PC Magazine/RE - Журнал PC Magazine/RE №12/2009

- Название:Журнал PC Magazine/RE №12/2009
- Автор:
- Жанр:
- Издательство:ЗАО «СК Пресс»4cb82042-6c02-102c-b0cc-edc40df1930e
- Год:2009
- Город:Москва
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
PC Magazine/RE - Журнал PC Magazine/RE №12/2009 краткое содержание
Главный материал декабрьского номера, традиционный предновогодний обзор «советы Деду Морозу 2009», адресован самому широкому кругу читателей, озадаченных выбором приянного и полезного подарка.
Также в номере:
Системные платы: четырехъядерность на марше
Уже много лет этапы жизненного/рыночного цикла технологии можно кратко описать так: роскошь – насущная необходимость – устарело. Четырехъядерные процессоры пока находятся на первом этапе, хотя определенные признаки движения в сторону второго уже видны: если все равно назрела смена системы, то именно на такую, но переходить на нее «насильственно» пока рано. Если вы решаете, какую системную плату выбрать или просто хотите быть в курсе дела на этом рынке, ознакомьтесь с результатами сравнительного тестирования материнских плат в тестовой лаборатории PC Magazine/RE.
SQL Server 2008 R2: проекция на СМБ
Вряд ли найдется человек, который был бы специалистом по СУБД и одновременно не питал бы болезненного пристрастия к какой-либо фирме. Однако, на чьей стороне в этих религиозных войнах вы бы ни сражались, вы вряд ли станете спорить с тем, что Microsoft SQL Server наиболее адекватно вписывается в целостную инфраструктуру приложений. Так что в числе первых узнать, что нового предлагается в очередной версии, будет полезно каждому – если не для работы, то для аргументированного спора.
«Сервис и качество 2009»
Кратко охарактеризовать результаты кризиса для компьютерного рынка можно шуткой – «Все теперь хотят потратить меньше, а получить за свои деньги больше!». Людей, которые покупают «потому что это престижно» или даже «потому что модно», осталось совсем мало. Критерии оценки стали куда прагматичнее, чем два года назад. Так что вторая половина шутки – а что я получу за свои деньги? – это теперь очень серьезно. Итак, результаты ежегодного опроса читателей PC Magazine/RE.
Журнал PC Magazine/RE №12/2009 - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:

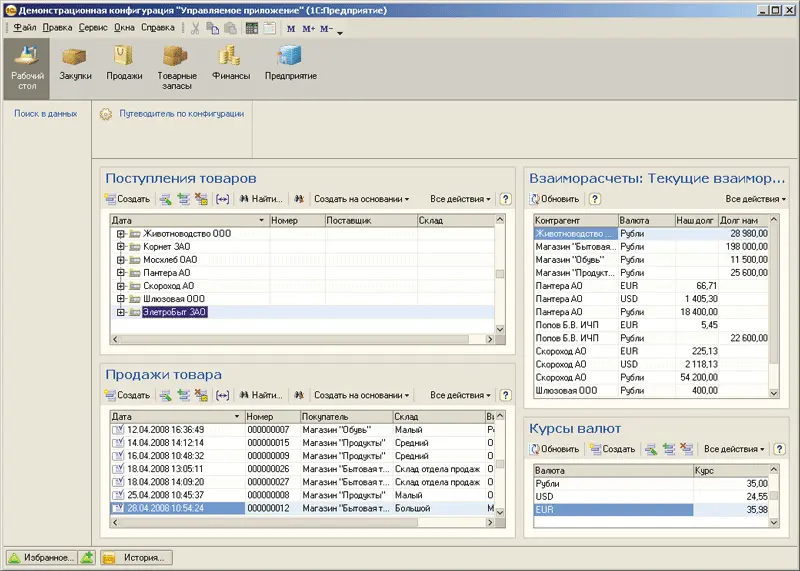
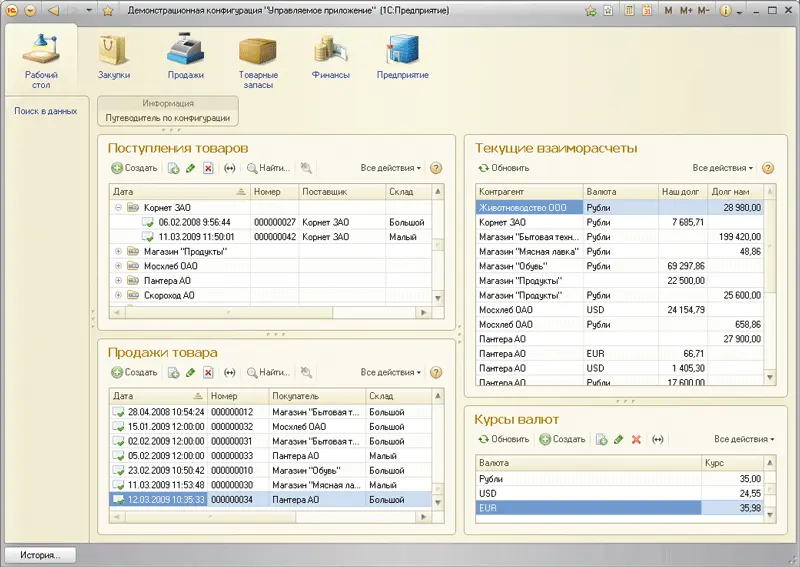
В предыдущих версиях «1С: Предприятия 8» кластер серверов мог располагаться на нескольких физических компьютерах, но один из этих компьютеров должен был играть роль центрального сервера, координирующего работу всего кластера. Такая архитектура накладывала ряд довольно существенных ограничений на работу кластера серверов «1С: Предприятия 8».
• Выход из строя центрального сервера приводил к разрыву всех клиентских соединений и полностью парализовывал любую работу с информационными базами, обслуживаемыми кластером.
• Плановое техническое обслуживание, например установка обновлений ОС с последующей перезагрузкой, требовало остановки работы пользователей со всеми информационными базами кластера.
• Все общие данные и все сервисные функции кластера (такие, как управление транзакционными блокировками, журналирование событий, полнотекстовый поиск, нумерация объектов, и т. п.) располагались в единственном процессе, могли создавать существенную нагрузку на центральный сервер, но не могли масштабироваться.
Модель клиент-серверного взаимодействия, реализованная в предыдущих версиях «1С: Предприятия 8», также обладала рядом особенностей работы клиентских приложений с кластером.
• Обрыв связи между клиентским приложением и рабочим процессом кластера приводил к аварийному завершению клиентского приложения.
• Отказ рабочего процесса кластера приводил к аварийному завершению всех клиентских приложений, которые обслуживались рабочим процессом.
• Не было возможности перераспределять клиентские соединения между рабочими процессами кластера – обслуживающий рабочий процесс назначался клиентскому соединению «пожизненно». Соответственно нельзя было и передать часть нагрузки с одного рабочего сервера на другой.
«1С: Предприятие 8.2» содержит ряд кардинальных улучшений архитектуры кластера серверов, призванных улучшить масштабируемость и отказоустойчивость информационных систем, построенных на этой технологической платформе.
Во-первых, «горячее» резервирование кластера серверов. У администратора информационной системы появилась возможность объединить несколько кластеров в группу резервирования. Обслуживанием пользователей занимается первый кластер из группы, а остальные поддерживают у себя в актуальном состоянии все важные данные первого кластера. В случае выхода из строя первого кластера, активным становится следующий кластер из группы резервирования. Для рабочих процессов, функционирующих внутри кластера, реализована другая схема – рабочие процессы подразделяются на активные и резервные. В случае плановой или аварийной остановки активного процесса кластер запускает один из резервных процессов и переводит на него имеющуюся нагрузку.
Практически это означает, что при грамотно спроектированной структуре кластера завершение любого из серверных процессов и даже отключение любого из физических компьютеров кластера не приведет к сбою в работе пользователей. Это особенно важно для тех информационных систем, которые работают в режиме «24×7» и остановка которых даже на короткое время может привести к серьезным финансовым потерям предприятия.
Во-вторых, масштабирование управляющих процессов (менеджеров) кластера. Общие данные и сервисные функции кластера теперь могут быть распределены между несколькими процессами-менеджерами, функционирующими на разных физических компьютерах. Эта позволяет существенно разгрузить главный менеджер кластера и переложить часть «сервисной» нагрузки на другие процессы.
В-третьих, новая модель клиент-серверного взаимодействия. Теперь платформа обладает устойчивостью к обрывам каналов связи между клиентом и сервером: в случае, если клиентское приложение не было завершено штатным образом, но перестало подавать признаки жизни, пользовательский сеанс продолжает поддерживаться на стороне сервера в течение довольно длительного времени (20 мин). Если за это время связь будет восстановлена, пользователь сможет продолжить работу с того самого места, где она была прервана.
Следует отметить, что устойчивостью к обрыву связи в любом случае обладают тонкий и Web-клиент, а в случае толстого клиента «воскрешение» пользовательского сеанса зависит главным образом от того, какая именно операция выполнялась клиентским приложением в момент обрыва связи. Некоторые операции (например, работа с транзакциями), к сожалению, требуют непрерывной связи между клиентом и сервером и не могут быть временно прерваны.
В-четвертых, динамическая балансировка нагрузки между рабочими процессами кластера. Кластер постоянно отслеживает загруженность своих рабочих процессов и вычисляет интегральную доступную производительность каждого процесса. Если доступная производительность разных процессов существенно различается, происходит переключение части пользовательских сеансов с более нагруженных процессов на менее нагруженные.
В предыдущих версиях «1С: Предприятия 8» анализ загруженности рабочих процессов тоже выполнялся, но только в момент возникновения нового клиентского соединения – кластер принимал решение, какому из рабочих процессов передать это соединение для обслуживания. Но на практике разные пользователи создают непропорциональную нагрузку на кластер – например, одни просто листают список документов, а другие формируют «тяжелые» отчеты. И при неблагоприятном стечении обстоятельств (несколько «тяжелых» пользователей попали в один рабочий процесс) возникали проблемы производительности информационной системы. Конечный пользователь вовсе не обязан знать о существовании рабочих процессов и тонкостях распределения нагрузки между ними, но на ситуацию «вдруг все стало тормозить» он обязательно отреагирует, причем реакция будет строго негативной.
Читать дальшеИнтервал:
Закладка: