReadElementString());
}
//если инициировано исключение XmlException, игнорировать его.
catch(XmlException er){}
}
Вот что должно появиться, когда код будет выполнен:
Это тот же результат, который был раньше. Мы видим, что существует более одного способа достичь одной и той же цели. При этом становится очевидной гибкость пространства имен System.Xml.
По мере чтения узлов можно заметить отсутствие каких-либо атрибутов. Это связано с тем, что атрибуты не считаются частью структуры документа. При нахождении в узле элемента мы можем проверить наличие атрибутов и получить значения атрибутов. Метод HasAttributesвозвращает true, если существуют какие-либо атрибуты, иначе возвращается false. Свойство AttributeCountсообщит, сколько имеется атрибутов. Метод GetAttributeполучает атрибут по имени или по индексу. Если желательно просмотреть все атрибуты по очереди, можно использовать методы MoveToFirstAttribute(перейти к первому атрибуту) и MoveToNextAttribute(перейти к следующему атрибуту). Вот пример просмотра атрибутов из XmlReaderSample4:
protected void button1_Click(object sender, System.EventArgs e) {
// задаем путь доступа в соответствии со структурой путей доступа
// к данным
Интервал:
Закладка:



