Алексей Валиков - Технология XSLT

- Название:Технология XSLT
- Автор:
- Жанр:
- Издательство:БХВ-Петербург
- Год:2002
- Город:Санкт-Петербург
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Алексей Валиков - Технология XSLT краткое содержание
Книга посвящена разработке приложений для преобразования XML-документов с использованием XSLT — расширяемого языка стилей для преобразований. Обсуждается применение языков XSLT и XPath в решении практических задач: выводу документов в формате HTML, использованию различных кодировок для интернационализации и, в частности, русификации приложений, вопросам эффективности существующих подходов для решения проблем преобразования. Для иллюстрации материала используется большое количество примеров.
Для начинающих и профессиональных программистов
Технология XSLT - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Что касается XSLT и XPath, спецификации обоих этих языков стали техническими рекомендациями 16 ноября 1999 года. Сам же язык XSL, который теперь стали называть XSL-FO (аббревиатура FO означает formatting objects — форматирующие объекты), получил статус рекомендации не так быстро. Спустя год, в ноябре 2000, спецификация XSL получила статус кандидата в рекомендации, а еще через 9 месяцев с минимальными исправлениями — статус предлагаемой рекомендации. По всей видимости, к тому моменту, когда эта книга увидит свет, спецификация XSL уже будет официальной рекомендацией W3C.
Одного года было достаточно, чтобы XSLT стал широко использоваться во многих XSLT-задачах. Повышенное внимание разработчиков позволило выявить некоторые досадные огрехи, которые были допущены в первой версии XSLT, и потому в конце 2000 года была начата работа над версией 1.1. В новой версии рабочая группа XSL постаралась исправить большинство ошибок, допущенных в версии 1.0 и добавить некоторые возможности, которых не хватало в первой версии. Однако через некоторое время стало понятно, что разрабатываемый язык довольно сильно отличается от первой версии. К тому же, с учетом таких разработок, как XML Schema и XQuery возникла необходимость изменить модель данных и выражений XPath. В итоге, работу над версией 1.1 решено было прекратить и переключиться на создание вторых версий языков XSLT и XPath.
Вместо того чтобы разбирать в этой книге особенности версии 1.1, которая никогда не станет рекомендацией, в последней главе мы опишем то, что, согласно требованиям ко вторым версиям языков XSLT и XPath, ожидается в их спецификациях, и что, согласно XSLT 1.1 там точно будет. Работа над XSLT 2.0 и XPath 2.0 в самом разгаре: к сентябрю 2001 года были уже готовы три внутренних рабочих версии. К сожалению, открывать секреты рабочей группы XSL мы не в праве, хотя можно смело сказать, что процесс работы внушает оптимизм.
Глава 3
Идея и модель языка XSLT
Модель XML-документа
Описывая основы построения XML-документов, мы отмечали, что иерархическая организация информации в XML лучше всего описывается древовидными структурами. Дерево — это четкая, мощная и простая модель данных и именно она была на концептуальном уровне применена в языках XSLT и XPath. Как пишет Кнут [Кнут 2000], " деревья — это наиболее важные нелинейные структуры, которые встречаются при работе с компьютерными алгоритмами ". Добавим, что это без сомнения самая важная структура из тех, которыми оперируют языки XSLT и XPath.
В этих языках документ моделируется как дерево, состоящее из узлов. Узлы дерева соответствуют структурным единицам XML — элементам, атрибутам, тексту и так далее, а дуги, ветки — отношениям между этими единицами. Простейшим примером является принадлежность одних элементов другим. Документ вида
<���а>
<���с/>
</а>
может быть представлен деревом (рис. 3.1).
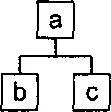
Рис. 3.1. Представление документа в виде дерева
Аналогия совершенно очевидна — элемент асодержит элементы bи с, в то время как в дереве вершина аявляется родительским узлом для вершин bи с.
Естественно, XML-документы состоят далеко не из одних только элементов и потому для того, чтобы дерево достоверно отражало структуру и содержание документа, в нем выделяются узлы следующих семи типов:
□ корневой узел;
□ узлы элементов;
□ узлы атрибутов;
□ текстовые узлы;
□ узлы пространств имен;
□ узлы инструкций по обработке;
□ узлы комментариев.
Каждый узел дерева имеет соответствующее ему строковое значение, которое вычисляется в зависимости от типа. Строковым значением корневого узла и узла элемента является конкатенация (строковое сложение) строковых значений всех их потомков, для остальных типов узлов строковое значение является частью самого узла. Порядок вычисления строковых значений узлов будет более детально определен в описании каждого из типов.
Мы подробно разберем каждый из типов узлов чуть позже, а пока отметим, что дерево в XSLT и XPath является чисто концептуальной моделью. Процессоры не обязаны внутренне представлять документы именно в этой структуре, концептуальная модель означает лишь то, что все операции преобразования над документами будут определяться в терминах деревьев. Для программиста же это означает, что вовсе необязательно вникать в тонкости реализации преобразований в том или ином процессоре. Все равно они должны работать, так, как будто они работают непосредственно с деревьями.
Отметим также и то, что на практике некоторые из процессоров вообще не воссоздают внутреннюю модель документа, экономя, таким образом, ресурсы. Документы могут быть слишком объемными, и это препятствует загрузке их в память в виде древовидной структуры.
Некоторые из процессоров, напротив, используют DOM-модель документа для внутреннего представления обрабатываемой информации. Несмотря на большие требования к ресурсам памяти, такое решение также может иметь свои плюсы, например, универсальность и легкая интеграция в существующие XML-решения на базе DOM.
Но, так или иначе, с воссозданием древовидной структуры документа в памяти или нет, процессоры все равно оперируют одной и той же концептуальной моделью, которой мы сейчас и займемся.
Деревья
Прежде, чем мы приступим к рассмотрению типов узлов и отношений между ними, необходимо определиться с самой структурой дерева. Древовидная структура задает для своих элементов отношение ветвления, очень похожее на строение обычного дерева — есть корневой узел (ствол), от которого происходят другие узлы (ветки).
Формально [Кнут 2000] дерево определяется, как конечное множество T, состоящее из одного или нескольких элементов (узлов), обладающих следующими свойствами:
□ во множестве T выделяется единственный узел, называемый корневым узлом или корнем;
□ все остальные узлы разделены на m≥0 непересекающихся множеств T 1, …, T m, каждое из которых в свою очередь также является деревом.
Деревья T 1, …, T mназываются поддеревьями корня дерева T.
Это определение является рекурсивным, то есть в нем дерево определяется само через себя. Конечно, существуют нерекурсивные определения, но, пожалуй, следует согласиться с тем, что рекурсивное определение лучше всего отражает суть древовидной структуры: ветки дерева также являются деревьями.
В XSLT и XPath деревья являются упорядоченными, то есть для множеств T 1, …, T mзадается порядок следования, который называется порядком просмотра документа. В XSLT деревья упорядочиваются в порядке появления текстового представления их узлов в документах.
Читать дальшеИнтервал:
Закладка:

