Джулиан Бакнелл - Фундаментальные алгоритмы и структуры данных в Delphi

- Название:Фундаментальные алгоритмы и структуры данных в Delphi
- Автор:
- Жанр:
- Издательство:ДиаСофтЮП
- Год:2003
- ISBN:ISBN 5-93772-087-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джулиан Бакнелл - Фундаментальные алгоритмы и структуры данных в Delphi краткое содержание
Книга "Фундаментальные алгоритмы и структуры данных в Delphi" представляет собой уникальное учебное и справочное пособие по наиболее распространенным алгоритмам манипулирования данными, которые зарекомендовали себя как надежные и проверенные многими поколениями программистов. По данным журнала "Delphi Informant" за 2002 год, эта книга была признана сообществом разработчиков прикладных приложений на Delphi как «самая лучшая книга по практическому применению всех версий Delphi».
В книге подробно рассматриваются базовые понятия алгоритмов и основополагающие структуры данных, алгоритмы сортировки, поиска, хеширования, синтаксического разбора, сжатия данных, а также многие другие темы, тесно связанные с прикладным программированием. Изобилие тщательно проверенных примеров кода существенно ускоряет не только освоение фундаментальных алгоритмов, но также и способствует более квалифицированному подходу к повседневному программированию.
Несмотря на то что книга рассчитана в первую очередь на профессиональных разработчиков приложений на Delphi, она окажет несомненную пользу и начинающим программистам, демонстрируя им приемы и трюки, которые столь популярны у истинных «профи». Все коды примеров, упомянутые в книге, доступны для выгрузки на Web-сайте издательства.
Фундаментальные алгоритмы и структуры данных в Delphi - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Для примера на рис. 4.1 приведены шаги, выполняемые при бинарном поиске буквы d в отсортированном массиве, содержащем буквы от a до k. На шаге (а) переменная L указывает на первый элемент (индекс 0), а R - на последний (индекс 10). Это означает, что значение переменной M будет составлять 5. Далее мы выполняем сравнение: значение элемента с индексом 5 равно f, а это больше искомого значения d.
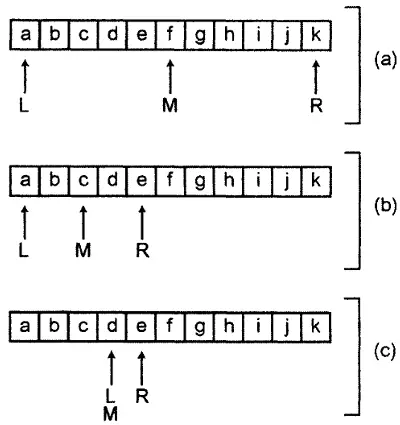
Рисунок 4.1. Бинарный поиск в массиве
Согласно алгоритму, мы устанавливаем значение R равным M-1 (таким образом, правая граница подмассива теперь находится слева от среднего элемента). Это означает, что значение R теперь равно 4. Новое значение среднего индекса будет равно 2, как показано на шаге (b). Выполняем сравнение: буква c (значение элемента с индексом 2) меньше, чем d.
Теперь, в соответствии с алгоритмом, необходимо установить индекс L за индексом M (т.е. M+1 или 3). Новое значение переменной M на шаге (с) равно 3. Выполняем сравнение: элемент с индексом 3 содержит букву d, а это и есть наше искомое значение. Поиск завершен.
Связные списки
Изучая код листинга 4.9, можно придти к выводу, что маловероятно, чтобы бинарный поиск использовался для связных списков, если, конечно, не воспользоваться индексным доступом к элементам списка, который, как уже упоминалось в главе 3, приводит к снижению быстродействия.
Но, тем не менее, реализация бинарного поиска для связных списков оказывается не такой уж и неразрешимой проблемой. Во-первых, нужно понимать, что в общем случае переход по ссылке выполняется гораздо быстрее, нежели вызов функции сравнения. Следовательно, можно сказать, что переход по ссылке - это "хорошо", а вызов функции сравнения - "плохо". Это означает, что следует стремиться к минимизации вызовов функции сравнения. (Поскольку для нас функция сравнения - "черный ящик", мы не можем сказать, сколько времени требуется на ее выполнение: много или мало, по крайней мере, по сравнению со временем, требуемым на переход по ссылке.) Во-вторых, необходимо иметь доступ к "внутренностям" связного списка.
Давайте рассмотрим принцип организации бинарного поиска на примере обобщенного связного списка, а затем рассмотрим код для классов TtdSingleLinkList и TtdDoubleLinkList. Для нашего обобщенного связного списка должно быть известно количество содержащихся в нем элементов, поскольку оно понадобится при реализации алгоритма бинарного поиска. Кроме того, будем считать, что связный список содержит фиктивный начальный узел.
А теперь сам алгоритм.
1. Сохранить фиктивный начальный узел в переменной BeforeCount.
2. Сохранить количество элементов в списке в переменной ListCount.
3. Если значение ListCount равно нулю, искомого элемента нет в списке, и поиск завершается. В противном случае вычислить половину значения ListCount, при необходимости округлить его и сохранить в переменной MidPoint.
4. Переместить BeforeCount по ссылкам Next на MidPoint узлов.
5.Сравнить значение элемента в узле, где остановилась переменная BeforeCount, с искомым значением. Если значения равны, искомый элемент найден и поиск завершается.
6. Если значение в узле меньше, чем искомое, записать узел в переменную BeforeCount, вычесть значение MidPoint из значения ListCount и перейти к шагу 3.
7. Если значение в узле больше, чем искомое, записать значение MidPoint-1 в переменную ListCount и перейти к шагу 3.
Давайте рассмотрим работу этого алгоритма на примере. Предположим, что имеется следующий связный список из пяти узлов, в котором необходимо найти узел B:
Начальный узел --> A --> B --> C --> D --> E --> nil
На первом шаге переменной BeforeList присваивается значение начального узла, а на втором переменной ListCount присваивается значение 5. Делим ListCount на два, округляем до целого, и присваиваем полученное значение (3) переменной MidPoint (шаг 3). По ссылкам от узла BeforeList отсчитываем три узла: A, B, C (шаг 4). Сравниваем текущий узел с искомым (шаг 5). Его значение больше искомого B, следовательно, устанавливаем значение переменной ListCount равным 2 (шаг 7). Еще раз выполняем цикл. Делим ListCount на два, округляем до целого и получаем 1 (шаг 3). По ссылкам от узла BeforeList отсчитываем один узел: А (шаг 4). Сравниваем значение текущего узла с искомым значением (шаг 5). Оно меньше значения B, следовательно, записываем в BeforeList значение узла B, а переменной ListCount присваиваем значение 1 (шаг 6) и снова выполняем цикл. В этот раз MidPoint получит значение 1 (т.е. значение ListCount, деленное на два и округленное до целого). Переходим по ссылке от узла BeforeList на один шаг и находим искомый узел.
Если вы считаете, что в процессе выполнения алгоритма искомый узел был пройден несколько раз, то вы совершенно правы. Но следует иметь в виду, что вызов функции сравнения может быть намного медленнее, чем переход по ссылкам (например, если элементы списка представляют собой строки длиной 1000 символов, то для определения соотношения между строками функции сравнения придется сравнить в среднем 500 символов). Если бы связный список содержал целые числа, а мы отказались бы от частого использования функции сравнения, то быстрее всех оказался бы алгоритм последовательного поиска.
Ниже приведена функция бинарного поиска для класса TtdSingleLinkList.
Листинг 4.10. Бинарный поиск в отсортированном однонаправленном связном списке
function TtdSingleLinkList.SortedFind(aItem : pointer;
aCompare : TtdCompareFunc) : boolean;
var
BLCursor : PslNode;
BLCursorIx : longint;
WorkCursor : PslNode;
WorkParent : PslNode;
WorkCursorIx : longint;
ListCount : longint;
MidPoint : longint;
i : integer;
CompareResult :integer;
begin
{подготовительные операции}
BLCursor := FHead;
BLCursorIx := -1;
ListCount := Count;
{пока в списке имеются узлы...}
while (ListCount <> 0) do begin
{вычислить положение средней точки; оно будет не менее 1}
MidPoint := (ListCount + 1) div 2;
{переместиться вперед до средней точки}
WorkCursor := BLCursor;
WorkCursorIx := BLCursorIx;
for i := 1 to MidPoint do begin
WorkParent := WorkCursor;
WorkCursor := WorkCursor^.slnNext;
inc(WorkCursorIx);
end;
{сравнить значение узла с искомым значением}
CompareResult := aCompare(WorkCursor^.slnData, aItem);
{если значение узла меньше искомого, уменьшить размер списка и повторить цикл}
if (CompareResult < 0) then begin
dec(ListCount, MidPoint);
BLCursor := WorkCursor;
BLCursorIx := WorkCursorIx;
end
{если значение узла больше искомого, уменьшить размер списка и повторить цикл}
else if (CompareResult > 0) then begin
ListCount := MidPoint - 1;
end
{в противном случае искомое значение найдено; установить реальный курсор на найденный узел}
else begin
FCursor := WorkCursor;
FParent := WorkParent;
FCursorIx := WorkCursorIx;
Result := true;
Exit;
end;
end;
Result := false;
end;
Функция бинарного поиска для класса TtdDoubleLinkList аналогична приведенной функции.
Вставка элемента в отсортированный контейнер
Если необходимо создать отсортированный массив или связный список, у нас существует выбор того или иного метода поддержания порядка элементов. Можно сначала вставлять элементы в контейнер, а затем их сортировать и сортировать содержимое контейнера при вставке каждого нового элемента, или же при выполнении вставки находить позицию, вставив новый элемент в которую контейнер останется отсортированным. Если предполагается, что контейнер будет часто использоваться в отсортированном виде, тогда имеет смысл при вставке сохранять правильный порядок элементов.
Читать дальшеИнтервал:
Закладка:

