IvanStorogev? KpNemo - Как почистить сканы книг и сделать книгу

- Название:Как почистить сканы книг и сделать книгу
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
IvanStorogev? KpNemo - Как почистить сканы книг и сделать книгу краткое содержание
В статье описана очистка сканов книг непосредственно после сканирования, перед дальнейшей обработкой. Речь будет идти только о черно-белых книгах (текст и штриховые рисунки). Обработку книг с цветными картинками нужно разбирать отдельно. Способы обработки сканов ScanKromsator.
Как почистить сканы книг и сделать книгу - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Главное окно программы организовано в виде вкладок:
1) Вкладка: Input Image
Про то, как загрузить файл в программу, я рассказывать не буду, замечу лишь, что NI+ не желает открывать 8-битный TIFF, если он сохранен, например из PhotoShop’а как индексированный 8-битный с палитрой, но нормально открывает, если TIFF сохранить как grayscale.
2) Вкладка: Device Noise Profile
На этом этапе мы должны выбрать участок скана, где нет букв и рисунков, но есть характерные шумы. Обратите внимание: темные полосы около корешка или на краях тоже не должны попасть в наш выбор. На выделенный участок показывает стрелка на Рис. 1:
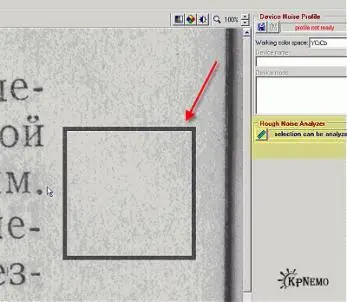
После того, как мы выделим подходящий участок, надо щелкнуть по кнопке "Rough NoiseAnalyzer" на левой панели, на Рис.1 подсвечена желтым. Некоторое время наблюдаем за синей полоской… и на левой панели, под упомянутой кнопкой, появятся дополнительные настройки (Рис. 2).
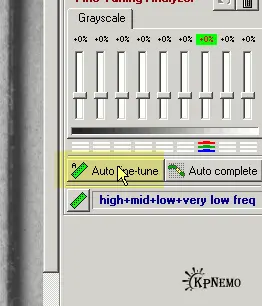
Проще всего нажать на кнопочку "Auto fine-tune" (подсвечена желтым), и перейти к вкладке 3:
3) Вкладка: Noise Filter Settings
Здесь мы настроим фильтр так, чтобы сделать максимально четкими буквы и убить шумы. Перед настройкой фильтра нужно выделить участок подходящий участок с полезнымизображением и увеличить его на весь экран. При выборе участка нужно руководствоваться следующими соображениями:
1) Брать нужно, по возможности, максимально зашумленный участок;
2) Одновременно этот участок должен с наиболее мелким деталями полезного изображения, например с мелким шрифтом.
Поскольку мы обрабатываем не фотографию любимой кошки, а текст, то естественность изображения нас не волнует. Главное, чтобы буквы были почетче, а шума поменьше. Поэтому смело двигаем движки на левой половине панели и смотрим, что получается. Обращайте внимание на мелкие детали букв: хвостики, например сравнивайте "C" и "G"; внутренние участки букв, например в верхней части строчной "е".
Описывать действие каждого движка я не буду, проще пробовать и смотреть.
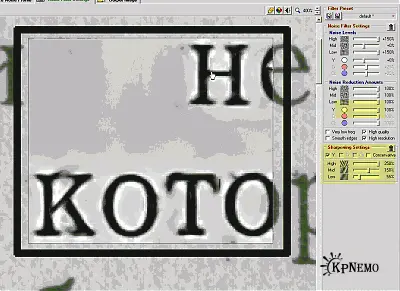
На картинке (Рис. 3) изображен результат обработки, а положение движков и чекбоксов можно взять за точку отсчета при собственных экспериментах. В основном играйте движками в "Noise reduction Amounts", особенно движок "Y"; "Sharpening Settings". Эти участки левой панели на рисунке подсвечены желтым. Когда результат вам понравится, подвигайте прямоугольник Preview по всему изображению, чтоб прикинуть, как оно будет выглядеть в разных местах. Если все хорошо, сохраните полученный профиль фильтрации, он будет использован для пакетной обработки остальных страниц.
4) Вкладка: Output Image
Здесь вы можете нажать на Apply и посмотреть, что получилось. А если вы уверены, что настроили NI+ хорошо, то сразу переходите к пакетной обработке остальных страниц. Просто нажмите Esc, и вы попадете в окно пакетного обработчика.
5) Окно пакетного обработчика
File -› Bath, добавляете нужные страницы (не забудьте в "Filter Presets" пометить "Use specified preset" и выбрать сохраненный прежде, при настройке по образцовой странице пресет. Наконец можно запустить процесс обработки. Он долгий, поэтому запустите его на ночь, или, наоборот, с утра, перед уходом на работу.
Дальше нужно продолжить чистку в Фотошопе, но об этом в следующей части, которая будет опубликована, если эта вызовет интерес и желание продолжения у юзеров.
Часть 2.
В первой части статьи мы остановились на этом:

Пойдём дальше. Вторая часть статьи.
Напомню, речь идет толькоо черно-белых книгах (текст и штриховые рисунки). Не о цветных.
В отзывах к первой части статьи прозвучал много хороших слов и благодарностей. Большое спасибо всем, кто нашел время откликнутся, написать пару строк в комменты, тем более с добрыми словами в мой адрес. Доброе слово, как говорится, и кошке приятно. Всем удачи:-)
Надеюсь, однако, что будет больше замечаний непосредственно по теме. Делитесь своими наработками, рецептами. Некоторые блогеры упомянули о других программах/способах обработки сканов – напишите о них, это будет интересно всем. Профессионалы, расскажите о более серьезных программах, а можно и выложить.
Критикуйте, дополняйте эту статью (это касается всех частей)- ведь это выгодно всем.
Да, я знаю, что надо не грузить общими рассуждениями, а говорить конкретно. Но любое дело лучше делать осмысленно. Осмысление же требует хотя бы самого общего представления о сути предмета. Поэтому, пожалуйста, прочтите последующие несколько абзацев не спеша, вдумчиво. Может быть они будут Вам полезны не только в деле очистки сканов книг. Возможно, Вам покажутся общеизвестными высказанные там мысли, но, как показывает опыт общения, это не так.
Если влом читать неконкретные вещи, то можно сразу перейти к Photoshop: Curves, всё, что там написано, можно понять и не читая раздел Философское отступление
Итак, пару слов о шуме (помехе), (полезном) сигнале и фильтрации, в самом общем плане, безотносительно к обработке изображения.
Сигнал.
Имеется ввиду полезный сигнал. Сигнал – это то, что нам нужно…
Это исчерпывающее определение. Например, сигналом может быть часть картинки – изображение текста в примере, который мы разбираем. Или голос исполнителя в музыкальном клипе. Или правда в речах политика, если она там есть. И всё, что угодно.
Шум.
А шум, помеха, это то, что нам ненужно . Например фон текста на картинке (фактура бумаги, пятна, следы грязи на стекле сканера). Или звучание музыкальных инструментов в муз. клипе, если мы хотим выделить голос исполнителя. Или вся речь политика, если правды там нет.
Фильтрация, это процесс разделения сигнала и шума. Это может быть некое электронное или механическое устройство, компьтерная программа. Разум слушателя, если речь идет о словах политика…
Для того, чтобы фильтрация была осуществима, сигнал и шум хоть в чем-то, но должны отличаться. Т.е. мы должны найти параметры, свойства, по которым отличаются шум/сигнал и увеличить это различие.
Вернемся к сканам книги. На краях и переплета после сканирования часто бывают черные полосы. Это тоже шум. От полезного сигнала, изображения текста, он отличается расположением в двумерном пространстве изображения страницы, поэтому отделить его легко руками и относительно легко автоматически. Стоит, однако, неплотно прижать толстую книгу при сканировании и черная полоса будет пересекаться с текстом. И всё, выделить текст в этом месте методами обработки изображения станет невозможно. Но если речь идет всего о 1-2 буквах в начале (конце) строки, мозг, почти на 100% восстановит недостающие буквы. Вдь ткст очн избтчн, при удални глснх всё ещ мжно пнть о чм рчь. Однако фильтрация и восстановление будет идти не изображения, а текста как последовательности букв и слов, с учетом их смысла, семантики.
Читать дальшеИнтервал:
Закладка:



