Алексей Валиков - Технология XSLT

- Название:Технология XSLT
- Автор:
- Жанр:
- Издательство:БХВ-Петербург
- Год:2002
- Город:Санкт-Петербург
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Алексей Валиков - Технология XSLT краткое содержание
Книга посвящена разработке приложений для преобразования XML-документов с использованием XSLT — расширяемого языка стилей для преобразований. Обсуждается применение языков XSLT и XPath в решении практических задач: выводу документов в формате HTML, использованию различных кодировок для интернационализации и, в частности, русификации приложений, вопросам эффективности существующих подходов для решения проблем преобразования. Для иллюстрации материала используется большое количество примеров.
Для начинающих и профессиональных программистов
Технология XSLT - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
paragraph 1
paragraph 2
paragraph 3
paragraph 4
paragraph 5
paragraph 6
paragraph 7
paragraph 8
paragraph 9
paragraph 10
paragraph 11
paragraph 12
paragraph 13
paragraph 14
paragraph 15
paragraph 16
paragraph 17
paragraph 18
В качестве первого примера приведем два шаблона, обрабатывающих элементы chapter: один с использованием xsl:value-of, а второй с использованием xsl:number.
.
Результат обоих шаблонов имеет следующий вид:
1. First chapter
2. Second chapter
3. Third chapter
Использование xsl:numberдаже в этом простом случае сэкономило одну строчку в коде. Однако, если бы вместо нумерации арабскими цифрами ( 1, 2, 3и т.д.) нужно было применить нумерацию римскими цифрами ( I, II, IIIи т.д.), в преобразовании с xsl:numberмы бы изменили всего один символ (вместо format="1. "указали бы format="I. "), в то время как в преобразовании с xsl:value-ofпришлось бы писать сложную процедуру преобразования числа в римскую запись.
В том случае, если атрибут valueопущен, номера элементов вычисляются исходя из значений атрибутов level, countи from.
Атрибут levelимеет три варианта значений: single, multipleи any, значением по умолчанию является single. Процедура вычисления номеров существенным образом зависит от того, какой из этих вариантов используется — при методе singleсчитаются элементы на одном уровне, при методе multiple— на нескольких уровнях и при методе any— на любых уровнях дерева. Алгоритм вычисления списка номеров в каждом из случаев не слишком сложен, но понять его только по формальному описанию довольно непросто. Поэтому каждый из методов будет дополнительно проиллюстрирован примерами вычисления.
Атрибут countсодержит паттерн, которому должны удовлетворять нумеруемые узлы. Узлы, не соответствующие этому образцу, просто не будут приниматься в расчет. Значением этого атрибута по умолчанию является паттерн, выбирающий узлы с тем же типом и именем, что и у текущего узла (если, конечно, у него есть имя).
Атрибут fromсодержит паттерн, который определяет так называемую область нумерации, или область подсчета. При вычислении номера будут приниматься во внимание только те нумеруемые узлы, которые принадлежат этой области. По умолчанию областью подсчета является весь документ.
Метод singleиспользуется для того, чтобы вычислить номер узла, основываясь на его позиции среди узлов того же уровня. Нумерацию, в которой используется метод single, также называют одноуровневой нумерацией.
Областью нумерации этого метода будет множество всех потомков ближайшего предка текущего узла, удовлетворяющего паттерну, указанному в атрибуте from.
Вычисление номера производится в два шага.
□ На первом шаге находится узел уровня дерева. Узлом уровня будет узел, удовлетворяющий следующим условиям:
• он является первым (то есть ближайшим к текущему) узлом, принадлежащим оси ancestor-or-selfтекущего узла;
• он удовлетворяет паттерну count;
• он принадлежит области подсчета;
• если такого узла нет, список номеров будет пустым.
□ На втором шаге вычисляется номер узла уровня. Этот номер будет равен 1плюс количество узлов, принадлежащих оси навигации preceding-siblingи удовлетворяющих паттерну count.
Надо сказать, от атрибута fromв методе singleмало пользы. Единственный эффект, который можно от него получить, — это пустой список номеров в случае, если первый узел, принадлежащий оси ancestor-or-selfи удовлетворяющий паттерну count, не будет иметь предка, соответствующего паттерну атрибута from.
Разберем функционирование одноуровневой нумерации в следующем шаблоне:
Мы продемонстрируем вычисление номера одного из элементов paraна схематическом изображении дерева обрабатываемого документа (рис. 8.1). Узел обрабатываемого элемента мы выделим полужирной линией, узел элемента docпометим буквой d, узлы элементов chapter— буквой с, элементов sectionи para — буквами sи pсоответственно.
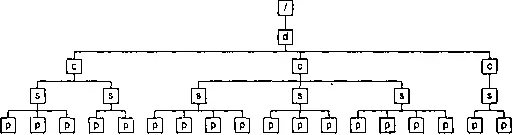
Рис. 8.1. Дерево обрабатываемого документа
В качестве первого примера приведем вычисление номера элементом
На первом шаге нам нужно найти узел уровня дерева. Этим узлом будет первый элемент section, являющийся предком текущего узла. На рис. 8.2 он обведен пунктиром.
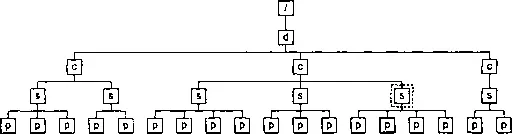
Рис. 8.2. Первый шаг вычисления номера
Номер этого элемента будет равен 1плюс количество предшествующих ему братских элементов section. Это множество выделено пунктиром на рис. 8.3.
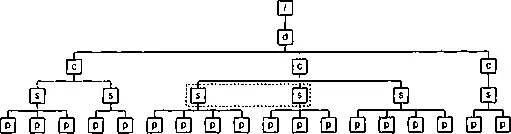
Рис. 8.3. Второй шаг вычисления номера
Выделенное множество содержит два узла. Таким образом, искомый номер будет равен 3.
Проведем такой же разбор для определения
В этом случае паттерну, указанному в элементе countудовлетворяет сам текущий узел, значит, он и будет являться узлом уровня, как это показано на рис. 8.4.
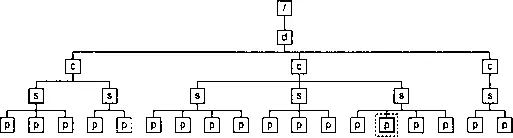
Рис. 8.4. Первый шаг вычисления номера
Выделим множество элементов para, являющихся братьями узла уровня и предшествующих ему (рис. 8.5).
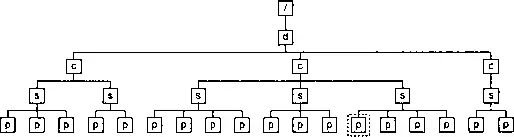
Рис. 8.5. Второй шаг вычисления номера
Выделенное множество содержит всего один узел, значит, искомый номер будет равен 2.
Таким образом, результатом обработки выделенного элемента paraбудет следующая строка:
3.2.paragraph 14
Метод multipleпохож на метод single, но при этом он немного сложнее, поскольку вычисляет номера узлов сразу на нескольких уровнях дерева. Нумерацию с применением метода multipleназывают также многоуровневой нумерацией.
Интервал:
Закладка:

