Алексей Валиков - Технология XSLT

- Название:Технология XSLT
- Автор:
- Жанр:
- Издательство:БХВ-Петербург
- Год:2002
- Город:Санкт-Петербург
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Алексей Валиков - Технология XSLT краткое содержание
Книга посвящена разработке приложений для преобразования XML-документов с использованием XSLT — расширяемого языка стилей для преобразований. Обсуждается применение языков XSLT и XPath в решении практических задач: выводу документов в формате HTML, использованию различных кодировок для интернационализации и, в частности, русификации приложений, вопросам эффективности существующих подходов для решения проблем преобразования. Для иллюстрации материала используется большое количество примеров.
Для начинающих и профессиональных программистов
Технология XSLT - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Отсутствие "побочных" эффектов
Одним из краеугольных принципов XSLT, с которым, увы, нелегко смириться разработчику, работавшему только с процедурными языками, — это отсутствие "побочных" эффектов. Под побочными эффектами в данном случае понимаются изменения в окружении преобразования, которые отражаются на дальнейшем его выполнении.
Концепция отсутствия побочных эффектов берет начало в функциональном программировании, а оно, в свою очередь, в "чистых" математических функциях, не изменяющих своего окружения в процессе вычисления. Например, функция
f ( x , у ) > вернуть x + у ;
будет чистой функцией. Сколько бы раз мы ее не вызывали, ее результат все равно будет равен сумме аргументов. Кроме того, результат вычисления f ( f ( x 1, y 1), f ( x 2, y 2)) будет равен x 1+ y 1+ x 2+ y 2, в каком бы порядке мы не вычисляли эти функции:
f ( f ( x 1, y 1), f ( x 2, y 2)) = f ( x 1+ y 1, f ( x 2, y 2)) = x 1+ y 1+ f ( x 2, y 2) = x 1+ y 1+ x 2+ y 2
f ( f ( x 1, y 1), f ( x 2, y 2)) = f ( f ( x 1, y 1), x 2+ y 2) = f ( x 1, y 1) + x 2+ y 2= x 1+ y 1+ x 2+ y 2
f ( f ( x 1, y 1), f ( x 2, y 2)) = f ( x 1, y 1) + f ( x 2, y 2) = x 1+ y 1+ f ( x 2, y 2) = x 1+ y 1+ x 2+ y 2
и так далее.
Представим теперь похожую функцию, обладающую побочным эффектом:
f ( x , у ) → z присвоить x ; увеличить z на у ; вернуть z ;
В данном случае побочный эффект состоит в изменении значения переменной z . В этом случае результат вычисления выражения f ( z , f ( x , у )) строго зависит от того, в каком порядке будут вычисляться функции — в одних случаях результатом будет x + у + z , в других 2∙ x + 2∙ у . Для того чтобы результат вычислений с побочными эффектами был детерминирован, требуется строгая определенность в порядке действий. В XSLT же эта строгая определенность отсутствует, преобразование — это набор правил, а не последовательность действий.
Таковы теоретические посылки отсутствия побочных эффектов. Главным практическим ограничением является то, что преобразования не могут во время выполнения изменять переменные — после того, как переменной присвоено некоторое начальное значение, измениться оно больше не может.
Сильнее всего это ограничение сказывается на стиле XSLT-программирования. Он становится ближе к функциональному стилю таких языков, как Lisp и Prolog. Научиться соответствовать этому стилю просто, хотя поначалу он и будет казаться неудобным.
Расширения
Слово extensible (англ. расширяемый) в расшифровке аббревиатуры XSLT исторически происходит из названия языка XSL, но оно вполне применимо и к самому XSLT: спецификация этого языка позволяет разрабатывать собственные функции и элементы и использовать их в преобразованиях.
Применительно к преобразованиям структуры, XSLT является чрезвычайно мощным языком, но в то же время вычислительная его часть страдает. В языке XPath, на который переложена задача вычислений в XSLT, есть основные арифметические и логические операторы, небольшая базовая библиотека функций для работы с различными типами данных — но не более. XPath мало подходит для действительно сложных вычислительных задач. Что касается самого XSLT, набор элементов этого языка можно назвать вполне достаточным для большинства задач. Но и тут встречаются приложения (и разработчики), которые требуют большего.
Следуя спецификации, большинство реализаций XSLT предоставляет интерфейсы для разработки собственных функций, немного реже — элементов. Расширения пишутся на обычных языках программирования, таких как Java или С, но используются в XSLT так же, как использовались бы обычные функции и элементы.
Технология расширений делает XSLT поистине универсальным языком, ведь получается, что в нем можно использовать любые вычисления, которые только могут быть описаны в классических языках программирования.
К сожалению, вследствие различий в интерфейсах расширений, их использования приводит к потере переносимости между платформами и процессорами. Если преобразования, созданные в соответствии со стандартом языка, будут, как правило, без проблем выполняться различными процессорами, использование расширений в большинстве случаев ограничивает переносимость преобразования.
Преобразования снаружи
В общем случае в преобразовании участвуют три документа:
□ входящий документ , который подвергается преобразованию;
□ документ, который описывает само преобразование ;
□ выходящий документ , который является результатом преобразования.
Само по себе преобразование это всего лишь XML-документ, не более чем описание правил, в соответствии с которыми входящий документ должен трансформироваться в исходящий. Процесс преобразования входящего документа в соответствии с описанными правилами называется применением преобразования к входящему документу или просто выполнением данного преобразования.
Выполнением преобразований над документами занимаются специальные программы, которые называются XSLT-процессорами. В первом приближении схема преобразования приведена на рис. 2.1.
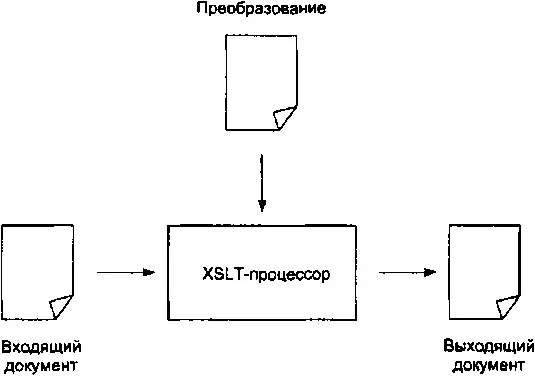
Рис. 2.1. Схема XSLT-преобразования
Процессор получает входящий документ и преобразование, и, применяя правила преобразования, генерирует выходящий документ — такова в общем случае внешняя картина. На самом деле процессор оперирует не самими документами, а древовидными моделями их структур (рис. 2.2.) — именно структурными преобразованиями занимается XSLT, оставляя за кадром синтаксис, который эти структуры выражает.
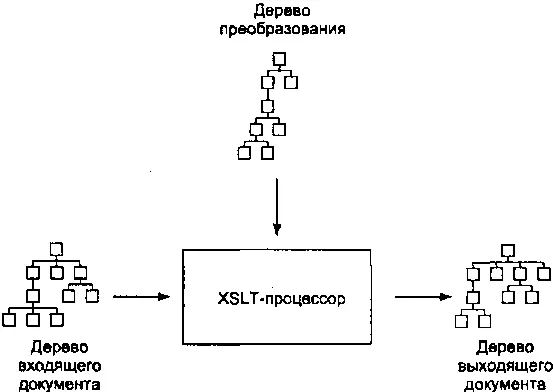
Рис. 2.2.Древовидные структуры в XSLT
Несмотря на то, что для XSLT как для языка совершенно неважно, в каком виде находятся документы изначально (главное — чтобы была структура, которую можно преобразовать), абсолютное большинство процессоров может работать с документами, которые физически записаны в файлах. В этом случае процесс обработки делится на три стадии.
□ XSLT-процессор разбирает входящий документ и документ преобразования, создавая для них древовидные структуры данных. Этот этап называется этапом парсинга документа (от англ. parse — разбирать).
Читать дальшеИнтервал:
Закладка:

