Станислас Деан - Как мы учимся. Почему мозг учится лучше, чем любая машина… пока

- Название:Как мы учимся. Почему мозг учится лучше, чем любая машина… пока
- Автор:
- Жанр:
- Издательство:Эксмо
- Год:2021
- Город:Москва
- ISBN:978-5-04-113024-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Станислас Деан - Как мы учимся. Почему мозг учится лучше, чем любая машина… пока краткое содержание
В формате PDF A4 сохранен издательский макет.
Как мы учимся. Почему мозг учится лучше, чем любая машина… пока - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Немалую роль в процессе научения играет и веселье – еще одна эмоция, свойственная исключительно человеку. Мы смеемся, когда внезапно обнаруживаем, что одно из наших имплицитных предположений ошибочно, а значит, нам необходимо в корне пересмотреть имеющуюся ментальную модель. По мнению философа Дэна Деннетта, смех – это заразительная социальная реакция, возникающая всякий раз, когда мы привлекаем внимание друг друга к неожиданной информации 272. В самом деле, при прочих равных условиях смех в процессе научения, по-видимому, усиливает любопытство и содействует запоминанию 273.
Желание знать как источник мотивации
Многие психологи пытались выявить алгоритм, лежащий в основе человеческого любопытства. В самом деле, понимай мы его лучше, нам, возможно, удалось бы получить власть над этим важным компонентом механизма научения и даже воспроизвести его в машине, которая будет имитировать человека, эдаком любопытном роботе.
Алгоритмический подход уже приносит свои плоды. Величайшие психологи, от Уильяма Джеймса до Жана Пиаже и Дональда Хебба, задумывались о природе умственных операций, лежащих в основе любознательности. По их мнению, любопытство – это непосредственное проявление детского стремления к познанию мира и построению его модели 274. Любопытство возникает, как только наш мозг обнаруживает расхождение между тем, что мы уже знаем, и тем, что мы хотели бы знать, – т. е. потенциальную область научения. В любой заданный момент времени мы выбираем из различных доступных нам действий те, которые с наибольшей вероятностью позволят сократить пробел в знаниях и получить полезные сведения. Согласно этой точке зрения, любопытство напоминает кибернетическую систему, управляющую обучением, подобно регулятору Уатта, который, открывая или закрывая дроссельную заслонку на паровом двигателе, регулирует давление пара и поддерживает постоянную скорость. Любопытство – это регулятор мозга, задача которого – поддерживать постоянное давление научения и подталкивать нас к тому, чего мы пока не знаем, но могли бы узнать. Его противоположность – скука заставляет не только отворачиваться от того, что мы уже знаем, но и быстро терять интерес к области, которая, согласно нашему прошлому опыту, едва ли научит нас чему-то новому.
Данная теория объясняет, почему любопытство не связано со степенью неожиданности или новизны напрямую, а следует колоколообразной кривой 275. Мы не проявляем интереса к тому, что не вызывает удивления: вещи, которые мы видели тысячу раз, кажутся нам скучными. Равным образом нас не привлекают вещи, которые слишком новы и удивительны, а также вещи, которые настолько неоднозначны, что их структура остается за гранью нашего разумения, – сама их сложность отпугивает нас. Находясь посередине между скукой, вызванной излишней простотой, и отвращением к слишком сложному, любопытство естественным образом толкает нас к новым и доступным областям знаний. Однако степень их привлекательности постоянно меняется. По мере научения объекты, которые прежде казались интересными, теряют свое очарование, и мы перенаправляем внимание на новые явления. Вот почему младенцы поначалу проявляют такую страсть к самым тривиальным вещам: хватают пальцы ног, закрывают глаза, играют в «ку-ку»… Все для них ново; все является потенциальным источником научения. Однако стоит им выжать из этих экспериментов максимум знаний, как они теряют к ним всякий интерес – по той же самой причине, по которой ни один ученый не станет воспроизводить опыты Галилея: то, что уже известно, вызывает скуку.
Тот же алгоритм объясняет, почему иногда мы отворачиваемся от области, которая раньше представлялась привлекательной, но оказалась чересчур сложной. Наш мозг постоянно оценивает скорость научения; если он обнаруживает, что прогресс происходит недостаточно быстро, любопытство отключается. Все мы знаем детей, которые возвращаются с концерта с мечтой играть на скрипке, но через несколько недель отказываются от этой затеи, понимая, что овладение музыкальным инструментом дается нелегко. Те, кто продолжает играть, либо ставят перед собой более скромные задачи (например, с каждым днем играть все лучше и лучше), либо, если они действительно намерены стать профессиональными музыкантами, подпитывают стойкую мотивацию, с одной стороны – за счет родительской и социальной поддержки, а с другой – за счет постоянных напоминаний о конечной цели.
Два французских инженера, Фредерик Каплан и Пьер-Ив Удейе, создали любознательного робота 276. Их алгоритм включает в себя несколько модулей. Первый – это классическая искусственная самообучающаяся система, которая беспрерывно пытается предсказать состояние внешнего мира. Второй, более инновационный модуль оценивает работу первого: он измеряет скорость научения и использует ее для прогнозирования наименее изученных областей. Третий компонент – это схема подкрепления, обеспечивающая выбор действий, которые, как предполагается, приведут к более продуктивному научению. В результате система естественным образом сосредоточивается на тех областях, из которых можно извлечь максимум новых знаний. Последнее, согласно Каплану и Удейе, и есть само определение любознательности.
Если их любопытного робота посадить на детский коврик с игрушками, он ведет себя точно так же, как маленький ребенок. Несколько минут он занимается неким предметом: например, многократно поднимает ухо плюшевого слона. Как только он узнает все, что можно знать о предмете, его любопытство угасает. В какой-то момент робот отворачивается и активно ищет другой источник стимуляции. Через час он перестает исследовать коврик: наступает цифровая форма скуки – робот приходит к убеждению, что теперь ему известно все.
Аналогия с маленьким ребенком поразительна. Даже младенцы в возрасте нескольких месяцев поворачиваются в сторону стимулов средней сложности, структура которых подходит для быстрого усвоения. (Эта черта младенческого любопытства получила название «эффекта Златовласки» 277.) Отсюда вывод: чтобы максимизировать научение, мы должны постоянно обогащать детскую среду новыми объектами, которые стимулируют, но не обескураживают. Задача взрослых состоит в том, чтобы обеспечить ребенка тщательно продуманной педагогической системой, которая содействует его развитию, постоянно стимулируя стремление к знаниям и новизне.
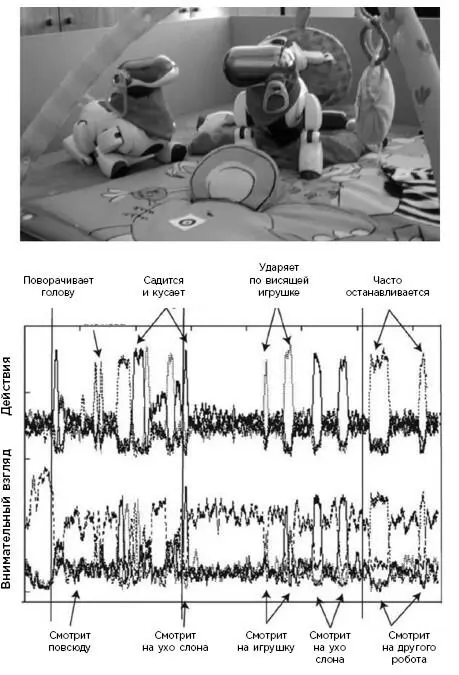
Любопытство – неотъемлемая составляющая нашего алгоритма научения, который мы только начинаем воспроизводить в машинах. Здесь маленький робот исследует игровой коврик. Любопытство реализуется через функцию подкрепления. Последняя содействует выбору того действия, которое максимизирует потенциал научения. Как следствие, робот последовательно пробует каждую игрушку на коврике и каждое действие, имеющееся в его распоряжении. Стоит ему овладеть одним аспектом мира, как он теряет к нему интерес и перенаправляет внимание на другой объект.
Читать дальшеИнтервал:
Закладка:




![Кэролайн Уилльямс - Мой продуктивный мозг [Как я проверила на себе лучшие методики саморазвития и что из этого вышло]](/books/1096012/kerolajn-uillyams-moj-produktivnyj-mozg-kak-ya-pro.webp)




