Нейт Сильвер - Сигнал и шум. Почему одни прогнозы сбываются, а другие – нет

- Название:Сигнал и шум. Почему одни прогнозы сбываются, а другие – нет
- Автор:
- Жанр:
- Издательство:Array Литагент «Аттикус»
- Год:2015
- Город:Москва
- ISBN:978-5-389-09938-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нейт Сильвер - Сигнал и шум. Почему одни прогнозы сбываются, а другие – нет краткое содержание
О том, как этому научиться, рассказывает Нейт Сильвер, политический визионер и гуру статистики, разработавший систему прогнозов, позволившую дважды максимально точно предсказать результаты президентских выборов почти во всех штатах Америки. Его книга во многом близка исследованиям Нассима Талеба и столь же значима для всех, кто имеет дело с большими объемами данных и просчитывает различные варианты развития событий. И если Талеб говорит о законах зарождения «черных лебедей», Сильвер исследует модели и способы, позволяющие поймать этих птиц в расставленные нами сети. Он обобщает опыт экспертов-практиков, изучает различные модели и подходы, позволяющие делать более точные прогнозы. Как и Даниэль Канеман, автор бестселлера «Думай медленно… Решай быстро», наблюдая за поведением и мышлением людей, оценивающих неопределенные события, Сильвер утверждает: да, компьютеры незаменимы при работе с огромными массивами данных, но для максимальной точности результатов необходим гибкий человеческий ум и опыт, ведь прогнозирование – это планирование в условиях неопределенности.
Сигнал и шум. Почему одни прогнозы сбываются, а другие – нет - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
За пределами выборки – за пределами мышления, или Формула неудачного предсказания
Представьте себе, что вы – очень хороший водитель. Так о себе думают почти все водители {145}, но вы можете это доказать – за 30 лет водительского стажа (то есть совершив 20 тыс. поездок) вы пару раз легко наехали на бордюры.
Помимо этого, вы не злоупотребляете алкоголем и уж точно никогда не садитесь за руль пьяным. Однако как-то раз вы расслабляетесь на рождественской вечеринке в офисе. Не так давно умер ваш хороший друг, и вы находитесь в состоянии стресса. Один коктейль водка-тоник превращается в 12. Вы сильно пьяны. Что лучше сделать – поехать домой, сев за руль, или же вызвать такси?
Ответ кажется очевидным – взять такси. И отменить утреннюю встречу.
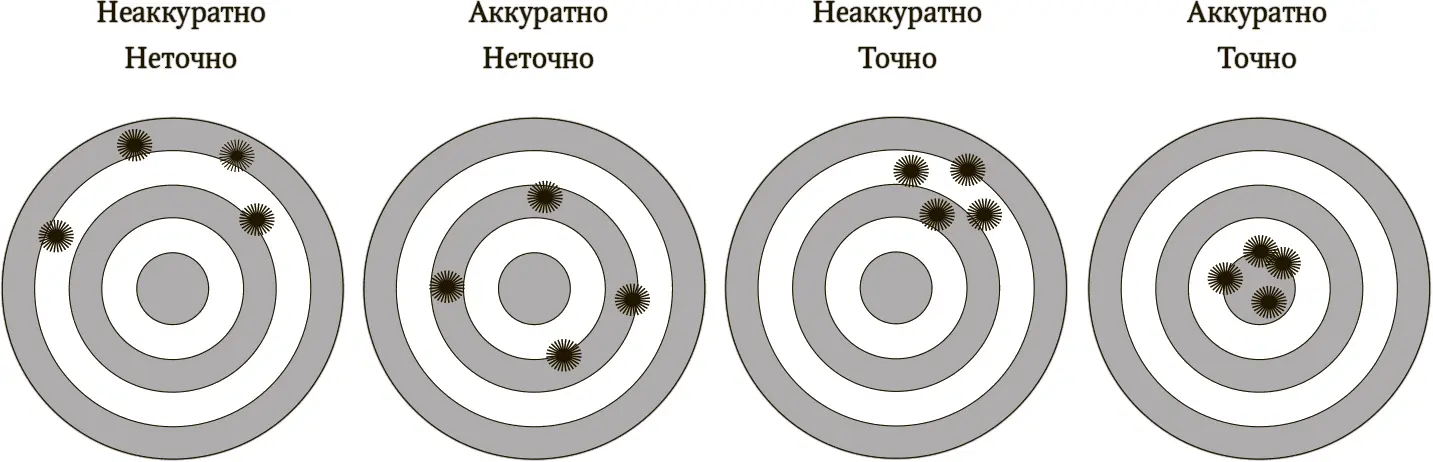
Рис. 1.6.Аккуратность и точность
Однако вы начинаете руководствоваться иной логикой. Прежде вы уже совершили 20 тыс. поездок, и лишь в двух из них произошли незначительные инциденты. Иными словами, вы спокойно добрались до места назначения в 19 998 случаях. Кажется, что все свидетельствует о том, что вы способны благополучно доехать до дома. А если у вас есть столь убедительные шансы на успех, зачем напрягать себя вызовом такси?
Разумеется, проблема состоит в том, что ни в одной из этих 20 тыс. поездок вы не находились в состоянии столь сильного опьянения. Размер вашей выборки для оценки успеха при вождении в нетрезвом состоянии равен не 20 тыс., а 0, и вы не сможете использовать свой прежний опыт для предсказания риска аварии в будущем. Это – типичный пример проблемы, связанной с ошибкой выборки.
Хотя может показаться, что избежать подобной ошибки легко, рейтинговые агентства ее допустили. Проделанный Moody’s расчет корреляции между различными ипотечными ценными бумагами на основании данных из прошлого был неверен – особенно принимая во внимание тот факт, что компания учитывала данные о ценах на жилье в США, начиная с 1980‑х гг. {146}. Однако в период с 1980‑х до середины 2000‑х гг. цены были стабильными или росли. В подобных обстоятельствах предположение о том, что закладная одного домовладельца мало связана с закладной другого, было достаточно точным. При этом ничто в данных из прошлого не могло показать, что произойдет, когда начнут снижаться цены на все дома. Коллапс на жилищном рынке оказался событием, находившимся за пределами выборки, поэтому созданная модель не могла применяться для оценки риска в этих условиях.
Ошибки, которые мы совершили, – и чему они учат
Разумеется, сотрудники Moody’s не были такими уж беспомощными. Они могли бы дать куда более правдоподобные оценки, расширив горизонт ви́дения. Соединенные Штаты никогда ранее не испытывали подобного краха на жилищном рынке – однако он происходил в других странах и приводил к плачевным результатам. Возможно, если бы экономисты Moody’s посмотрели, как изменились ставки в Японии после развития пузыря на рынке недвижимости, то смогли бы более реалистично представить себе всю опасность ценных бумаг, обеспеченных закладными, – и не дали бы им рейтинга AAA.
Однако большинство из тех, кто составляет прогнозы, как правило, избегает проблем, находящихся за пределами выборки. Расширяя выборку и включая в нее события, отделенные от нас пространством и временем, мы часто сталкиваемся с примерами того, что изучаемые связи выглядят совсем не так, как мы привыкли видеть. Наша собственная модель начинает казаться куда более слабой и смотрится уже куда менее впечатляюще при ее презентации (в статье в журнале или посте в блоге). Мы вынуждены признать, что знаем о мире значительно меньше, чем нам казалось. И наши личные и профессиональные стимулы почти всегда препятствуют подобному расширению выборки.
Мы забываем – или сознательно игнорируем – тот факт, что наши модели представляют собой упрощение мира. Мы считаем, что любая допускаемая нами ошибка будет находиться в разумных пределах. Однако в комплексных системах ошибки измеряются не в процентах, а в разах. S&P и Moody’s недооценили величину риска, связанного с CDO, в 200 раз. Экономисты считали, вероятность именно такой рецессии, которая произошла в реальности, составляла лишь 1 к 500.
Как я уже писал во введении, один из самых широко распространенных рисков, с которыми мы сталкиваемся в информационную эпоху, состоит в следующем: несмотря на увеличение объема знания в мире, разрыв между тем, что мы знаем, и тем, о чем мы думаем, что знаем, постоянно расширяется. Этот синдром часто связан с тем обстоятельством, что прогнозы, кажущиеся нам невероятно точными, на самом деле не являются таковыми. Moody’s провела расчеты с точностью до второго знака после запятой – однако они были невероятно далеки от реальности. Это все равно, что заявлять, что вы умеете хорошо стрелять, потому что ваши пули всегда оказываются в одних и тех же местах – хотя и невероятно далеко от центра мишени (рис. 1.6).
Финансовые кризисы, как и большинство других неудачных предсказаний, возникают как раз вследствие подобного фальшивого ощущения доверия. Аккуратные прогнозы притворяются точными, заставляя кое-кого из нас попасться на удочку и удвоить свои ставки. И в тот самый момент, когда нам кажется, что мы смогли преодолеть все основные недостатки своих суждений, ступор может наступить даже в такой сильной экономике, как американская.
Глава 2
Кто умнее: вы или «эксперты [20]» из телевизионных передач?
Для многих людей выражение «политический прогноз» практически стало синонимом телевизионной программы McLaughlin Group , политического круглого стола, транслируемого по воскресеньям с 1982 г. (и примерно с того же времени пародируемого в юмористическом шоу Saturday Night Live) . Ведет эту программу Джон Маклафлин, сварливый восьмидесятилетний человек, предпринимавший в 1970 г. неудачную попытку стать сенатором США. Он воспринимает политические прогнозы как своего рода спорт. В течение получаса в передаче обсуждаются четыре-пять тем, при этом сам Маклафлин настойчиво требует, чтобы участники программы отвечали на совершенно различные вопросы – от политики Австралии до перспектив поиска внеземного разума.
В конце каждого выпуска McLaughlin Group наступает время рубрики «Прогнозы», в которой каждому участнику дается несколько секунд, чтобы выразить мнение по тому или иному актуальному вопросу. Иногда они имеют возможность выбрать тему самостоятельно и поделиться своим мнением о чем-то, весьма далеком от политики. В других же случаях Маклафлин устраивает им своего рода неожиданный экзамен, на котором участники должны дать так называемые вынужденные прогнозы и ответить на один конкретный вопрос.
Читать дальшеИнтервал:
Закладка: